08-02 通过线性回归了解算法流程
通过线性回归带你了解算法流程
1. 1 线性回归引入

相信我们很多人可能都有去售楼处买房而无奈回家的行为,就算你没去过售楼处,相信你也应该听说过那令人叹而惊止的房价吧?对于高房价你没有想过这房价是怎么算出来的呢?难道就是房地产商拍拍脑门,北京的一概1000万,上海的一概800万,杭州的一概600万吗?看到这相信你应该有动力想要学好机器学习走向人生巅峰了。
其实仔细想想这房价大有来头,首先房价不可能只和地区有关,北京有1000万的房子,又会有800万、600万的房子,那这些房价不和地区有关还和什么有关呢?如果你真的买过房就知道,房子的价格首先和地区是有着比较大的联系的,北京五环外的房子可能都高于杭州任何地区的房子,在同一个地区内,房子的价格大多和房子的占地面积、户型、采光度等等因素有关系。
这个时候就有某位聪明的投机者想到了,我是不是可以找到一个方法来预测房价呢?如果这个房子的房价明显小于这所房子该有的房价(注:房价可能在某段时间由于某种不为人知的因素有小幅波动),就把那所买过来了,等房价涨回去了再卖出去,这样看起来也是生财之道。(注:纯属虚构)
可是如果去预测房价呢?上面讲到了房价和房子所在地区\(x_1\)、占地面积\(x_2\)、户型\(x_3\)和采光度\(x_4\)有关,那么我是不是可以把这些因素假想成房子的特征,然后给这些每个特征都加上一个相应的权重\(\omega\),既可以得到如下的决策函数
其中\(b\)可以理解为偏差,你也可以想成房子的这些特征再差也可能会有一个底价。
基于上述给出房价的决策函数,我们就可以对一个某个不知名的房子输入它的这些特征,然后就可以得到这所房子的预测价格了。
理想总是美好的,即一条生财之道就在眼前,但是我们如何去得到这个决策函数呢?我们可以得到这个特征值,但是这个\(\omega\)怎么得到呢?这就是我们的线性回归需要解决的问题,下面让我们一起走向这条生财之道吧!
1. 2 决策函数
你可以简单的认为线性回归就是找到一条曲线去拟合所有样本点,上面提及买房的问题有四个特征,因此我们得到的决策函数为
对于\(n\)个特征的线性回归模型,你可能需要找到一条曲线,也可以说成是一个决策函数
拟合所有样本点。其中\(b\)为未知参数偏置(bias);\(\theta\)为未知参数向量\([\theta_1,\theta_2,\cdots,\theta_n]\);\(X\)为样本在各个特征上的特征值,用向量表示为\([x_1,x_2,\cdots,x_n]\);\(\theta^T\)为向量\(\theta\)的转置
;
如果你对矩阵运算不熟悉,牢记\(f_\theta(X)=\theta_1x_1+\theta_2x_2+\cdots+\theta_nx_n+b=\theta^TX+b\)即可。
如果把未知参数\(b\)看成\(\theta_0\),曲线为
其中\(x_0=1\)。
虽然其他机器学习算法的决策函数不一定是线性回归的\(f_\theta(X)=\theta^T{X}\),但是决策函数中一般都会有一个未知参数\(\theta\),以后对于所有的机器学习算法都会逐一讲解为什么会有这个参数。
1. 3 损失函数
# 损失函数图例
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.datasets.samples_generator import make_regression
%matplotlib inline
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
# 生成随机数据
# X为样本特征,y为样本输出,coef为回归系数,共100个样本,5个噪声,每个样本1个特征,数据集随机种子为1
X, y, coef = make_regression(
n_samples=100, n_features=1, noise=50, coef=True, random_state=1)
# 散点图+直线
plt.scatter(X, y, color='g', s=50, label='房子信息')
plt.plot(X, X*coef, color='r', linewidth=2)
plt.xlabel('房子面积', fontproperties=font, fontsize=15)
plt.ylabel('房价', fontproperties=font, fontsize=15)
plt.title('房子面积-房价', fontproperties=font, fontsize=20)
# 去掉x,y轴尺度
plt.xticks(())
plt.yticks(())
plt.legend(prop=font)
plt.show()
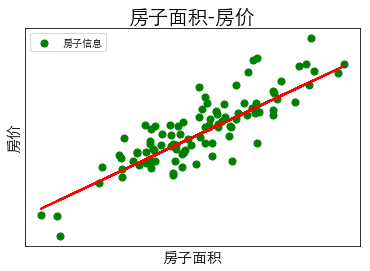
如上图所示,上图假设每一个绿点表示一所房子的信息,红色的直线为我们通过某种方法得到一个决策函数\(\hat{Y}=f_\theta(X)=\theta^T{X}+b=\theta_1x+b\)。对于监督模型中的通过房子面积预测房价例子,我们是假设已知\(\theta_1=10,b=0\)。
但是如果你眼力劲还不错,你可能会发现我们的这个决策函数并没有完全经过这些数据点,也可以说是没有完全拟合这些数据点。一般我们的决策函数都是无法经过所有点的,你要知道机器学习是不可能做到预言的,而只能做到预测,预言有时候都会不准确,更别说预测了,也就是说机器学习对新数据的预测是有误差的。通常我们使用一个损失函数(loss function)或代价函数(cost function)度量模型预测错误的程度
其中\(Y\)为样本的真实值,\(\hat{Y}\)为样本的预测值。
四种常用的损失函数:
- 平方损失函数(quadratic loss function)
- 绝对值损失函数(absolute loss fuction)
- 0-1损失函数(0-1 loss function)
- 对数损失函数(logarithmic loss function)或对数似然损失函数(log-likelihood loss function)
1. 4 目标函数
损失函数一般是对某个样本损失的计算,但是我们的模型很明显不是由一个样本生成的,而是由一组样本生成的。由于\(X\)和\(Y\)我们可以通过数据获得,但是未知参数\(\theta\)是未知的,因此我们在这里给出关于\(\theta\)的目标函数(objective function),即所有样本的误差加和取平均
其中\(m\)是样本总数,\(\sum_{i=1}^m L(y_i,f_{\theta_i}(x_i))= L(y_1,f_{\theta_1}(x_1))+L(y_2,f_{\theta_2}(x_2))+\cdots+L(y_m,f_{\theta_m}(x_m))\)
1. 5 目标函数最小化
假设我们得到了目标函数,那么我们接下来要干什么呢?目标函数是所有样本的误差加和取平均,那么是不是这个误差越小越好呢?对,你暂时可以这样想,误差越小,则我们的预测值会越来越接近真实值,接下来我们就是需要最小化目标函数,由于目标函数在统计学中被称为经验风险(empirical risk),所以有时候也会最小化目标函数也会被称为经验风险最小化(empirical risk minimization)。
其中\(\min{J(\theta)}\)表示最小化\(J(\theta)\)函数。
通过线性回归举例,由于\(f_{\theta}(X)=\theta^TX\),则它的损失函数是
它的目标函数是
假设上述目标函数使用了平方损失函数,则目标函数变成
最小化目标函数为
其中\(\{x_1,x_2,\cdots,x_m\}\)、\(\{y_1,y_2,\cdots,y_m\}\)、\(m\)都是已知的,即我们可以把他们看成一个常数。
如果我们考虑一个极端情况,即假设\(x_i=1,\,(i=1,2,\cdots,m)\)、\(y_i=2,\,(y=1,2,\cdots,m)\)、\(m=100\)、\(\theta_1=\theta_2=\cdots=\theta_m=\theta_j\),则最小化目标函数变为
# 目标函数最小化图例
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 生成一个数组(-4.98,-4.96,...,4.98,5)
theta_j = np.arange(-5, 5, 0.02)
# 构造J_theta曲线
J_theta_j = (2-theta_j)**2
# 描绘曲线
plt.plot(theta_j, J_theta_j, color='r', linewidth=2)
plt.xlabel('$θ$', fontproperties=font, fontsize=15)
plt.ylabel('$min{J(θ)}$', fontproperties=font, fontsize=15)
plt.title('$\min{J(θ)}=(2-θ_j*1)^2$', fontproperties=font, fontsize=20)
plt.show()
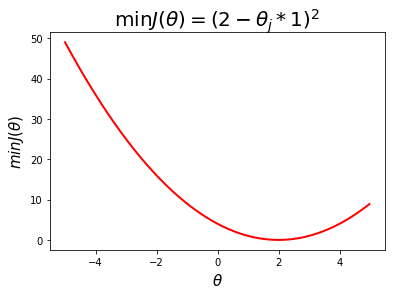
上图即我们假设的目标函数的图像,从上图可以看出,如果要最小化目标函数则需要找到能使目标函数最小化的参数向量\(\theta\),通过公式可以表示为
其中\(\underbrace{arg\,\min}_\theta{J(\theta)}\)表示找到能使\(J(\theta)\)最小化的参数向量\(\theta\)。
由于这里只介绍目标函和目标函数最小化问题,怎么找能使得目标函数最小化的\(\theta\)不在此处介绍范围,以后会详细介绍。相信你对目标函数的构造、目标函数最小化(目标函数优化问题)有了一个明确的认知,至于目标函数中埋下的几处伏笔,以后都会详细介绍,目前的你只需要了解这个流程,以后我们会通过具体的机器学习算法来再一次解释这个过程。并且以后你会发现其实我们接下来要介绍的所有机器学习算法都是基于这个流程,所以你会反复再反复接触这个流程,如果现在能有个明确的认知很好,如果不可以等把这个流程与某个机器学习算法联系在一起的时候相信你能理解他。
1. 6 过拟合
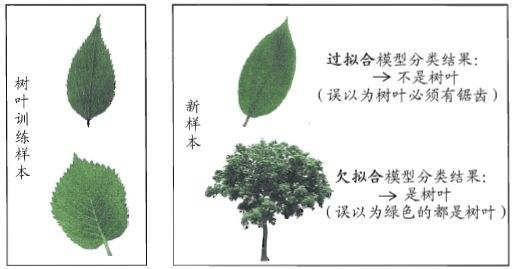
在这里我必须得明确告诉你,理论上模型可能是越小越好,但是在工业上模型并不是误差越小越好。你可以这样想想,假设我们有一个数据集,这个数据集难道不会有噪音(noise)或噪声吗?首先我可以很明确的告诉你,一般的工业上的数据都会有噪声,如果我们的模型经过了包括噪声的所有样本点,也就是说模型对我们的训练集做到了完美拟合,这就是我们常说的过拟合(over-fitting),并且过拟合时模型也会变得相对复杂。
产生噪声的原因:
- 训练数据的标签错误,即A类的数据标记为B类;B类的数据标记为A类
- 输入数据某一维特征值不准确的,下图所示的红点
# 过拟合图例
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
font = FontProperties(fname='/Library/Fonts/Heiti.ttc')
%matplotlib inline
# 自定义数据并处理数据
data_frame = {'x': [2, 1.5, 3, 3.2, 4.22, 5.2, 6, 6.7],
'y': [0.5, 3.5, 5.5, 5.2, 5.5, 5.7, 5.5, 6.25]}
df = pd.DataFrame(data_frame)
X, y = df.iloc[:, 0].values.reshape(-1, 1), df.iloc[:, 1].values.reshape(-1, 1)
# 线性回归
lr = LinearRegression()
lr.fit(X, y)
def poly_lr(degree):
"""多项式回归"""
poly = PolynomialFeatures(degree=degree)
X_poly = poly.fit_transform(X)
lr_poly = LinearRegression()
lr_poly.fit(X_poly, y)
y_pred_poly = lr_poly.predict(X_poly)
return y_pred_poly
def plot_lr():
"""对线性回归生成的图线画图"""
plt.scatter(X, y, c='k', edgecolors='white', s=50)
plt.plot(X, lr.predict(X), color='r', label='lr')
# 噪声
plt.scatter(2, 0.5, c='r')
plt.text(2, 0.5, s='$(2,0.5)$')
plt.xlim(0, 7)
plt.ylim(0, 8)
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
def plot_poly(degree, color):
"""对多项式回归生成的图线画图"""
plt.scatter(X, y, c='k', edgecolors='white', s=50)
plt.plot(X, poly_lr(degree), color=color, label='m={}'.format(degree))
# 噪声
plt.scatter(2, 0.5, c='r')
plt.text(2, 0.5, s='$(2,0.5)$')
plt.xlim(0, 7)
plt.ylim(0, 8)
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
def run():
plt.figure()
plt.subplot(231)
plt.title('图1(线性回归)', fontproperties=font, color='r', fontsize=12)
plot_lr()
plt.subplot(232)
plt.title('图2(一阶多项式回归)', fontproperties=font, color='r', fontsize=12)
plot_poly(1, 'orange')
plt.subplot(233)
plt.title('图3(三阶多项式回归)', fontproperties=font, color='r', fontsize=12)
plot_poly(3, 'gold')
plt.subplot(234)
plt.title('图4(五阶多项式回归)', fontproperties=font, color='r', fontsize=12)
plot_poly(5, 'green')
plt.subplot(235)
plt.title('图5(七阶多项式回归)', fontproperties=font, color='r', fontsize=12)
plot_poly(7, 'blue')
plt.subplot(236)
plt.title('图6(十阶多项式回归)', fontproperties=font, color='r', fontsize=12)
plot_poly(10, 'violet')
plt.show()
run()
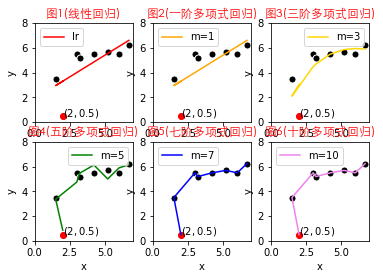
如上图所示每张图都有相同分布的8个样本点,红点明显是一个噪声点,接下来将讲解上述8张图。暂时不用太关心线性回归和多项式回归是什么,这两个以后你都会学习到,此处引用只是为了方便举例。
- 图1:线性回归拟合样本点,可以发现样本点距离拟合曲线很远,这个时候一般称作欠拟合(underfitting)
- 图2:一阶多项式回归拟合样本点,等同于线性回归
- 图3:三阶多项式回归拟合样本点,表现还不错
- 图4:五阶多项式回归拟合样本点,明显过拟合
- 图5:七阶多项式回归拟合样本点,已经拟合了所有的样本点,毋庸置疑的过拟合
- 图7:十阶多项式回归拟合样本点,拟合样本点的曲线和七阶多项式已经没有了区别,可以想象十阶之后的曲线也类似于七阶多项式的拟合曲线
从上图可以看出,过拟合模型将会变得复杂,对于线性回归而言,它可能需要更高阶的多项式去拟合样本点,对于其他机器学习算法,也是如此。这个时候你也可以想象,过拟合虽然对拟合的样本点的误差接近0,但是对于未来新数据而言,如果新数据的\(x=2\),如果使用过拟合的曲线进行拟合新数据,那么会给出\(y=0.5\)的预测值,也就是说把噪声的值给了新数据,这样明显是不合理的。
1. 7 正则化
上面给大家介绍了机器学习中避不开的一个话题,即模型很有可能出现过拟合现象,出现了问题就应该解决,我讲讲机器学习中最常用的解决过拟合问题的方法——正则化(regularization)。给目标函数加上正则化项(regularizer)或惩罚项(penalty term),即新的目标函数变成
其中\(\lambda\geq0\)为超参数,类似于参数,但是参数可以通过算法求解,超参数需要人工手动调整;\(\lambda(R(f))\)为正则化项。
这个时候你可能在想为什么加上正则化项就可以解决过拟合问题呢?对于线性回归而言,由于涉及线性回归、梯度下降法、最小角回归法等概念,此处不多赘述,讲线性回归时会详细讲述。下面将通过线性回归中正则化的两种形式L1正则化和L2正则化做简单解释。
1. 7.1 L1正则化
L1正则化(Lasso)是在目标函数上加上L1正则化项,即新的目标函数为
其中\(||\theta||_1\)为参数向量\(\theta\)的1范数。
假设样本有\(n\)特征,则\(\theta\)为\(n\)维向量,1范数为
1. 7.2 L2正则化
L2正则化(Ridge)是在目标函数上加上L2正则化项,即新的目标函数为
其中\(||\theta||_2^2\)为参数向量\(\theta\)的2范数的平方。
假设样本有\(n\)特征,则\(\theta\)为\(n\)维向量,2范数为
多说一嘴,假设样本有\(n\)特征,则\(\theta\)为\(n\)维向量,p范数为
1. 8 训练集、验证集、测试集
通常情况下我们不会使用数据集中的所有数据作为训练数据训练模型,而是会按照某种比例,将数据集中的数据随机分成训练集、验证集、测试集学得一个较优模型,如可以把数据集按照7:2:1的比例分成训练集、验证集、测试集,对于不同的问题一般分配的比例不同,下面将介绍这三者各自的作用。
1. 8.1 训练集
一般情况下我们都会使用带有正则项的目标函数去构建模型,即我们的目标函数为
一般会通过训练集得到参数\(\theta\)。如线性回归的目标函数中有两个参数\(\theta\)和\(b\),一般会通过训练集得到这两个参数\(\theta\)和\(b\)。
1. 8.2 验证集
一般情况下我们都会使用带有正则项的目标函数去构建模型,即我们的目标函数为
一般会通过给定一组超参数,然后通过验证集得到最优超参数\(\lambda\),有时候会把验证集得到超参数的步骤划分到训练集中。如线性回归的目标函数有一个超参数\(\lambda\),一般会通过验证集得到该超参数\(\lambda\)。
1. 8.3 测试集
测试集一般被当做未来新数据集,然后通过度量模型性能的工具测试模型的误差大小。
1. 9 本章小结
本章主要通过线性回归介绍了决策函数、四种损失函数、目标函数及目标函数的问题,其实其他的机器学习算法也是这样的套路,在在一部分算法原理时我们会细讲,此处你有一个大概的概念即可。
最小化目标函数我们假设误差越小越好,然而工业上数据总是会有噪声,也就是说\(0\)误差也许并不是最好的,因此引出了我们的过拟合问题,之后讲解了解决过拟合问题的两个方法,一个是在目标函数上加上正则化项,另一个则把训练集分成训练集、验证集和测试集。


{kind=link}