03-01 K-Means聚类算法
K-Means聚类算法
K-means聚类算法属于无监督学习算法,它实现简单并且聚类效果优良,所以在工业界也被广泛应用。同时K-Means聚类算法也有大量的变体,本文将从最传统的K-Means聚类算法讲起,让后在其基础上讲解K-Means聚类算法的变体,其中它的变体包括初始化优化K-Means++、距离计算优化elkan K-Means和大数据情况下的优化Mini Batch K-Means算法。
K-Means聚类算法学习目标
- K-Means聚类算法原理以及它的优缺点
- K-Means初始化优化之K-Means++算法
- K-Means距离计算优化之elkan K-Means算法
- 大数据优化之Mini Batch K-Means算法
- K-Means聚类算法和KNN(k近邻算法)的区别
K-Means聚类算法详解
K-Means聚类算法原理
K-Means的思想非常简单,对于给定的样本集,按照样本集之间的距离大小,将样本集分成K个簇。需要注意的是:每个簇之间的点尽量相近,而簇与簇之间的距离尽量较大。
假设目前有k个簇分别为\(\{C_1,C_2,\cdots,C_k\}\),在这里我们使用均方误差度量簇内点与点的误差,即误差定义为:
其中\(\mu_i\)是簇\(C_i\)的均值向量,有时有称为质心,表达式为:
对于上式,它是一个NP难的问题(计算量非常大的问题),因此求上式的最小值只能采用启发式的迭代方法。
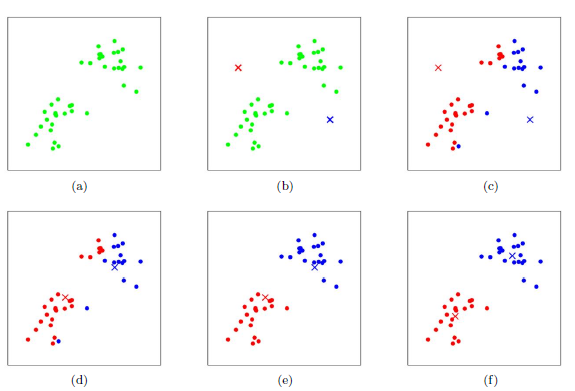
上图a表示初始的数据集,假设k=2,即我们要分成对上述数据集分成两个簇。首先我们需要随机选择两个k类所对应的类别质心,即图b中的红点和蓝点;然后分别计算样本中所有点到这两个质心的距离,同时标记每个样本的类别为该样本距离最小的质心的类别,此时我们得到第一轮迭代后的类别,如图c所示;对于已经被标记为两个不同的类别,我们计算这两个类别的新的质心,如图d所示;然后我们重复图c和图d的过程,将所有点的类别标记为距离最近的质心的类并求新的质心,最终算法将会收敛至图f。
K-Means聚类算法和KNN
相同点:
- K-Means聚类算法和KNN(K近邻算法)都是找到离某一个点最近的点,即两者都使用了最近领的思想
不同点:
- K-Means聚类算法是无监督学习算法,没有样本输出;KNN是监督学习算法,有对应的类别输出
- K-Means在迭代的过程中找到K个类别的最佳质心,从而决定K个簇类别;KNN则是找到训练集中离某个点最近的K个点
传统的K-Means聚类算法流程
对于传统的K-Means聚类算法,我们需要注意以下两点:
- 我们需要注意K-Means聚类算法的K值的选择,一般我们会根据对数据的先验经验选择一个合适的K,即可以通过专家的经验进行选择;如果没有先验知识,我们可以通过交叉验证的方法选择一个合适的K值。
- 确定K值,即质心的个数之后。我们需要确定这个K个质心的位置,因为这K个质心的位置对最后的聚类结果和运行时间都有一定的影响,因此需要选择合适的K个质心,一般情况下这K个质心不要太近。
输入
样本集\(D=\{x_1,x_2,\cdots,x_m\}\),聚类簇的个数k,最大迭代次数N。
输出
簇划分\(C=\{C_1,C_2,\cdots,C_k\}\)。
流程
- 从数据集D中随机选择k个样本作为初始的k个质心向量:\(\{\mu_1,\mu_2,\cdots,\mu_k\}\)
- 对于\(n=1,2,\cdots,N\),对以下步骤循环
- 将簇划分初始化为\(C_t=\emptyset{,}\,t=1,2,\cdots,k\)
- 对于\(i=1,2,\cdots,m\),计算样本\(x_i\)和各个质心向量\(\mu_j,\,j=1,2,\cdots,k\)的距离:\(d_{ij}=||x_i-\mu_j||_2^2\),将\(x_i\)标记最小的为\(d_{ij}\)所对应的类别\(\lambda_i\)。此时更新\(C_{\lambda{i}}=C_{\lambda{i}}\bigcup\{x_i\}\)
- 对于\(j=1,2,\cdots,k\)对\(C_j\)中所有的样本点重新计算新的质心\(\mu_j=\frac{1}{C_j}\sum_{x\in{C_j}}x\)
- 如果所有的k个质心向量都没有发生变化,则停止循环
- 输出簇划分\(C=\{C_1,C_2,\cdots,C_k\}\)
K-Means初始化优化之K-Means++
对于传统的K-Means聚类算法,它的k个质心是我们随机选择的,但是在前文讲到质心的位置对最后的聚类结果和运行时间有着很大的影响。因此如果我们完全随机的选择质心,很有可能会导致酸奶发收敛很慢。K-Means++算法就是对K-Means随机初始化质心方法的优化。
K-Means++算法初始化质心的策略如下:
- 从输入的数据集中随机选择一个点作为聚类中心\(\mu_r\)
- 对于数据集中的每一个点\(x_i\),计算它与已选择的聚类中心最近聚类中心的距离,\(D(x_i)=argmin||x_i-\mu_r||_2^2,\,r=1,2,\cdots,k_{selected}\)
- 选择一个新的数据点作为新的聚类中心,选择的原则为:对于\(x_i\)而言,\(D(x_i)\)越大的点,则\(\mu_r\)被选取作为\(x_i\)聚类中心的概率则越大
- 重复步骤2和3直到选出K个聚类质心
- 利用这K个质心作为初始化质心去运行传统的K-Means聚类算法

K-Means距离计算优化之elkan K-Means
对于传统的K-Means聚类算法,在每轮迭代中,我们需要计算所有的样本点到所有质心的距离,这样运行时间会过长。elkan K-Means算法则是对这一步进行改进,减少不必要的距离的计算。它主要的使用的思想是:利用两边之和大于等于第三边,两边之差小于第三边的三角形的性质,因此达到减少距离计算的目的。以下则是elkan K-Means算法利用的两个规则:
- 对于一个样本点x和两个质心\(\mu_{j_1},\mu_{j_2}\)。如果我们先计算出这两个质心的距离\(D(j_1,j_2)\),如果计算发现\(2D(x,j_1)\leq{D(j_1,j_2)}\),我们就可以知道\(D(x,j_1),\leq{D(x,j_2)}\)。此时我们则不需要再计算\(D(x,j_2)\),即省了一步距离的计算。
- 对于一个样本点x和两个质心\(\mu_{j_1},\mu_{j_2}\),我们可以得到\(D(x,j_2)\geq\max\{0,D(x,j_1)-D(j_1,j_2)\}\)。
利用上述的两个规则,可以一定程度上提升传统K-Means聚类算法的迭代速度。但是如果样本的特征是稀疏的,并具有缺失值,由于有些距离无法计算,则无法使用该算法。
大数据优化之Mini Batch K-Means
对于传统的K-Means算法,在每轮迭代中,我们需要计算所有的样本点到所有质心的距离,即使用优化后的elkan K-Means算法,计算开销也是非常大的。尤其是现在这个大数据的时代。因此Mini Batch K-Means算法应运而生。
Mini Batch让人很容联想到的就是随机梯度下降法。其实就是如此,Mini Batch,就是用样本集中的一部分样本来做传统的K-Means,这样可以避免大数据时代下计算开销大的问题,算法的收敛速度也会大大加快。当然,此时算法的精确度也会有小幅的降低,这就需要我们对不同的问题进行不同的衡量了,也就是说我们需要去考虑是要较高的精确度,还是需要较小的计算开销。
有时候为了提高Mini Batch K-Means算法的精确度,我们会多跑几次Mini Batch K-Means算法,使用不同的无放回的随机采样得到的样本集得到聚类簇,最后选择最优的聚类簇。
K-Means聚类算法优缺点
优点
- 简单易懂,算法收敛速度快
- 算法的可解释性强
缺点
- k值的选取一般需要先验经验(专家经验)
- 采用迭代的方法,得到的结果只是局部最优
- 由于需要计算质心到所有点的距离,对噪音和异常点比较敏感
- 如果各隐含类别的数据量严重失衡,或者个各隐含类别的方差不同,则聚类效果不佳
小结
本文主要和大家介绍了无监督学习中的K-Means聚类算法,它的原理简单易懂,并且代码上容易实现,由于属于无监督学习,在工业中一般作为中间算法。例如微博中的好友关系分类,其次就是一种分簇的体现。
介绍了传统的K-Means聚类算法之后,对于传统K-Means聚类算法在质心选择上的缺陷,我们介绍了它的优化算法——K-Means++算法,由于每一轮迭代,我们都需要计算质心到所有样本点的距离,因此我们也介绍了相应的两种优化算法——elkan K-Means算法和Mini Batch K-Means算法。当然,这些都只是理论。对于聚类算法,其实特征设计很有必要,特征的设计可以参考特征工程部分。



{kind=link}