NLP大模型涉浅
自然语言处理(NLP)作为人工智能的皇冠上的明珠,一直吸引着众多研究者的目光。随着深度学习技术的发展,NLP领域迎来了新的春天。从词汇表征到复杂的神经网络模型,再到预训练语言模型的微调,深度学习为NLP提供了强大的工具和方法。
词汇表征:NLP的基石
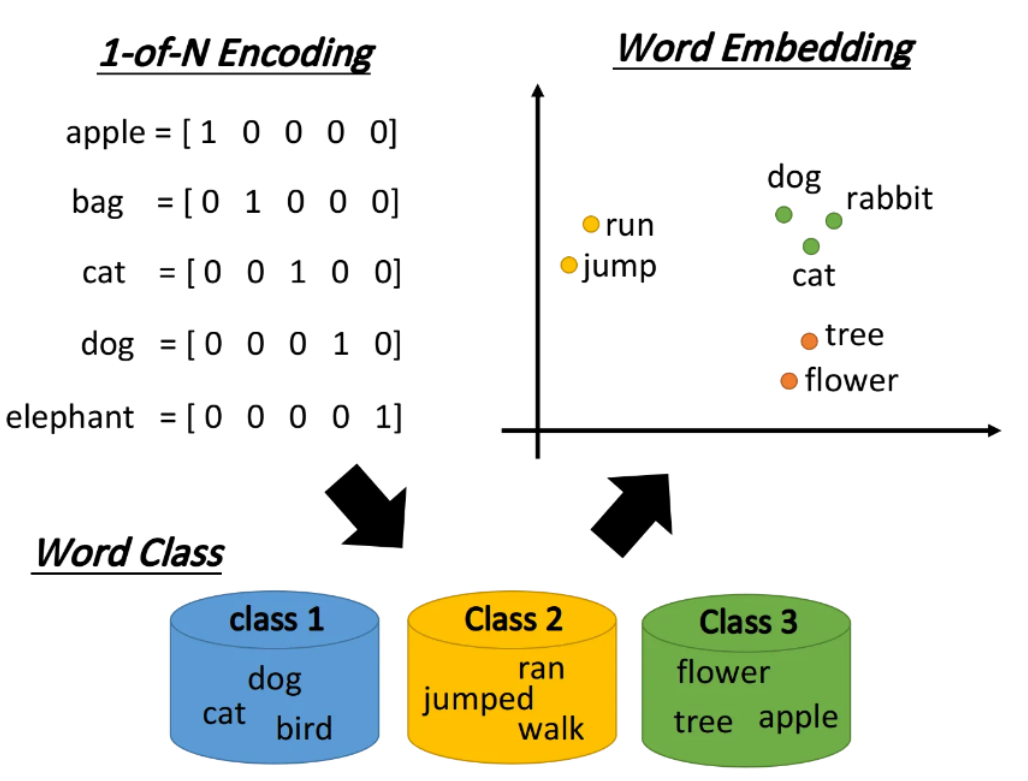
在NLP中,词汇表征是将词语转换为计算机可处理形式的过程。传统的one-hot编码虽然简单,但存在维数灾难和无法表达词间相似性的问题。为了解决这些问题,词嵌入技术应运而生。
Word Embedding
词嵌入技术,如word2vec,通过训练神经网络模型,将词汇转换为密集的向量形式。word2vec包含两种模型:
-
CBOW模型:根据上下文预测目标词。
![]()
-
Skip-gram模型:根据目标词预测上下文词。
![]()

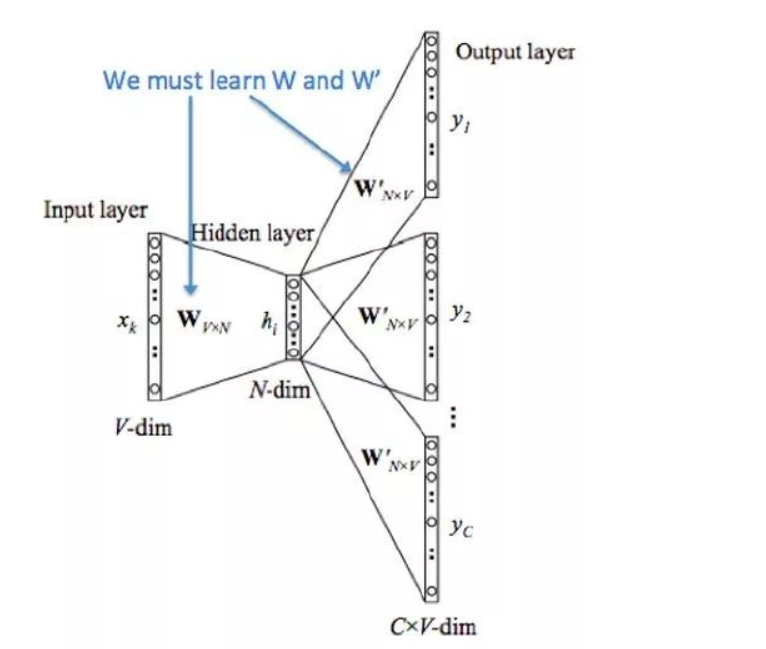
word2vec的Python实现示例
from gensim.models import Word2Vec
# 假设sentences是我们的文本数据集
sentences = [['this', 'is', 'the', 'first', 'sentence'],
['this', 'is', 'the', 'second', 'sentence']]
# 训练word2vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取单词的词向量
vector = model.wv['first']
循环神经网络:序列建模的利器
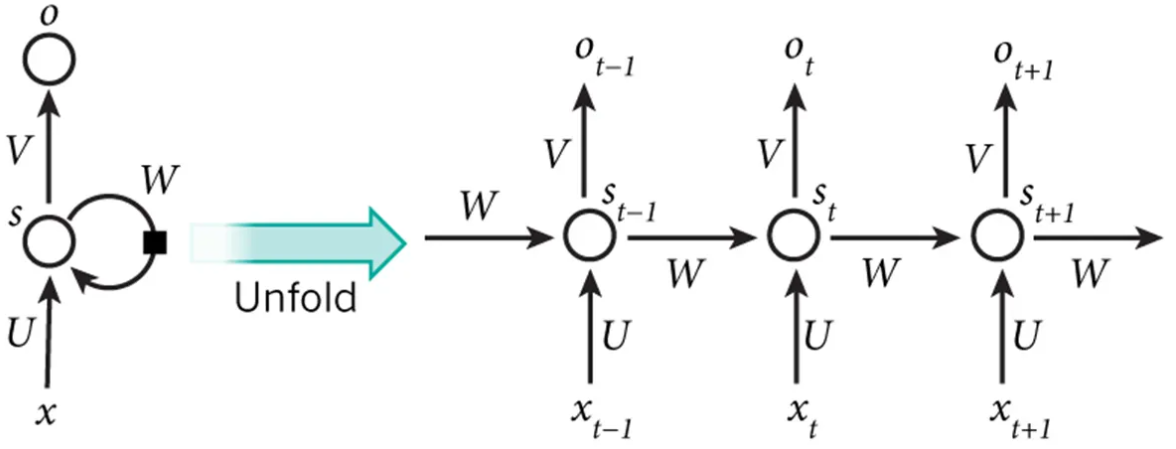
循环神经网络(RNN)通过引入循环机制,能够处理序列数据。RNN的变体,如LSTM和GRU,通过门控机制解决了长序列训练中的梯度消失问题。
LSTM网络

LSTM包含三个门:遗忘门、输入门和输出门,它们共同控制信息的流动。
LSTM的Python实现示例
from keras.models import Sequential
from keras.layers import LSTM, Dense
# 构建一个LSTM模型
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(timesteps, features)))
model.add(Dense(num_classes, activation='softmax'))
# 编译和训练模型
model.compile(loss='categorical_crossentropy', optimizer='adam')
model.fit(x_train, y_train, epochs=10, batch_size=32)
Seq2Seq与注意力机制:机器翻译的双剑
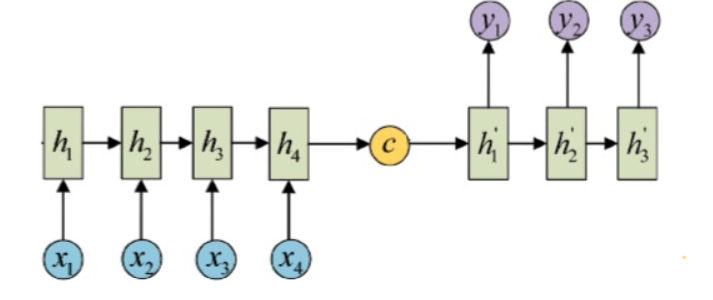
Seq2Seq模型通过编码器-解码器框架处理不等长的序列转换任务。引入注意力机制后,模型能够更加关注输入序列中与当前输出最相关的部分。
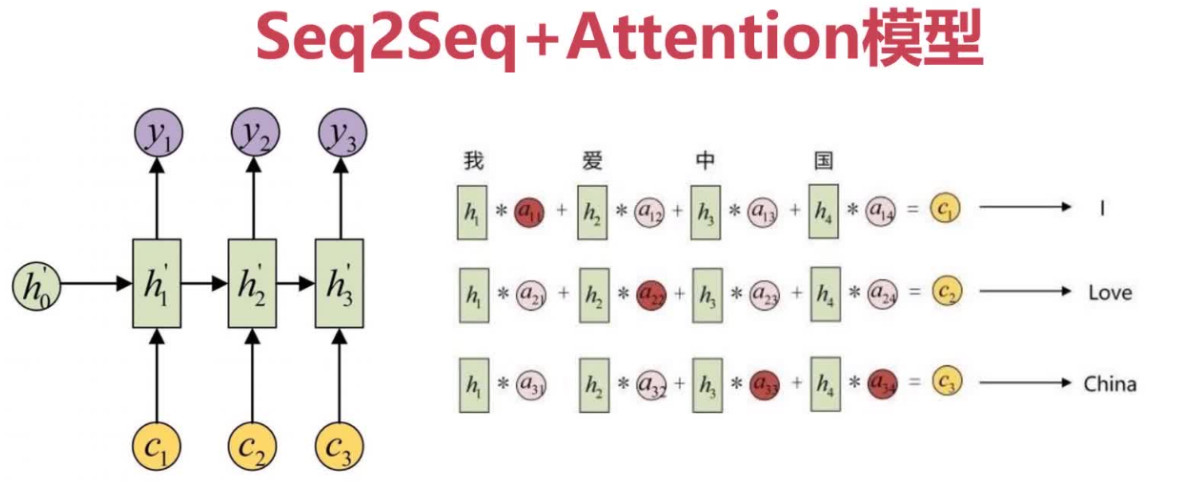
Seq2Seq+Attention的Python实现示例
from keras.layers import Embedding, LSTM, Dense, Attention
# 定义Seq2Seq模型
encoder_inputs = Input(shape=(None,))
encoder = LSTM(256, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
decoder_inputs = Input(shape=(None,))
decoder_lstm = LSTM(256, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=[state_h, state_c])
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
Transformer:自注意力的胜利
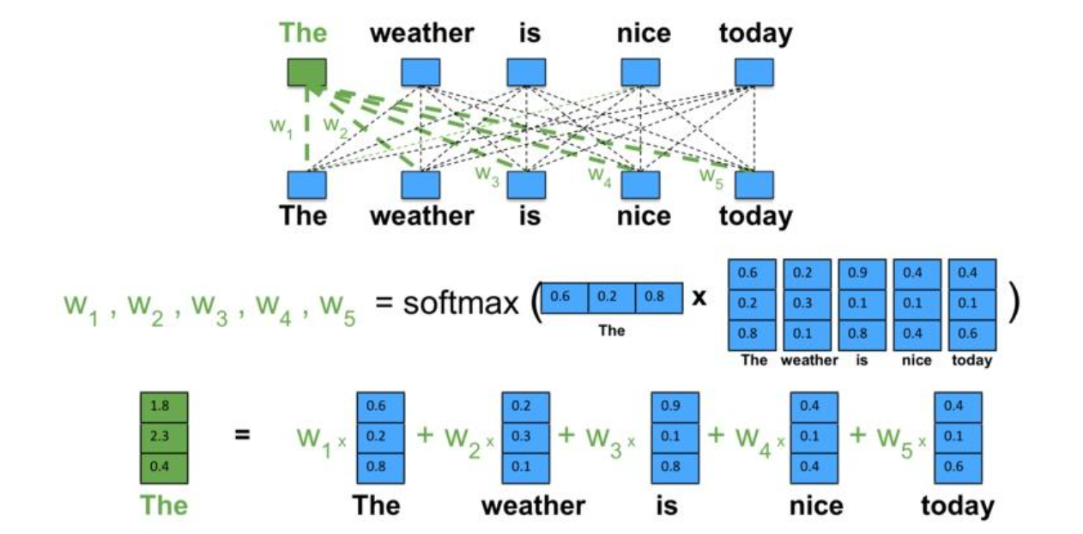
Transformer模型通过自注意力机制,有效处理序列数据,无需依赖RNN的逐步处理方法。
Transformer模型的Python实现示例
from transformers import TransformerModel, TransformerEncoder, TransformerEncoderLayer
encoder_layer = TransformerEncoderLayer(num_heads=8, d_model=512)
encoder = TransformerEncoder(encoder_layer, num_layers=6)
inputs = tf.random.uniform((10, 32, 512)) # (batch_size, seq_length, d_model)
outputs = encoder(inputs)
预训练与微调:大型语言模型的个性化
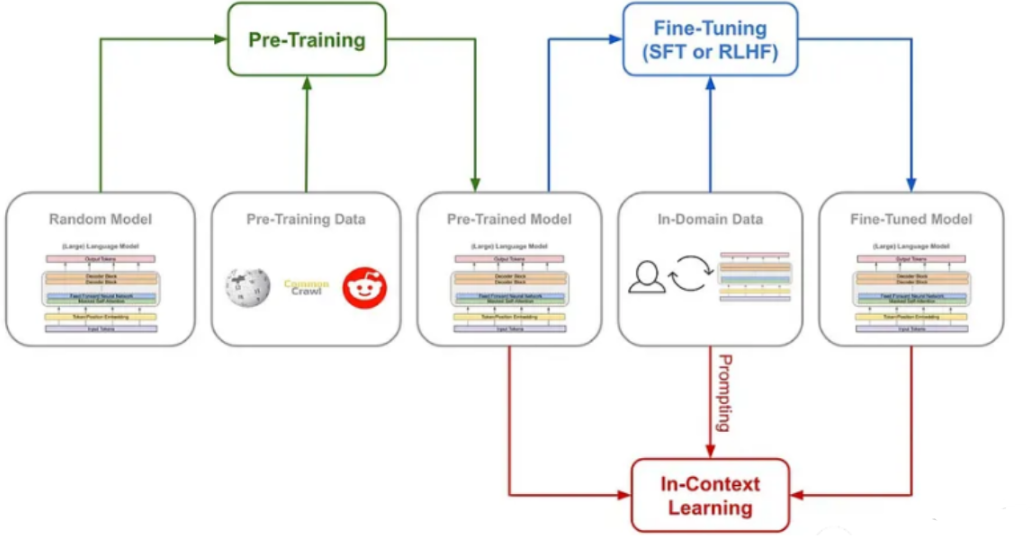
预训练和微调是提高模型在特定任务上性能的重要手段。通过在大量无标签数据上预训练,模型能够学习到丰富的语言特征和模式。
微调预训练模型的Python实现示例
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 加载预训练模型和分词器
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# 微调模型
model.train()
for epoch in range(num_epochs):
for step, batch in enumerate(train_dataloader):
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 在测试集上评估模型
eval_results = model.evaluate(test_dataloader)
深度学习为NLP领域带来了革命性的变化。从词向量的生成到复杂的神经网络模型,再到预训练和微调策略,见证了技术的进步和应用的广泛性。随着研究的深入,深度学习将在NLP领域发挥更大的作用,推动人工智能的发展。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号