Apache Spark 安装和基础使用
Spark 概述
大数据总体开发架构:
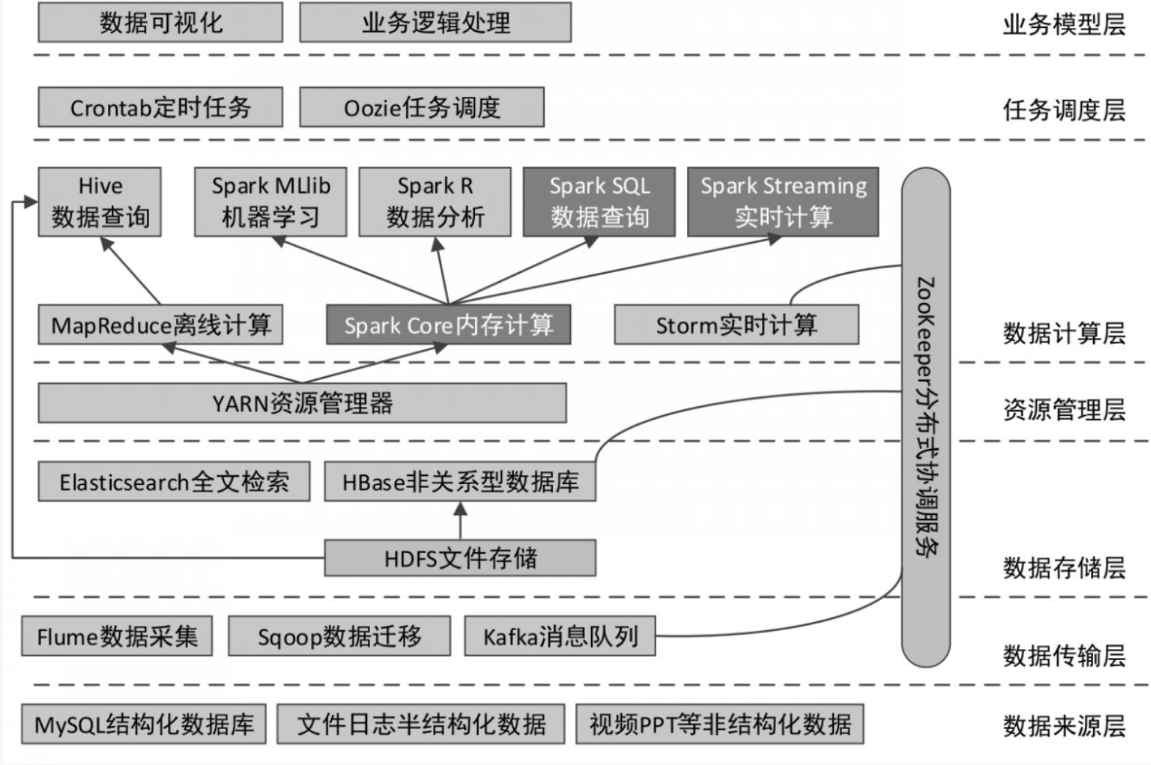
Apache Spark 是一个开源的集群计算框架,以其快速、易用、通用和高度可扩展性而著称。Spark 支持多种编程语言,包括 Java、Scala、Python 和 R,并提供了丰富的库,如 Spark SQL、MLlib、GraphX 和 Spark Streaming。
Spark 的主要特点
- 快速:Spark 通过在内存中存储中间数据,显著提高了数据处理速度。
- 易用:Spark 提供了简洁的 API,简化了复杂数据处理任务的实现。
- 通用:Spark 拥有多个库,支持不同类型的数据处理和分析任务。
- 到处运行:Spark 可以在多种集群管理器上运行,如 Hadoop YARN、Mesos 等。
Spark 的主要组件
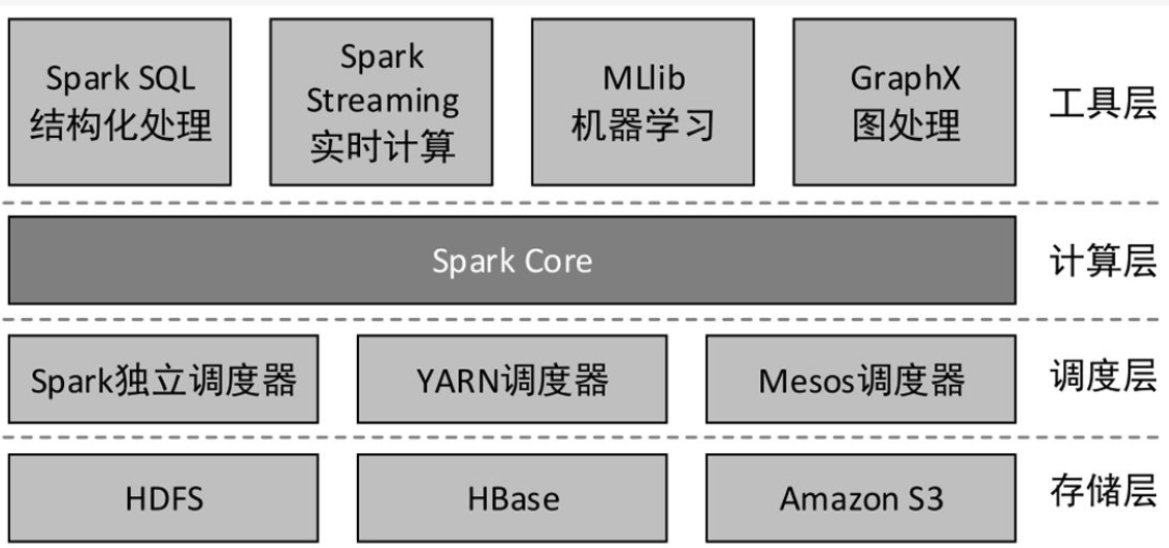
Spark 由多个组件构成,包括:
- Spark Core:Spark 的核心计算引擎,负责任务的调度和分发。
- Spark SQL:用于结构化数据处理的库,支持 SQL 查询。
- MLlib:机器学习库,提供常用的机器学习算法。
- GraphX:图处理库,支持图的并行计算。
- Spark Streaming:实时数据流处理库。
Spark 的安装与配置
安装 Spark 涉及以下步骤:
- 下载 Spark 并解压。
- 在
/etc/profile文件中配置环境变量SPARK_HOME和PATH。 - 执行
source /etc/profile使配置生效。
RDD 算子
RDD(弹性分布式数据集)是 Spark 的核心抽象。Spark 提供了多种 RDD 算子,包括:
转化算子
- map():对 RDD 的每个元素应用函数,返回新的 RDD。
- filter():根据条件过滤 RDD 中的元素。
- flatMap():类似于 map,但每个输入可以被映射为多个输出。
- reduceByKey():将具有相同 key 的 value 聚合起来。
- groupByKey():将具有相同 key 的元素分组。
行动算子
行动算子触发实际的计算过程:
- collect():返回 RDD 的所有元素。
- count():统计 RDD 中的元素数量。
- take():取出RDD的前 n 个元素。
示例代码
val sc = new SparkContext(new SparkConf().setAppName("RDD Example"))
// 创建 RDD
val rdd = sc.parallelize(Array(1, 2, 3, 4))
// 使用 map 算子
val rdd2 = rdd.map(x => x * 2)
// 使用 filter 算子
val rdd3 = rdd2.filter(x => x > 3)
// 使用 collect 行动算子
val results = rdd3.collect()
println(results.mkString(", "))
RDD 的创建
RDD 可以从对象集合或外部存储系统中创建:
从对象集合创建 RDD
val rddFromList = sc.parallelize(List(1, 2, 3, 4))
从外部存储创建 RDD
val rddFromTextFile = sc.textFile("path/to/textfile.txt")
Spark 运行模式
Spark 支持多种运行模式:
- 本地模式:适用于开发和测试。
- Spark Standalone 模式:使用 Spark 自带的资源调度器。
- Spark On YARN 模式:使用 YARN 作为资源管理器。
Spark Standalone 模式的搭建
- 配置
spark-env.sh文件。 - 使用
start-all.sh脚本启动 Spark 集群。
Spark On YARN 模式的搭建
- 配置
spark-env.sh文件,指定 Hadoop 相关属性。 - 使用
spark-submit提交应用程序到 YARN。
Spark Standalone架构
Spark Standalone的两种提交方式
Spark Standalone模式为经典的Master/Slave架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用--deploy-mode参数指定提交方式。
- client提交方式
当提交方式为client时,运行架构如下图所示:
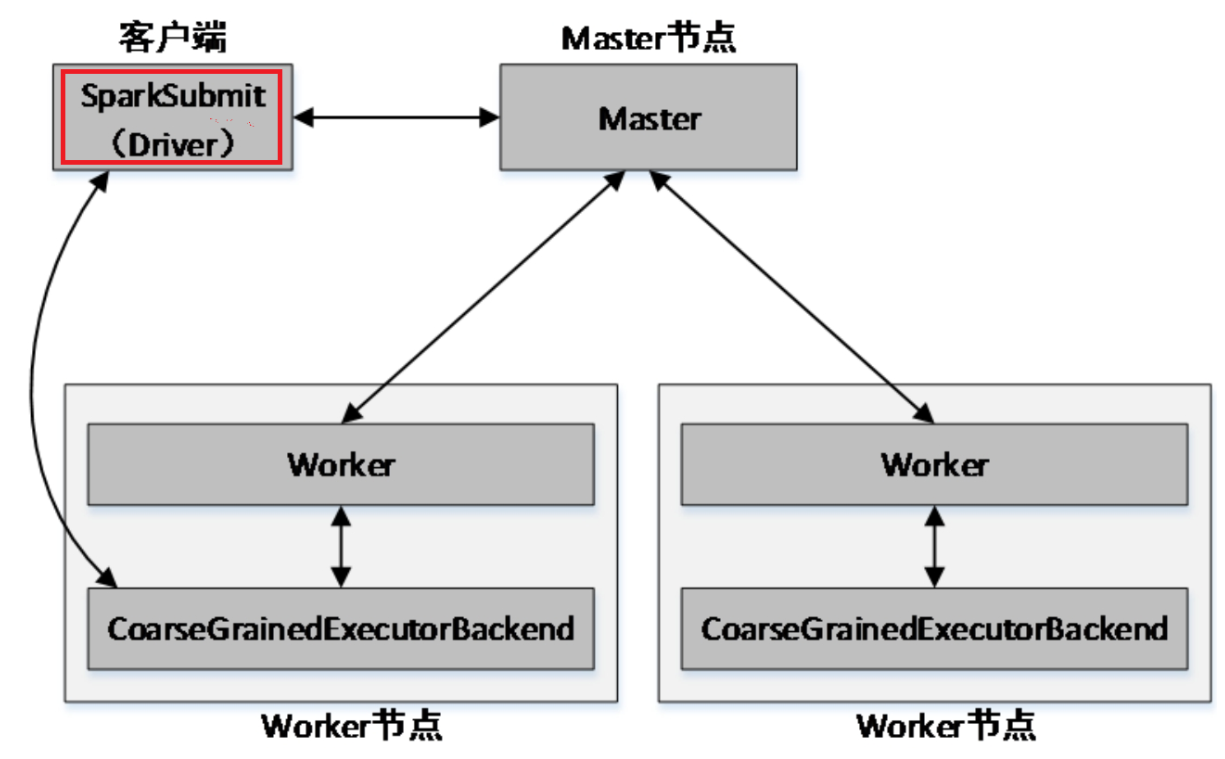
Spark Standalone模式架构(client提交方式)
集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程。
Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。如图所示的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。
- cluster提交方式
当提交方式为cluster时,运行架构如下图所示:

Spark Standalone模式架构(cluster提交方式)
Standalone以cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker启动一个名为DriverWrapper的子进程,该子进程即为Driver进程。
示例:提交 Spark 应用程序
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
/export/servers/spark/examples/jars/spark-examples_2.12-3.3.3.jar
Apache Spark 是一个功能强大、灵活且易于使用的大数据处理框架。随着技术的不断发展,Spark 将继续在大数据处理领域发挥重要作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号