Spark SQL与Hive的整合
在大数据时代,处理和分析海量数据集的能力变得至关重要。Apache Spark和Hive作为两个强大的数据处理工具,在数据仓库和分析领域有着广泛的应用。本文将探讨如何将Spark SQL与Hive整合,以及如何利用这一整合来提高数据处理的效率和灵活性。
Spark SQL简介
Spark SQL是Apache Spark的一个组件,它为结构化数据提供了处理接口。与传统的MapReduce相比,Spark SQL提供了更高级的抽象,如DataFrame和Dataset,它们使得数据操作更加直观和高效。Spark SQL支持多种数据源,包括但不限于Hive、Parquet、ORC、JSON和JDBC等。
DataFrame和Dataset
DataFrame是Spark SQL中类似于关系型数据库表的分布式数据集合,它具有Schema信息,可以看作是带有强类型标签的RDD。而Dataset则是Spark 1.6中引入的,提供了强类型支持,并且是DataFrame的进一步抽象。
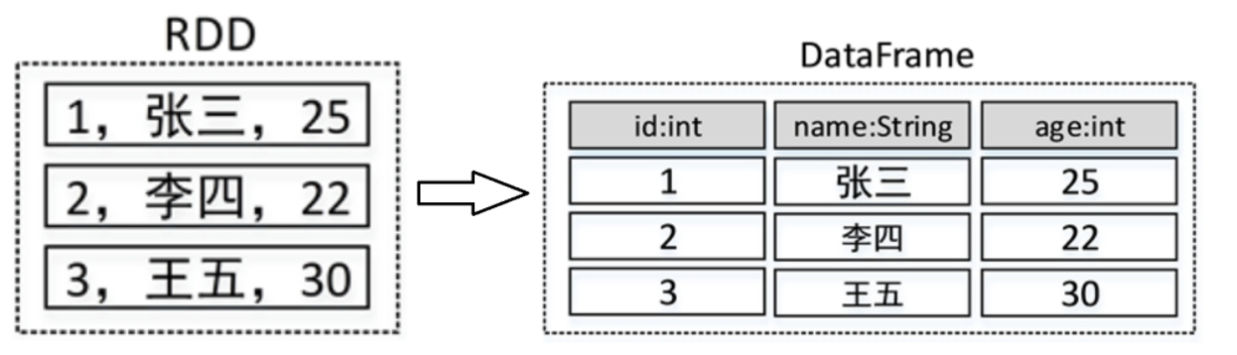

Spark SQL的基本使用
使用Spark SQL的基本步骤包括启动Spark Shell,创建SparkSession实例,加载数据,转换数据,执行SQL查询等。以下是一个使用Spark SQL对HDFS中的数据文件进行排序的示例:
val spark = SparkSession.builder().appName("DataSorting").getOrCreate()
val d1 = spark.read.textFile("hdfs://192.168.121.131:9000/input/person.txt")
d1.show()
case class Person(id: Int, name: String, age: Int)
val personDataset = d1.map(line => {
val fields = line.split(",")
Person(fields(0).toInt, fields(1), fields(2).toInt)
})
personDataset.show()
val pdf = personDataset.toDF()
pdf.createTempView("v_person")
val result = spark.sql("select * from v_person order by age desc")
result.show()
Spark SQL与Hive的整合
Hive作为一个数据仓库工具,它允许使用HiveQL来管理和分析存储在Hadoop集群中的数据。Spark SQL与Hive整合后,可以在Spark SQL中直接使用HiveQL,从而利用Spark的计算能力来加速HiveQL的执行。
整合步骤
- 配置环境:将Hive的配置文件
hive-site.xml复制到Spark的配置目录,并添加必要的属性。 - 指定Hadoop配置:在
spark-env.sh中指定Hadoop的安装目录和配置文件目录。 - 添加MySQL驱动:将MySQL的JAR包复制到Spark的
jars目录下。
操作Hive的几种方式
- Spark SQL终端操作:直接使用
spark-sql命令进入终端,以HiveQL的方式操作。 - Spark Shell操作:使用
spark-shell进入Shell,通过spark.sql("HiveQL语句")执行HiveQL。 - 提交Spark SQL应用程序:编写应用程序,打包为JAR,然后使用
spark-submit提交到Spark集群。
示例代码
以下是使用Spark SQL操作Hive的一个示例:
import org.apache.spark.sql.SparkSession
object SparkSQLHiveDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Spark Hive Demo")
.enableHiveSupport()
.getOrCreate()
spark.sql("CREATE TABLE IF NOT EXISTS students(id INT, name STRING, age INT)")
spark.sql("""
LOAD DATA LOCAL INPATH '/root/data/students.txt'
INTO TABLE students
""")
spark.sql("SELECT * FROM students").show()
}
}
自定义函数和开窗函数
Spark SQL提供了丰富的内置函数,同时也支持用户自定义函数(UDF),以满足特定的数据处理需求。此外,开窗函数允许在聚合操作中保留原始数据行,非常有用于需要分组和排序的场景。
自定义函数示例
以下是一个自定义函数,用于隐藏手机号码中间的四位数字:
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions.lit
import org.apache.spark.sql.DataFrame
val maskPhone: UserDefinedFunction = udf((phone: String) => {
val masked = phone.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2")
lit(masked)
})
val df = spark.read.json("path_to_json_file")
df.withColumn("maskedPhone", maskPhone(col("phone"))).show()
窗口函数示例
使用row_number()函数为每个分组添加行号:
import org.apache.spark.sql.expressions.Window
val windowSpec = Window.partitionBy("category").orderBy("sales", "desc")
df.withColumn("row_num", row_number().over(windowSpec)).show()
我们可以看到Spark SQL与Hive整合的强大能力。这种整合不仅简化了数据处理流程,还提高了数据处理的性能。无论是通过Spark SQL终端、Spark Shell还是提交应用程序的方式,Spark SQL都提供了一个高效且灵活的方式来处理和分析大规模数据集。随着技术的不断发展,我们有理由相信Spark SQL和Hive的整合将在未来的数据处理领域发挥更大的作用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号