
数据仓库Hive
Apache Hive 安装、配置与基本操作指南
Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以将结构化数据文件映射为一张表,并提供类 SQL 查询功能。本文将结合两篇详细的技术文档,介绍 Hive 的安装、配置以及基本操作。
一、Hive 的安装与配置
Hive架构
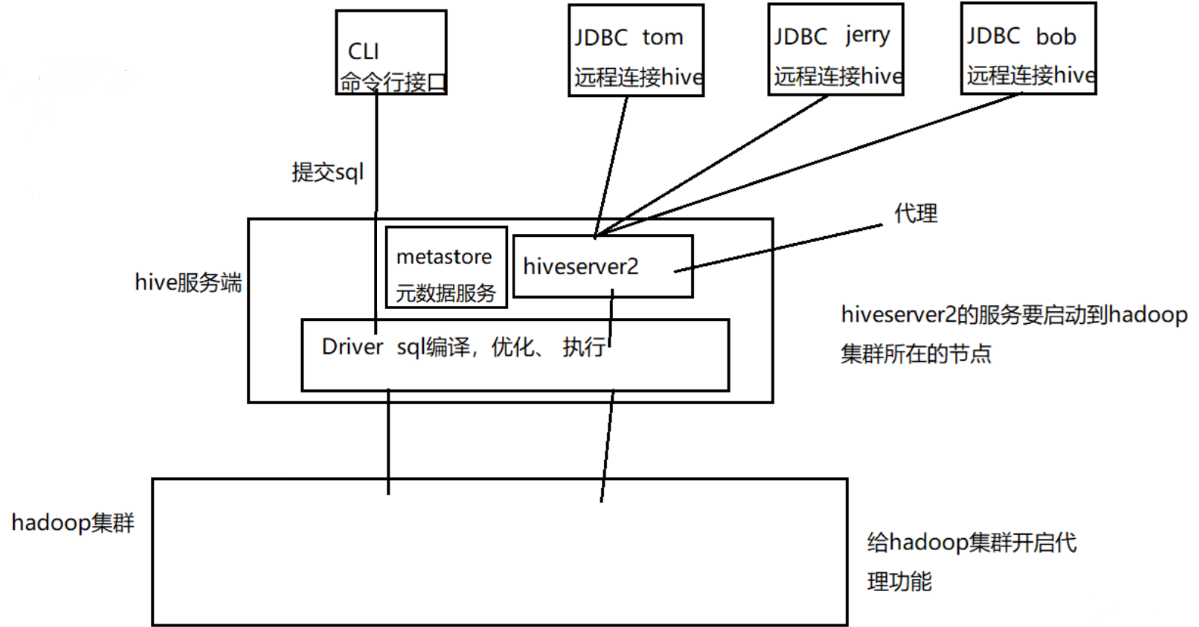
1. 环境准备
在安装 Hive 之前,需要确保 Hadoop 已经安装并运行正常。Hive 依赖 Hadoop 生态系统,因此 Hadoop 的配置和运行环境至关重要。
2. 安装 Hive
- 下载 Hive 安装包:
wget https://downloads.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz - 解压安装包:
tar -zxvf apache-hive-3.1.2-bin.tar.gz - 将解压后的目录移动到指定目录,例如
/usr/local/hive:mv apache-hive-3.1.2-bin /usr/local/hive
3. 配置 Hive
-
配置环境变量:
编辑~/.bashrc文件,添加以下内容:export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin然后执行
source ~/.bashrc使配置生效。 -
配置 Hive 元存储(Metastore):
Hive 使用元存储来保存数据库和表的元数据。默认情况下,Hive 使用嵌入式 Derby 数据库。为了生产环境的稳定性,建议配置 MySQL 或 PostgreSQL 作为元存储。
在conf/hive-site.xml文件中添加以下内容:<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>hivepassword</value> <description>password to use against metastore database</description> </property>
4. 启动 Hive
执行以下命令启动 Hive CLI:
hive
在 CLI 中可以执行 HiveQL 命令来创建数据库和表,以及执行查询操作。
二、Hive 基本操作
1. 创建数据库和表
-
创建数据库:
CREATE DATABASE mydatabase; -
切换到新创建的数据库:
USE mydatabase; -
创建表:
CREATE TABLE mytable ( id INT, name STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
2. 加载数据
将本地文件系统或 HDFS 上的数据加载到表中:
LOAD DATA LOCAL INPATH '/path/to/local/file' INTO TABLE mytable;
3. 查询数据
使用 HiveQL 进行数据查询:
SELECT * FROM mytable;
4. 数据导出
将查询结果导出到本地文件系统:
INSERT OVERWRITE LOCAL DIRECTORY '/path/to/output/dir'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
SELECT * FROM mytable;
5. 修改表结构
-
添加列:
ALTER TABLE mytable ADD COLUMNS (age INT); -
修改列类型:
ALTER TABLE mytable CHANGE name name STRING;
Hive 作为大数据处理的利器,具备强大的数据仓库功能和灵活的查询能力,是处理海量数据的得力助手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号