
基于MapReduce实现的手机流量统计项目
项目概述:
需求:统计每个手机号上行流量和、下行流量和、总的流量和(上行流量和+下行流量和),
将统计结果按照手机号的前缀进行区分,并输出到不同的输出文件中去
13* ==> ..
15* ==>..
other ==>..
提供数据文件如下:
access.log
第二个字段:手机号
倒数第三字段:上行流量
倒数第二字段:下行流量
Access.java
手机号、上行流量、下行流量、总流量
思路:
既然要求和:根据手机号进行分组,然后把该手机号对应的上下流量加起来
Mapper:把手机号、上行流量、下行流量 拆开
把手机号作为key,把Access作为value写出去
Reducer:(13736238888,<Access,Access>)
项目结构: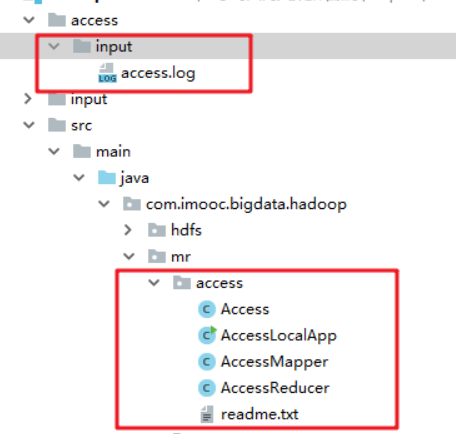
具体实现:
1.自定义复杂数据类型
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
/**
* 自定义复杂数据类型
*1)按照Hadoop的规范,需要实现Writable接口
*2)按照Hadoop的规范,需要实现write和readFields这两个方法
*3)定义一个默认的构造方法
*/
public class Access implements Writable{
private String phone;
private long up;
private long down;
private long sum;
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phone);
out.writeLong(up);
out.writeLong(down);
out.writeLong(sum);
}
@Override
public void readFields(DataInput in) throws IOException {
this.phone=in.readUTF();
this.up=in.readLong();
this.down=in.readLong();
this.sum=in.readLong();
}
@Override
public String toString() {
return "Access{" +
"phone='" + phone + '\'' +
", up=" + up +
", down=" + down +
", sum=" + sum +
'}';
}
public Access(){}
public Access(String phone,long up,long down){
this.phone=phone;
this.up=up;
this.down=down;
this.sum=up+down;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public long getUp() {
return up;
}
public void setUp(long up) {
this.up = up;
}
public long getDown() {
return down;
}
public void setDown(long down) {
this.down = down;
}
public long getSum() {
return sum;
}
public void setSum(long sum) {
this.sum = sum;
}
}
2.自定义Mapper类
`
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 自定义Mapper处理类
*/
public class AccessMapper extends Mapper<LongWritable,Text,Text,Access>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] lines = value.toString().split("\t");
String phone = lines[1];//取出手机号
long up = Long.parseLong(lines[lines.length-3]);//取出上行流量
long down = Long.parseLong(lines[lines.length-2]);//取出下行流量
context.write(new Text(phone),new Access(phone,up,down));
}
}
3.自定义Reduce类
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AccessReducer extends Reducer<Text,Access,Text,Access> {
/**
*
* @param key 手机号
* @param values <Access,Access>
*/
@Override
protected void reduce(Text key, Iterable<Access> values, Context context) throws IOException, InterruptedException {
long ups = 0;
long downs = 0;
for (Access access:values){
ups+=access.getUp();
downs+=access.getDown();
}
context.write(key,new Access(key.toString(),ups,downs));
}
}
4.自定义Driver类
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AccessLocalApp {
//Driver端的代码:八股文
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(AccessLocalApp.class);
job.setMapperClass(AccessMapper.class);
job.setReducerClass(AccessReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Access.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Access.class);
FileInputFormat.setInputPaths(job,new Path("access/input"));
FileOutputFormat.setOutputPath(job,new Path("access/output"));
job.waitForCompletion(true);
}
}
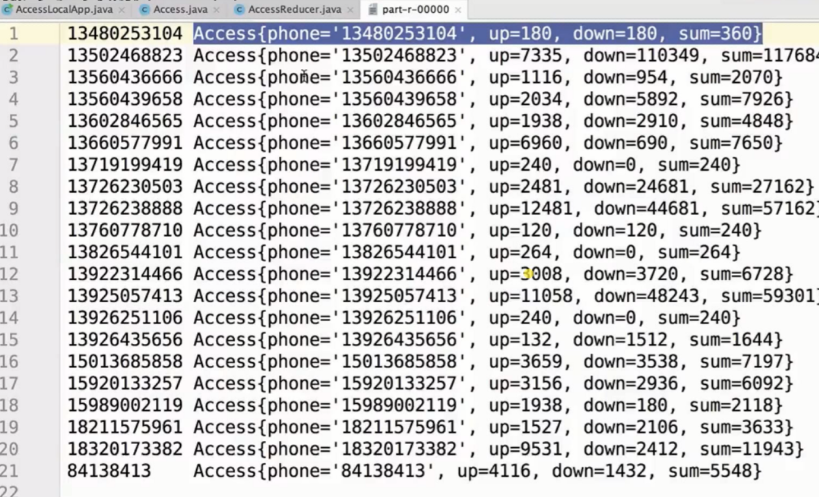
- 结果展示
5.代码重构
NullWritable的使用
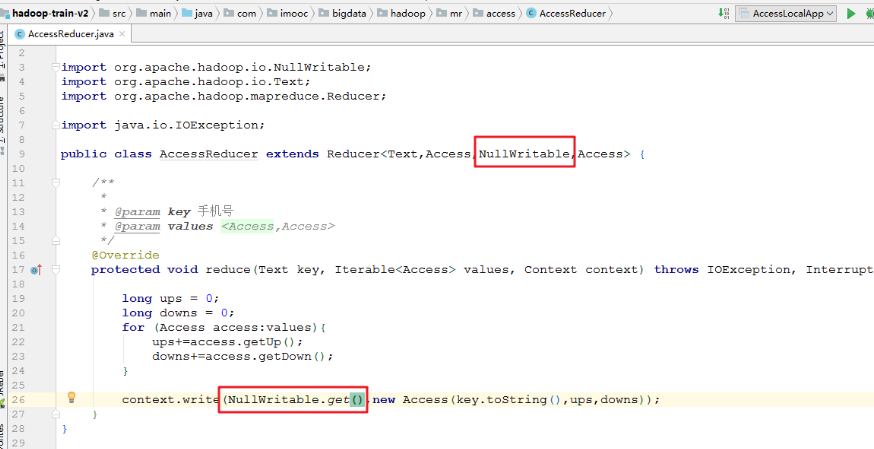
- 修改AccessReducer
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AccessReducer extends Reducer<Text,Access,NullWritable,Access> {
/**
*
* @param key 手机号
* @param values <Access,Access>
*/
@Override
protected void reduce(Text key, Iterable<Access> values, Context context) throws IOException, InterruptedException {
long ups = 0;
long downs = 0;
for (Access access:values){
ups+=access.getUp();
downs+=access.getDown();
}
context.write(NullWritable.get(),new Access(key.toString(),ups,downs));
}
}
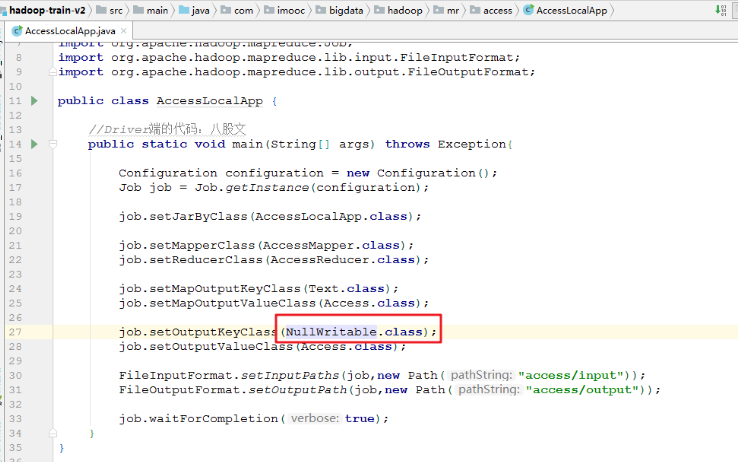
- 修改AccessLocalApp
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AccessLocalApp {
//Driver端的代码:八股文
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(AccessLocalApp.class);
job.setMapperClass(AccessMapper.class);
job.setReducerClass(AccessReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Access.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Access.class);
FileInputFormat.setInputPaths(job,new Path("access/input"));
FileOutputFormat.setOutputPath(job,new Path("access/output"));
job.waitForCompletion(true);
}
}
- 结果
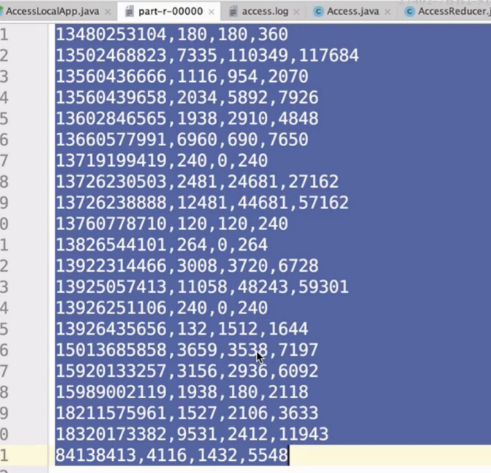
6.自定义Partitioner
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
public int getPartition(K2 key, V2 value,int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
numReduceTasks:作业所指定的reducer的个数,决定了reduce作业输出文件的个数
HashPartitioner是MapReduce默认的分区规则
reducer个数:3
1%3=1
2%3=2
3%3=0Partitioner决定maptask输出的数据交由哪个reducetask处理
默认实现:分发的key的hash值与reduce task个数取模
- AccessPartitioner
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class AccessPartitioner extends Partitioner<Text,Access> {
/**
*
* @param phone 手机号
* @param access
* @param numReduceTasks
* @return
*/
@Override
public int getPartition(Text phone, Access access, int numReduceTasks) {
if (phone.toString().startsWith("13")){
return 0;
}else if (phone.toString().startsWith("15")){
return 1;
}else {
return 2;
}
}
}
- AccessLocalApp
package com.imooc.bigdata.hadoop.mr.access;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class AccessLocalApp {
//Driver端的代码:八股文
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(AccessLocalApp.class);
job.setMapperClass(AccessMapper.class);
job.setReducerClass(AccessReducer.class);
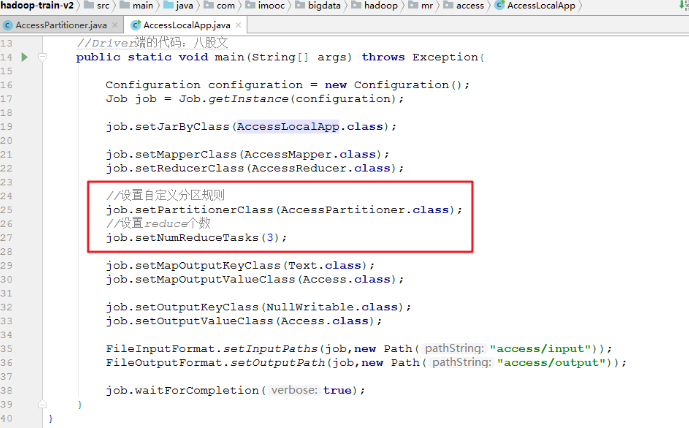
//设置自定义分区规则
job.setPartitionerClass(AccessPartitioner.class);
//设置reduce个数
job.setNumReduceTasks(3);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Access.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Access.class);
FileInputFormat.setInputPaths(job,new Path("access/input"));
FileOutputFormat.setOutputPath(job,new Path("access/output"));
job.waitForCompletion(true);
}
}
提交流量统计项目至YARN
1.打包程序
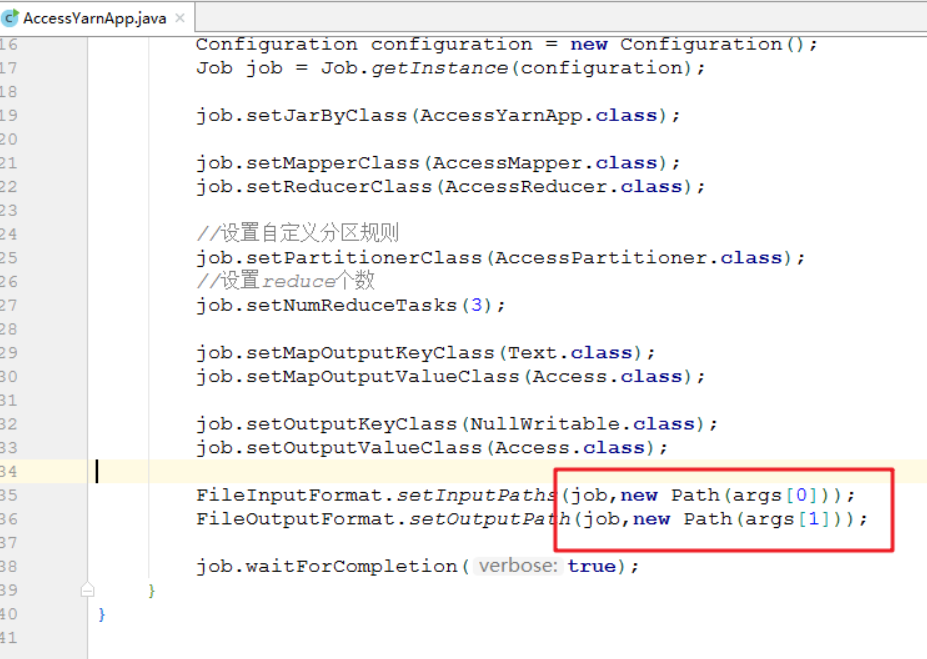
- 打包
mvn clean package -DskipTests
2.上传jar包和测试数据至服务器(可通过SSH工具实现)
3.上传数据集到HDFS
hadoop fs -mkdir -p /access/input
hadoop fs -put access.log /access/input
4.运行jar包
hadoop jar hadoop-train-v2-1.0.jar com.imooc.bigdata.hadoop.mr.access.AccessYarnApp /access/input/access.log /access/output/

