

大数据技术与Hadoop集群部署
大数据技术概述
大数据简介
大数据技术是一组用于处理、存储和分析大规模数据集的技术和工具。随着数字化时代的到来,数据量的爆炸性增长使得传统的数据处理和分析方法变得不够高效,因此大数据技术应运而生。
大数据技术的主要特点包括:
处理海量数据、并行处理、 实时处理、多样化数据源、可伸缩性;
大数据技术提供的思路是分而治之与移动计算而非移动数据,使得海量数据的存储与计算变得更加高效和可靠。
Hadoop简介
Hadoop的核心组件主要包括HDFS、YARN和MapReduce,它们共同构成了Hadoop生态系统的基础。
-
Hadoop分布式文件系统(HDFS):HDFS是Hadoop的分布式文件系统,用于存储大规模数据集。它具有高容错性、高可靠性和高可扩展性的特点,通过将数据分割成多个块并在集群中多个节点上存储多个副本来实现这些特点。HDFS的设计旨在适应常见的硬件故障,并提供了对大文件的高吞吐量访问。
-
YARN(Yet Another Resource Negotiator):YARN是Hadoop的资源管理器,负责管理和分配集群中的资源,以供不同类型的应用程序使用。它通过资源管理和作业调度,为Hadoop集群中的应用程序提供资源。YARN的出现使得Hadoop集群能够运行不仅限于MapReduce的各种计算框架和应用程序,如Apache Spark、Apache Flink等。
-
MapReduce:MapReduce是Hadoop最早的分布式计算框架,用于并行处理大规模数据集。它由两个主要阶段组成:Map阶段和Reduce阶段。在Map阶段,数据被分割成多个片段并在各个节点上进行并行处理;在Reduce阶段,将Map阶段输出的中间结果合并和汇总,生成最终的输出结果。尽管现在有更多的高级数据处理框架可供选择,但MapReduce仍然是Hadoop生态系统的一个重要组件。
这三个组件一起构成了Hadoop生态系统的基础,为大规模数据处理提供了可靠、高效的解决方案。
hadoop安装&hadoop-env配置
1.hadoop(HDFS)安装
解压hadoop-2.6.0-cdh5.15.1.tar.gz至app
tar -zxvf hadoop-2.6.0-cdh5.15.1.tar.gz -C ~/app/


2.修改hadoop-env.sh
cd
cd app/hadoop-2.6.0-cdh5.15.1/
cd etc/hadoop
vi hadoop-env.sh

export JAVA_HOME=/home/hadoop/app/jdk1.8.0_152

HDFS格式化
1.core-site.xml
cd
cd app/hadoop-2.6.0-cdh5.15.1/
vi etc/hadoop/core-site.xml
添加如下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://left-Lenovo:8020</value>
</property>
</configuration>
2.hdfs-site.xml
cd
cd app/hadoop-2.6.0-cdh5.15.1/
vi etc/hadoop/hdfs-site.xml
添加如下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
</configuration>
3.slaves从节点信息配置:
cd
cd app/hadoop-2.6.0-cdh5.15.1/
vi etc/hadoop/slaves
4.配置hadoop环境变量
vi ~/.bash_profile
/home/hadoop/app/hadoop-2.6.0-cdh5.15.1
添加如下配置:
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.15.1
export PATH=$HADOOP_HOME/bin:$PATH

生效环境变量:
source ~/.bash_profile
5.启动HDFS
- HDFS格式化
第一次执行的时候一定格式化文件系统,不要重复执行
cd $HADOOP_HOME/bin
hdfs namenode -format
- 启动HDFS
cd $HADOOP_HOME/sbin
./start-dfs.sh
- 验证:
jps
出现如下信息则成功:
7922 Jps
7764 SecondaryNameNode
7561 DataNode
7454 NameNode
此外,也可使用HDFS的webui验证是否成功
HDFS可视化界面
HDFS提供了Web管理界面,可以很方便地查看HDFS相关信息。在浏览器地址栏中输入http://node01:50070,这里将node01替换为第1台节点的IP,就可以进入HDFS的Web管理界面。
在HDFS的Web管理界面中,包含了“Overview”、“Datanodes”、“Datanode Volume Failures”、“Snapshot”、“Startup Progress”和“Utilities”等菜单选项,点击每个菜单选项可以进入相应的管理界面,查询各种详细信息。
Utilities工具中有Browse the file system可以直观查看HDFS文件。
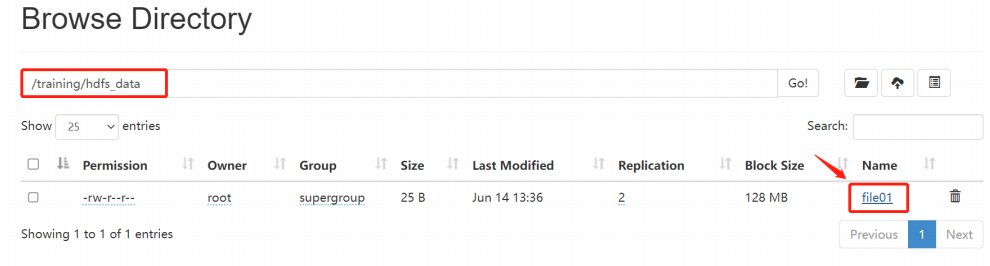
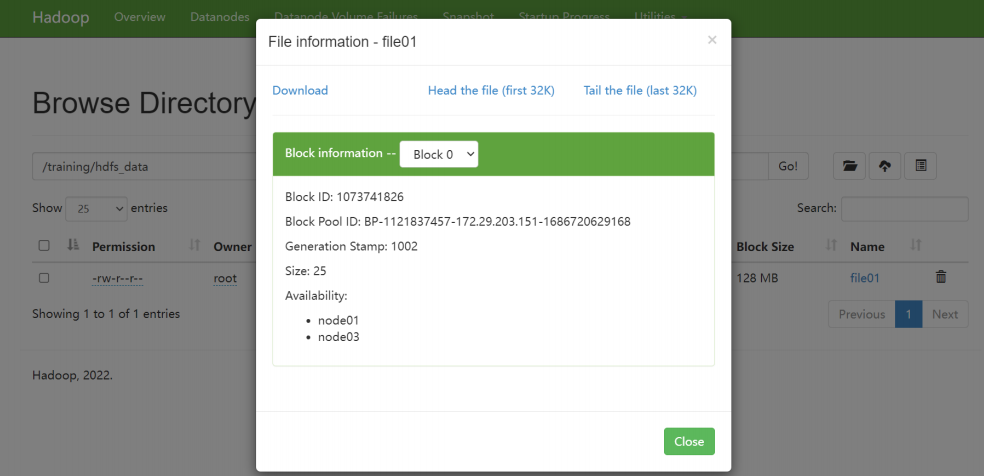
找到/training/hdfs_data/file01文件,查看file01文件存储情况。
常用的命令行操作
hadoop fs -...
1.创建文件夹
hadoop fs -mkdir -p /test/a/b
2.递归展示
hadoop fs -ls -R /
3.文件拿至本地
hadoop fs -get /test/a/b/h.txt
4.拷贝
hadoop fs -copyFromLocal hello.txt /test/a/b/h.txt
5.删除文件夹
hadoop fs -rm -R /test
6.上传文件
hadoop fs -put hello.txt /
7.读取文件
hadoop fs -text /hdfsapi/test/a.txt
8.查看更多指令
hadoop fs+回车
9.拓展
hadoop fs -ls = hadoop fs -ls /user/hadoop
至此,Hadoop的集群部署完成!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界