“希希敬敬对”团队作业——敏捷冲刺5
“希希敬敬对”百度贴吧小爬虫任务计划:今天的团队讨论照片:
今天讨论照片:

龙江腾(队长) 201810775001
完成“把10个页面的数据整合到一个数据组中,并进行排序”的功能,明天完成爬下的发帖主题人信息进行图形化显示的review。
杨希 201810812008
完成“把10个页面的数据整合到一个数据组中,并进行排序”的代码review,明天完成爬下的发帖主题人信息进行图形化显示。
何敬上 201810812004
完成“把10个页面的数据整合到一个数据组中,并进行排序”的功能,明天完成爬下的发帖主题人信息进行图形化显示的review。
遇到的问题:
暂无
燃尽图:

程序代码(基于昨天代码的基础上的更新):
#分析获取到的字符串
def __analysis(self, htmls):
#root_html获取包含了主题作者和帖子回复数关键字的标签
root_html = re.findall(BDTBCrawler.root_pattern, htmls)
#用anchors这个列表来存放提取出来的主题作者和帖子回复数组成的字典
anchors = []
for html in root_html:
# 提取主题作者(列表类型),并将其转换成字符串
name = re.findall(BDTBCrawler.name_pattern, html)
name = str(name[0])
# #提取回复数(列表类型),并将其转换成整形数字
number = re.findall(BDTBCrawler.num_pattern, html)
number = int(number[0])
#用来记录列表的遍历过程中其子元素——字典中是否有与当前name相同的key值
flag = False
# 遍历anchors列表,如果有相同的主题作者执行回复数累加操作
for i in anchors:
if name == i['name']:
number = i['number'] + number
# print(number)
i.update({'name':i['name'], 'number':number})
flag = True #有与当前作者相同的主题作者
break
if flag == False:
anchor = {'name': name, 'number': number}
anchors.append(anchor)
# print(anchors)
return anchors
#排序算法
def __sort(self, anchors):
anchors = sorted(anchors, key=lambda d: d['number'], reverse=True)
return anchors
def __analysis(self, htmls):
#root_html获取包含了主题作者和帖子回复数关键字的标签
root_html = re.findall(BDTBCrawler.root_pattern, htmls)
#用anchors这个列表来存放提取出来的主题作者和帖子回复数组成的字典
anchors = []
for html in root_html:
# 提取主题作者(列表类型),并将其转换成字符串
name = re.findall(BDTBCrawler.name_pattern, html)
name = str(name[0])
# #提取回复数(列表类型),并将其转换成整形数字
number = re.findall(BDTBCrawler.num_pattern, html)
number = int(number[0])
#用来记录列表的遍历过程中其子元素——字典中是否有与当前name相同的key值
flag = False
# 遍历anchors列表,如果有相同的主题作者执行回复数累加操作
for i in anchors:
if name == i['name']:
number = i['number'] + number
# print(number)
i.update({'name':i['name'], 'number':number})
flag = True #有与当前作者相同的主题作者
break
if flag == False:
anchor = {'name': name, 'number': number}
anchors.append(anchor)
# print(anchors)
return anchors
#排序算法
def __sort(self, anchors):
anchors = sorted(anchors, key=lambda d: d['number'], reverse=True)
return anchors
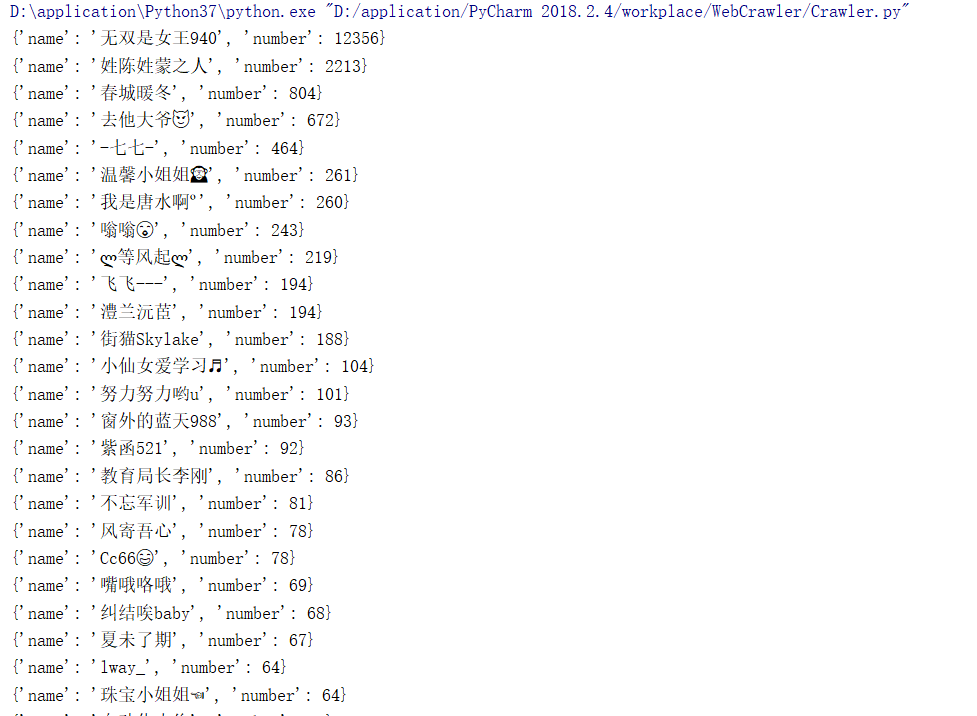
程序运行结果部分截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号