
Roubst 3D object tracking from monocular images using stable parts
Robust 3D Object Tracking from Monocular Images using stable parts
声明
本文内容系本人自主创作,文中部分名词翻译是个人直译,或与学术词汇不符。
引子
跟踪
物体跟踪主要解决实时条件下物体的连续定位问题。根据被追踪物体的自由度,我们可以将物体跟踪算法粗略的划分为二维跟踪问题和三维跟踪问题。在二维跟踪中,跟踪器主要负责追踪目标物体在图像序列中的投影,也就是说,跟踪器需要根据目标物体在上一帧中出现的位置预测物体在当前帧中的定位,注意在二维跟踪器中物体的定位坐标都是二维坐标。二维跟踪器通常应用在视频监控领域,用来监测车辆轨迹、监控车辆速度或是检测车流量等。与二维跟踪器不同,三维跟踪器通常用来估计物体的三维位姿,需要恢复物体相对相机的六个自由度。三维跟踪器通常应用于物体位姿很重要的应用中,比如在增强现实应用中,我们希望将虚拟物体叠加到真实物体上,我们就需要跟踪被叠加的真实物体的三维位姿;又或是在工业机器人领域,我们希望机器人通过机器视觉自动实现物体的识别与抓取。这篇论文主要研究三维物体跟踪算法。
复杂情景
在现实中会有很多复杂的情景会使得跟踪器失效,比如环境光照的剧烈改变、反射/镜面表面、大范围的遮挡、无纹理的物体表面以及杂乱环境等等。
标题论文提出了一种足以在上述复杂情景下运行的健壮(robust)的算法。
相关方法
基于特征点的方法
通过在不同图像间匹配特征的方法估计相机的位姿。不适用于无纹理的物体。
基于边缘的方法
沿着物体三维模型的边界采样三维坐标点,并计算这些采样点在图像中的投影;同时计算图像中的边缘。物体的位姿可以通过对齐采样点的投影和图像边缘来计算。不适用于大范围遮挡和杂乱的环境。
基于区域的方法
基于区域的方法假设物体的三维模型是已知的,物体的三维位姿可以通过该物体在二维图像中的分割来估计。不太适用于物体被部分遮挡的情形。
基于深度相机的算法
利用深度传感器的跟踪算法。不适用反射、吸收以及透明的表面。
基于物体部件的算法
本篇论文既是基于物体部件的算法。算法的基本思路是:给定物体的三维模型,从三维模型上选择某些部件用于物体的位姿估计。在跟踪过程中,跟踪器首先识别物体在被追踪部件在图像中的投影,然后用部件投影估计物体的三维位姿。基于物体部件的算法也有很多,但某些算法在部分部件被遮挡的情形下可能无法有效工作。
方法描述
综述
问题定义:
论文中的算法用于连续估计三维物体的位置和朝向,该算法具有以下约束:
- 实时算法
- 基于单目相机的算法
- 只追踪单个物体
- 被追踪物体的三维模型已知
整个算法的基本流程为:
首先,根据物体的三维模型,选择物体的某些部件用作被追踪的部件。当跟踪器运行时,跟踪器首先定位被追踪部件在图像中的二维投影位置,然后利用被追踪部件的二维投影估计被追踪部件的三维位姿,物体的位姿则通过被追踪部件的三维位姿来恢复。
物体部件检测
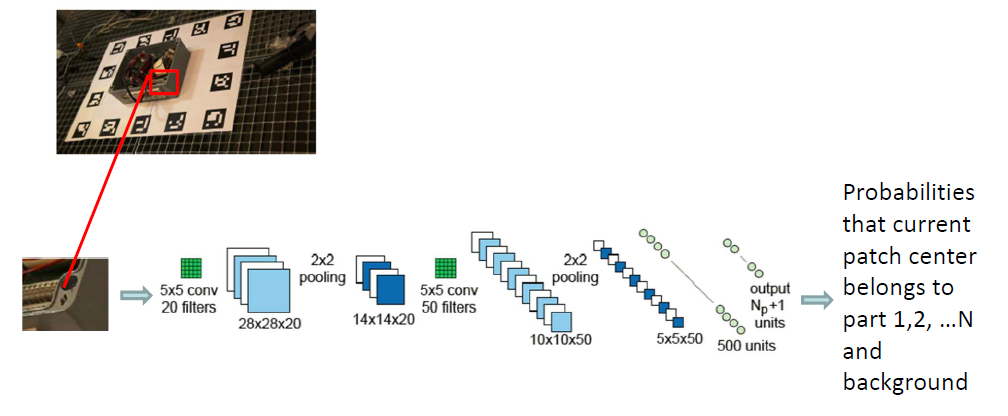
在这篇论文中,作者使用卷积神经网络作为部件检测器。该卷积神经网络不使用整张图片作为输入,而是采用小图像块(32*32)作为输入;卷积神经网络的输出就是该图像块中心点属于各个部件/背景的概率。遍历输入图像中的每个小图块,把每个图像块都作为卷积神经网络的输入,由此得到每个图像块中心属于各个部件的概率。选择概率最大的部件作为图像块中心归属的部件,绘制成如下图像:

为了消除噪声的影响,作者应用了一个高斯滤波器来得到更加平滑的输出结果。被检测部件在图像中可能的投影位置就是卷积神经网络平滑输出中的局部最大值。在这种情形下,每个物体部件可能会对应到多个可能的投影位置(局部最大值不唯一),我们会在第三部分介绍如何应对这种冗余检测。
部件位姿估计
在前一步中,我们得到了被追踪部件在图像中的投影位置。现在我们希望由此恢复部件在三维空间中的位置。作者的初步设想是训练另一个神经网络,直接用部件在图像中的投影位置和投影位置周围的图像恢复部件的位姿。在论文中,作者探讨了物体部件位姿的不同表达形式,因为部件位姿的表达形式直接关系到神经网络的输出结果。
- 用Homography 表达部件位姿。这种方法的局限性在于很难融合多个物体部件的三维位姿。
- 用三维旋转和深度值表达部件位姿。部件的三维位置可以通过部件的二维投影坐标和深度值恢复。这个方法的局限性在于很难通过单个图像块精确的估计深度值。
- 用三维控制点(3D control points)在相机坐标系的位姿表达部件位姿。部件的三维位姿可以通过求解ICP算法来估计。这个方法的局限性在于很难通过单个图像块精确地估计物体的三维坐标(至于原因留待有空再解释)
最后作者用三维控制点相对于部件图像中心点的投影来表示部件位姿。部件的三维位姿可以通过求解PnP问题估计。
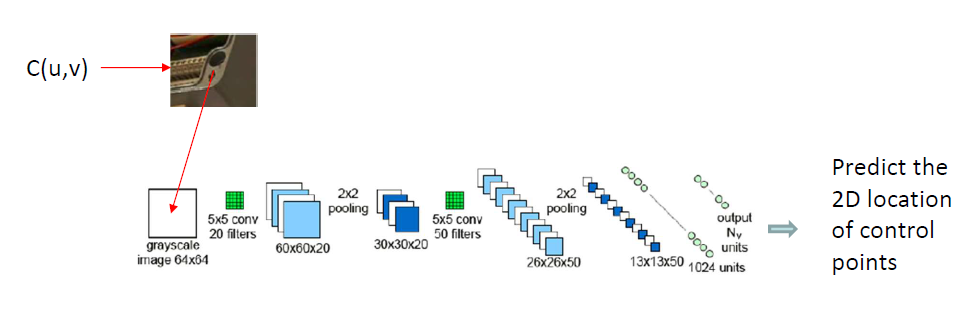
作者选择使用一个CNN网络来预测三维控制点在部件图像中心附近上二维投影。利用物体检测的结果,我们可以知道每个被选定部件在当前图像上的投影位置;以该位置为中心点,在图像上采集一个64*64的图像块,用这个图像块作为卷积神经网络的输入,即可得到神经网络预测的7个投影点的投影位置。有了三维投影点的投影位置,我们很容易利用PnP算法确定部件的三维位姿,因而在论文中,作者直接使用二维投影点表示部件位姿。
物体位姿估计
在前文中我们已经提到,我们可以用CNN网络检测到部件的二维投影位置,又使用了一个CNN来预测空间中固定的一组三位控制点在当前图像上的投影,物体的位姿可以通过求解PnP问题来得到。
但是,这里3D-2D的匹配是不唯一的。给定一个部件,我们可以检测到它在图像中的多个可能的投影位置,由此得到多个可能的二维投影点。这时就会有多个可能的3D-2D匹配,如下图:
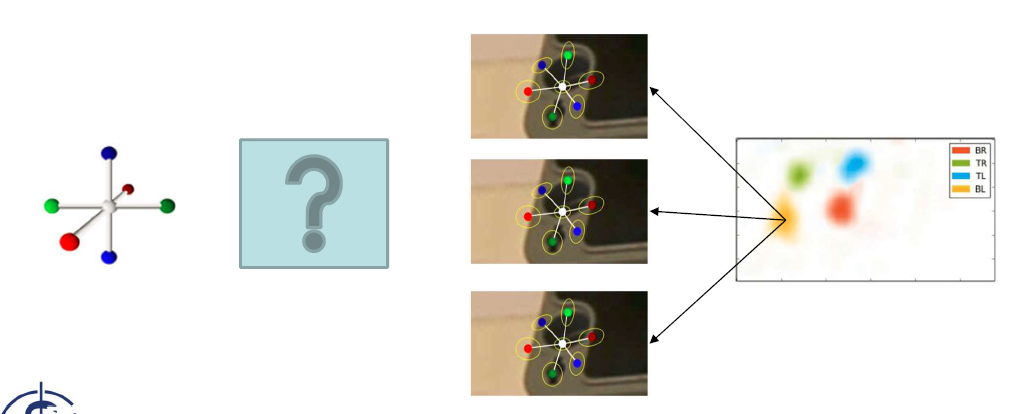
在这种情况下,我们需要在恢复物体位姿的同时恢复3D-2D的匹配,在这片论文中作者采用了位姿先验解决这一难题。(感觉这里也可以用RANSAC解决这个问题)
首先,根据物体的三维模型,预先给出M个位姿先验。如下图所示:
然后,根据部件检测中的结果建立一个部件二维投影位置的候选集。在建立候选集的时候,一定要确保候选集中的每一个子集对每一个部件最多只有一个二维投影(location of object part in image)预测。
然后,对于每一个位姿先验,我们从候选集中选择出一个最好的子集,利用子集估计物体的位姿,其过程如下:
- 从某一个子集中任意选择两个两个候选检测点,用他们来调整原有位姿先验,得到一个新的位姿先验
- 根据这个新的位姿先验计算子集中剩余候选点的重投影误差
- 就当前位姿先验,对每一个候选集中的子集重复前两步操作,只保留重投影误差最小且包含检测部件最多的子集作为最佳子集
- 利用第三步得到的最佳子集以及原始的位姿先验(不是第一步中的新位姿先验),通过最小化重投影误差以及最小化物体位姿与原始位姿先验间的位移来求解物体最终位姿。
我们对所有位姿先验重复以上操作,最终,对于所有位姿先验,我们均能得到一个估计的物体位姿。在程序实际运行中,除了程序一开始设定的M个位姿先验,也会使用上一步估计得到的物体位姿作为当前的位姿先验,最终得到(M+1)个候选的物体位姿。
作者最终训练了一个线性回归器来从(M+1)个候选的物体位姿中选择最佳位姿。重投影误差、图像边界和物体模型边缘的二维投影之间的关系以及物体位姿与位姿先验的差别等均作为这个线性回归器的线索,回归器输出该位姿的惩罚分数。最终作者选择惩罚分数最小的模型作为物体的最终模型。

卡尔曼滤波器
文中使用了扩展卡尔曼滤波器进行轨迹跟踪。作者假设被追踪的物体在某一时间段内以恒速移动以及旋转,(因为这里假设物体恒速旋转,涉及非线性运动模型,故而采用扩展卡尔曼滤波器),根据假设的运动模型预测物体的三维位姿;然后利用从图像中估计得到的物体三维位姿作为观测结果,用观测校正预测,得到物体的最终位姿。
实验结果
该文章的作者在youtube上上传了视频用以直观展现他们算法的性能。从视频中可以看到,文中算法在遇到反射表面、物体遮挡以及复杂环境时都能表现出良好的追踪效果。
Reference
A. Crivellaro, M. Rad, Y. Verdie, K. M. Yi, P. Fua and V. Lepetit, "A Novel Representation of Parts for Accurate 3D Object Detection and Tracking in Monocular Images," 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, 2015, pp. 4391-4399.
doi: 10.1109/ICCV.2015.499

