ElasticSearch7.3学习(九)----Mapping核心数据类型及dynamic mapping
1、mapping的核心数据类型以及dynamic mapping
1.1 核心的数据类型
string :text and keyword,byte,short,integer,long,float,double,boolean,date
详见:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/mapping-types.html。
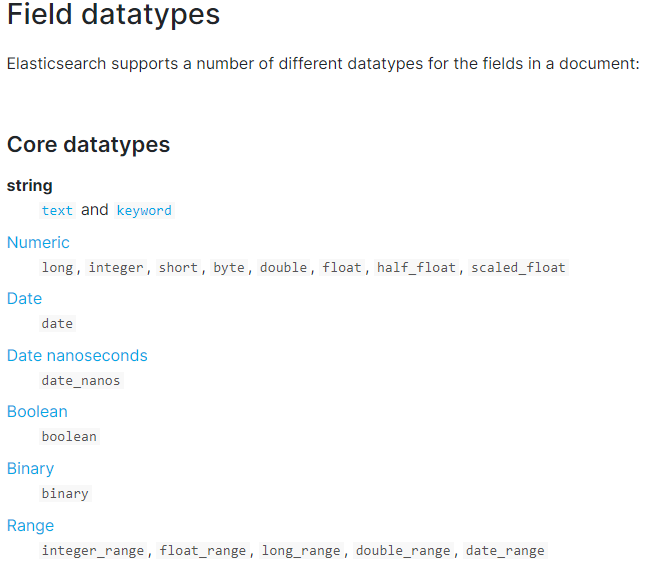
下图是ES7.3核心的字段类型如下:
1.2 dynamic mapping 推测规则
true or false --> boolean
123 --> long
123.45 --> double
2019-01-01 --> date
"hello world" --> text/keywod1.3 查看索引mapping
语法如下:
GET index_name/_mapping2、手动管理mapping
2.1 查询所有索引的映射
语法如下:
GET /_mapping结果如下:

2.2 创建映射
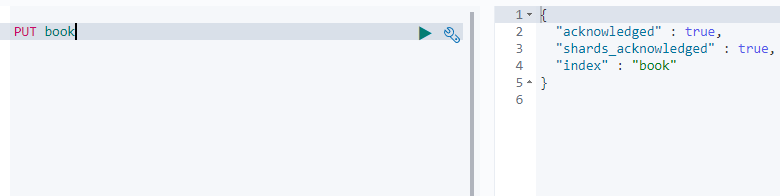
首先创建索引
PUT book结果如下
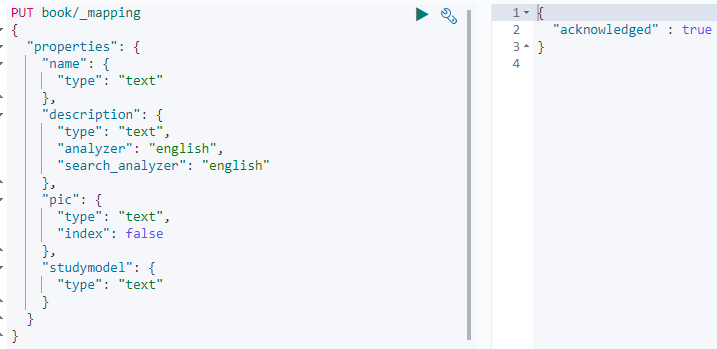
创建索引后,应该立即手动创建映射
PUT book/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"analyzer":"english",
"search_analyzer":"english"
},
"pic":{
"type":"text",
"index":false
},
"studymodel":{
"type":"text"
}
}
}结果如下:
2.3 字段解释
2.3.1 Text 文本类型
1)analyzer:通过analyzer属性指定分词器。上边指定了analyzer是指在索引和搜索都使用english,如果单独想定义搜索时使用的分词器则可以通过search_analyzer属性。
2)index:index属性指定是否索引。默认为index=true,即要进行索引,只有进行索引才可以从索引库搜索到。但是也有一些内容不需要索引,比如:商品图片地址只被用来展示图片,不进行搜索图片,此时可以将index设置为false。删除索引,重新创建映射,将pic的index设置为false,尝试根据pic去搜索,结果搜索不到数据。
3)store:是否在source之外存储,每个文档索引后会在 ES中保存一份原始文档,存放在"_source"中,一般情况下不需要设置store为true,因为在_source中已经有一份原始文档了。
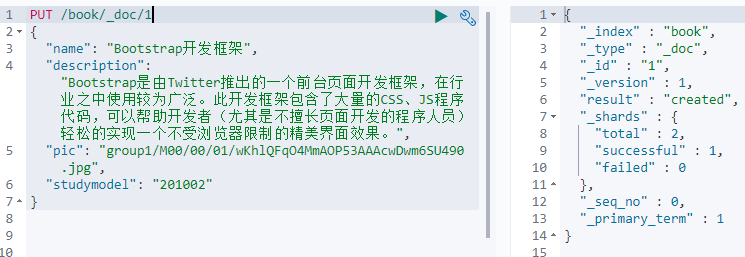
举个例子,插入以下文档:
PUT /book/_doc/1
{
"name":"Bootstrap开发框架",
"description":"Bootstrap是由Twitter推出的一个前台页面开发框架,在行业之中使用较为广泛。此开发框架包含了大量的CSS、JS程序代码,可以帮助开发者(尤其是不擅长页面开发的程序人员)轻松的实现一个不受浏览器限制的精美界面效果。",
"pic":"group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpg",
"studymodel":"201002"
}结果如下:
分别用以下语句来判断是否
GET /book/_search?q=name:开发GET /book/_search?q=description:开发GET /book/_search?q=pic:group1/M00/00/01/wKhlQFqO4MmAOP53AAAcwDwm6SU490.jpgGET /book/_search?q=studymodel:201002通过测试发现:除了第三条语句,其余均能搜索出结果。也就是说name、description及studymodel都支持全文检索,除了pic不可作为查询条件。
2.3.2 keyword关键字字段
目前已经取代了"index": false。上边介绍的text文本字段在映射时要设置分词器,keyword字段为关键字字段,通常搜索keyword是按照整体搜索,所以创建keyword字段的索引时是不进行分词的,比如:邮政编码、手机号码、身份证等。keyword字段通常用于过虑、排序、聚合等。
2.3.3 date日期类型
日期类型不用设置分词器。
通常日期类型的字段用于排序。
format:通过format设置日期格式
例子:下边的设置允许date字段存储年月日时分秒、年月日及毫秒三种格式。
{
"properties": {
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}2.3.4 数值类型
下边是ES支持的数值类型

在选择数据类型的是,应尽量遵循下面的规范:
1、尽量选择范围小的类型,提高搜索效率
2、对于浮点数尽量用比例因子,比如一个价格字段,单位为元,我们将比例因子设置为100。这在ES中会按 分 存储,映射如下:
"price": {
"type": "scaled_float",
"scaling_factor": 100
},由于比例因子为100,如果我们输入的价格是23.45。则ES中会将23.45乘以100存储在ES中。如果输入的价格是23.456,ES会将23.456乘以100再取一个接近原始值的数,得出2346。使用比例因子的好处是整型比浮点型更易压缩,节省磁盘空间。如果比例因子不适合,则从表中选择范围小的去用:
2.4 修改映射
只能创建index时手动建立mapping,或者新增field mapping,但是不能update field mapping。因为已有数据按照映射早已分词存储好,如果修改的话,那这些存量数据怎么办。
新增一个字段mapping
PUT /book/_mapping/
{
"properties": {
"new_field": {
"type": "text",
"index": "false"
}
}
}结果如下:
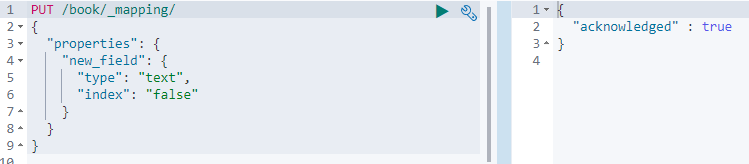
如果直接修改mapping的话会报错
PUT /book/_mapping/
{
"properties" : {
"studymodel" : {
"type" : "keyword"
}
}
}返回:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [studymodel] of different type, current_type [text], merged_type [keyword]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [studymodel] of different type, current_type [text], merged_type [keyword]"
},
"status": 400
}2.5 删除映射
通过删除索引的方式来删除映射。
DELETE /book3、复杂数据类型
3.1 multivalue field
如下所示,字段里面存放的是数组
{ "tags": [ "tag1", "tag2" ]}建立索引时与string是一样的,注意数组里面存放的数据的数据类型不能混
3.2 empty field
空值存放
null,[],[null]如果是text或者keyword类型,空值为null,如果是数组类型的话,空值为后面两个中的任意一个。
3.3 object field
意思就是字段里面存放的是一个对象
PUT /company/_doc/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2019-01-01"
}执行上面语句:
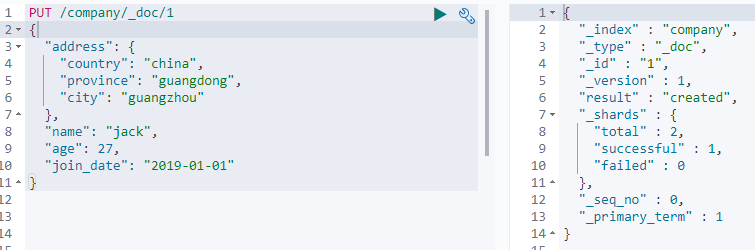
其中的address field 就是object类型
查询company映射
GET /company/_mapping返回:
{
"company" : {
"mappings" : {
"properties" : {
"address" : {
"properties" : {
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"country" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"province" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"age" : {
"type" : "long"
},
"join_date" : {
"type" : "date"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}3.4 底层存储格式
object类型:
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}对应的底层存储格式,可以看到其实就是扁平化处理了
{
"name": [jack],
"age": [27],
"join_date": [2017-01-01],
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou]
}对象数组:
{
"authors": [
{ "age": 26, "name": "Jack White"},
{ "age": 55, "name": "Tom Jones"},
{ "age": 39, "name": "Kitty Smith"}
]
}存储格式:
{
"authors.age": [26, 55, 39],
"authors.name": [jack, white, tom, jones, kitty, smith]
}
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/16006272.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号