图像识别模型
一、数据准备
首先要做一些数据准备方面的工作:一是把数据集切分为训练集和验证集, 二是转换为tfrecord 格式。在data_prepare/文件夹中提供了会用到的数据集和代码。首先要将自己的数据集切分为训练集和验证集,训练集用于训练模型, 验证集用来验证模型的准确率。这篇文章已经提供了一个实验用的卫星图片分类数据集,这个数据集一共6个类别, 见下表所示
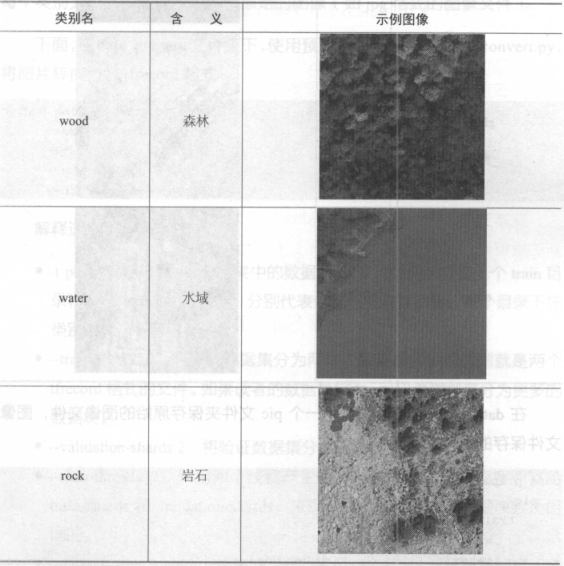
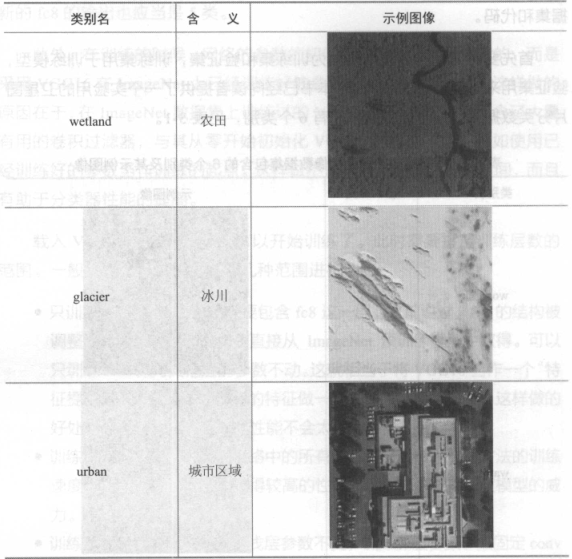
在data_prepare目录中,有一个pic文件夹保存原始的图像文件,这里面有train 和validation 两个子目录,分别表示训练使用的图片和验证使用的图片。在每个目录中,分别以类别名为文件夹名保存所有图像。在每个类别文件夹下,存放的就是原始的图像(如jpg 格式的图像文件)。下面在data_prepare 文件夹下,使用预先编制好的脚本data_convert .py,使用以下命令将图片转换为为tfrecord格式。
python data_convert.py
data_convert.py代码中的一些参数解释为:
# -t pic/: 表示转换pic文件夹中的数据。pic文件夹中必须有一个train目录和一个validation目录,分别代表训练和验证数据集。
#–train-shards 2:将训练数据集分成两块,即最后的训练数据就是两个tfrecord格式的文件。如果自己的数据集较大,可以考虑将其分为更多的数据块。
#–validation-shards 2: 将验证数据集分为两块。
#–num-threads 2:采用两个线程产生数据。注意线程数必须要能整除train-shaeds和validation-shards,来保证每个线程处理的数据块是相同的。
#–dataset-name satellite: 给生成的数据集起一个名字。这里将数据集起名叫“satellite”,最后生成的头文件就是staellite_trian和satellite_validation。
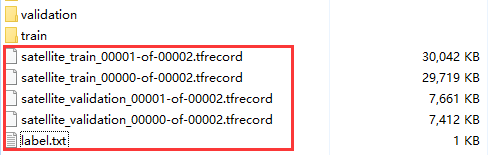
运行上述命令后,就可以在pic文件夹中找到5个新生成的文件,分别是两个训练数据和两个验证数据,还有一个文本文件label.txt ,其表示图片的内部标签(数字)到真实类别(字符串)之间的映射顺序。如图片在tfrecord 中的标签为0 ,那么就对应label.txt 第一行的类别,在tfrecord的标签为1,就对应label.txt 中第二行的类别,依此类推。
二、使用TensorFlow Slim微调模型
1、介绍TensorFlow Slim源码
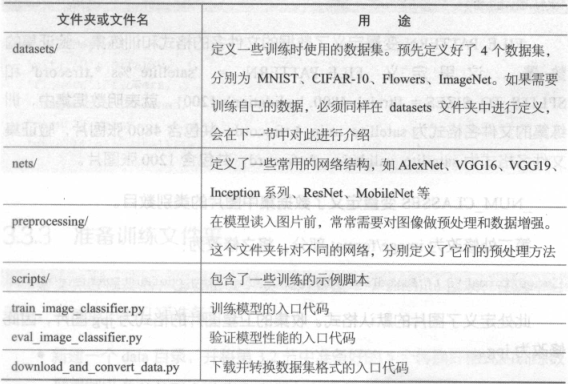
TensorFlow Slim 是Google 公司公布的一个图像分类工具包,它不仅定义了一些方便的接口,还提供了很多ImageNet数据集上常用的网络结构和预训练模型。截至2017 年7 月, Slim 提供包括VGG16 、VGG19 、InceptionVl ~ V4, ResNet 50 、ResNet 101, MobileNet 在内大多数常用模型的结构以及预训练模型,更多的模型还会被持续添加进来。如果需要使用Slim 微调模型,首先要下载Slim的源代码。Slim的源代码保存在tensorflow/models 项目中https://github.com/tensorflow/models/tree/master/research/slim。提供的代码里面已经包含了这份代码,在chapter3/slim目录下。下面简单介绍下Slim的代码结构,如下表所示:
2、定义新的datasets文件
在slim/datasets 中, 定义了所有可以使用的数据库,为了可以使用在前面中创建的tfrecord数据进行训练,必须要在datasets中定义新的数据库。首先,在datasets/目录下新建一个文件satellite.py,并将flowers.py 文件中的内容复制到satellite.py 中。接下来,需要修改以下几处内容:第一处是_FILE_PATTERN 、SPLITS_TO SIZES 、_NUM_CLASSES , 将其进行以下修改:
_FILE_PATTERN = 'satellite_%s_*.tfrecord'
SPLITS_TO_SIZES = {'train':4800, 'validation':1200}
_NUM_CLASSES = 6
第二处修改image/format部分,将之修改为:
'image/format' tf.FixedLenFeature( (), tf. string, default_value ='jpg'),
此处定义了图片的默认格式。收集的卫星图片的格式为jpg图片,因此修改为jpg 。修改完satellite.py后,还需要在同目录的dataset_factory.py文件中注册satellite数据库。注册后dataset_factory. py 中对应代码为:
from datasets import cifar10
from datasets import flowers
from datasets import imagenet
from datasets import mnist
from datasets import satellite # 自行添加
datasets_map = {
'cifar10': cifar10,
'flowers': flowers,
'imagenet': imagenet,
'mnist': mnist,
'satellite':satellite, # 自行添加
}
3、准备训练文件夹
定义完数据集后,在slim文件夹下再新建一个satellite目录,在这个目录中,完成最后的几项准备工作:
新建一个data目录,并将前面准备好的5 个转换好格式的训练数据(4个tfrecords文件和1个txt文件)复制进去。
新建一个空的train_dir 目录,用来保存训练过程中的日志和模型。
新建一个pretrained目录,在slim的GitHub页面找到Inception_V3 模型的下载地址,下载并解压后,会得到一个inception_v3 .ckpt 文件,将该文件复制到pretrained 目录下。
最后形成的目录如下所示:
4、开始训练
在slim 文件夹下,运行以下命令就可以开始训练了:
python train_image_classifier.py
train_image_classifier.py中部分参数解释如下:
# –trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits:首先来解释trainable_scope的作用,因为它非常重要。
trainable_scopes规定了在模型中微调变量的范围。这里的设定表示只对InceptionV3/Logits,InceptionV3/AuxLogits 两个变量进行微调,
其它的变量都不动。InceptionV3/Logits,InceptionV3/AuxLogits就相当于在VGG模型中的fc8,他们是Inception V3的“末端层”。
如果不设定trainable_scopes,就会对模型中所有的参数进行训练。
# –train_dir=satellite/train_dir:表明会在satellite/train_dir目录下保存日志和checkpoint。
# –dataset_name=satellite、–dataset_split_name=train:指定训练的数据集。在3.2节中定义的新的dataset就是在这里发挥用处的。
# –dataset_dir=satellite/data: 指定训练数据集保存的位置。
# –model_ name=inception_v3 :使用的模型名称。
# –checkpoint_path=satellite/pretrained/inception_v3.ckpt:预训练模型的保存位置。
# –checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits : 在恢复预训练模型时,不恢复这两层。正如之前所说,
这两层是InceptionV3模型的末端层,对应着ImageNet 数据集的1000 类,和当前的数据集不符, 因此不要去恢复它。
# –max_number_of_steps 100000 :最大的执行步数。
# –batch_size =32 :每步使用的batch 数量。
# –learning_rate=0.001 : 学习率。
# –learning_rate_decay_type=fixed:学习率是否自动下降,此处使用固定的学习率。
# –save_interval_secs=300 :每隔300s ,程序会把当前模型保存到train_dir中。此处就是目录satellite/train_dir 。
# –save_summaries_secs=2 :每隔2s,就会将日志写入到train_dir 中。可以用TensorBoard 查看该日志。此处为了方便观察,
设定的时间间隔较多,实际训练时,为了性能考虑,可以设定较长的时间间隔。
# –log_every_n_steps=10: 每隔10 步,就会在屏幕上打出训练信息。
# –optimizer=rmsprop: 表示选定的优化器。
# –weight_decay=0.00004 :选定的weight_decay值。即模型中所有参数的二次正则化超参数。
但是经过笔者自己实验,发现在书上给出的下载地址下载的inception_v3.ckpt,会报出如下错误:DataLossError (see above for traceback): Unable to open table file satellite/pretrained/inception_v3.ckpt: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need touse a different restore operator?。如下图所示:

解决办法:文件错误,笔者选择从CSDN重新下载inception_v3.ckpt。这才能够训练起来。如下图所示是成功训练起来的截图

以上参数是只训练末端层InceptionV3/Logits, InceptionV3/AuxLogits, 还可以去掉–trainable_ scopes 参数。原先的–trainable_scopes= InceptionV3 /Logits ,InceptionV3/AuxLogits 表示只对末端层InceptionV3/Logits 和InceptionV3/AuxLogits 进行训练,去掉后就可以训练模型中的所有参数了。
5、训练程序行为
当train_image_classifier.py程序启动后,如果训练文件夹(即satellite/train_dir)里没有已经保存的模型,就会加载checkpoint_path中的预训练模型,紧接着,程序会把初始模型保存到train_dir中,命名为model.ckpt-0,0表示第0步。这之后,每隔5min(参数--save_interval_secs=300指定了每隔300s保存一次,即5min)。程序还会把当前模型保存到同样的文件夹中,命名格式和第一次保存的格式一样。因为模型比较大,程序只会保留最新的5个模型。
此外,如果中断了程序并再次运行,程序会首先检查train_dir中有无已经保存的模型,如果有,就不会去加载checkpoint_path中的预训练模型,而是直接加载train_dir中已经训练好的模型,并以此为起点进行训练。Slim之所以这样设计,是为了在微调网络的时候,可以方便地按阶段手动调整学习率等参数。
6、验证模型准确率
使用eval_image_classifier.py程序验证模型在验证数据集上的准确率,执行以下指令:
python eval_image_classifier.py
eval_image_classifier.py中部分参数解释如下
# –checkpoint_path=satellite/train_ dir: 这个参数既可以接收一个目录的路径,也可以接收一个文件的路径。如果接收的是一个目录的路径,
# 如这里的satellite/train_dir,就会在这个目录中寻找最新保存的模型文件,执行验证。也可以指定一个模型验证,以第300步为例,
# 如果要对它执行验证,传递的参数应该为satellite/train_ dir/model.ckpt-300 。
# –eval_dir=satellite/eval_dir :执行结果的曰志就保存在eval_dir 中,同样可以通过TensorBoard 查看。
# –dataset_name=satellite 、–dataset_split_name=validation 指定需要执行的数据集。注意此处是使用验证集( validation )执行验证。
# –dataset_dir=satellite/data :数据集保存的位置。
# –model_ name「nception_ v3 :使用的模型。
执行后,出现如下结果:
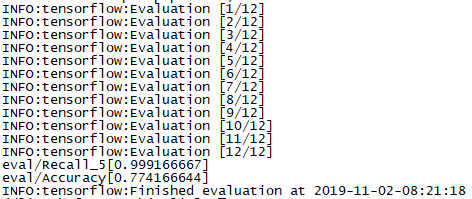
Accuracy表示模型的分类准确率,而Recall_5 表示Top 5 的准确率,即在输出的各类别概率中,正确的类别只要落在前5 个就算对。由于此处的类别数比较少,因此可以不执行Top 5 的准确率,换而执行Top 2 或者Top 3的准确率,只要在eval_image_classifier.py 中修改下面的部分就可以了:
# Define the metrics:
names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({
'Accuracy': slim.metrics.streaming_accuracy(predictions, labels),
'Recall_5': slim.metrics.streaming_recall_at_k(
logits, labels, 5),
})
7、导出模型
训练完模型后,常见的应用场景是:部署训练好的模型并对单张图片进行识别。此处提供了freeze_graph.py用于导出识别的模型,classify_image_inception_v3.py是使用inception_v3模型对单张图片进行识别的脚本。导出模型:TensorFlow Slim提供了导出网络结构的脚本export_inference_graph.py 。 首先在 slim 文件夹下运行指令:
python export_inference_graph.py
这个命令会在 satellite 文件夹中生成一个 inception_v3_inf_graph.pb 文件 。
注意: inception_v3 _inf _graph.pb 文件中只保存了Inception V3 的网络结构,并不包含训练得到的模型参数,需要将checkpoint 中的模型参数保存进来。方法是使用freeze_graph. py 脚本(在chapter_3 文件夹下运行):在 项目根目录 执行如下命令(需将10085改成train_dir中保存的实际的模型训练步数)
python freeze_graph.py
freeze_graph.py中部分参数解释如下
#–input_graph slim/satellite/inception_v3_inf_graph.pb。表示使用的网络结构文件,即之前已经导出的inception_v3 _inf_gr aph.pb 。
#–input_checkpoint slim/satallite/train_dir/model.ckpt-10085。具体将哪一个checkpoint 的参数载入到网络结构中。
# 这里使用的是训练文件夹train _d让中的第10085步模型文件。我们需要根据训练文件夹下checkpoint的实际步数,将10085修改成对应的数值。
#input_binary true。导入的inception_v3_inf_graph.pb实际是一个protobuf文件。而protobuf 文件有两种保存格式,一种是文本形式,一种是二进制形式。
# inception_v3_inf_graph.pb 是二进制形式,所以对应的参数是–input_binary true 。初学的话对此可以不用深究,若有兴趣的话可以参考资料。
#--output_node_names 在导出的模型中指定一个输出结点,InceptionV3/Predictions/Reshape_1是Inception_V3最后的输出层
#–output_graph slim/satellite/frozen_graph.pb。最后导出的模型保存为slim/satellite/frozen_graph.pb 文件
最后导出的模型文件如下:
三、预测图片
如何使用导出的frozen_graph.pb文件对单张图片进行预测?此处使用一个编写的文件classify_image_inception_v3.py 脚本来完成这件事 。先来看这个脚本的使用方法:
python classify_image_inception_v3.py
classify_image_inception_v3.py中部分参数解释如下
# 一model_path 很好理解,就是之前导出的模型frozen_graph. pb 。
# –label_path 指定了一个label文件, label文件中按顺序存储了各个类别的名称,这样脚本就可以把类别的id号转换为实际的类别名。
# –image _file 是需要测试的单张图片。
脚本的运行结果应该类似于:
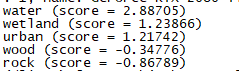
这就表示模型预测图片对应的最可能的类别是water,接着是wetland 、urban 、wood 等。score 是各个类别对应的Logit 。
四、TensorBoard 可视化与超参数选择
在训练时,可以使用TensorBoard 对训练过程进行可视化,这也有助于设定训练模型的方式及超参数。在slim文件夹下使用下列命令可以打开TensorBoard (其实就是指定训练文件夹):
tensorboard --logdir satellite/train_dir
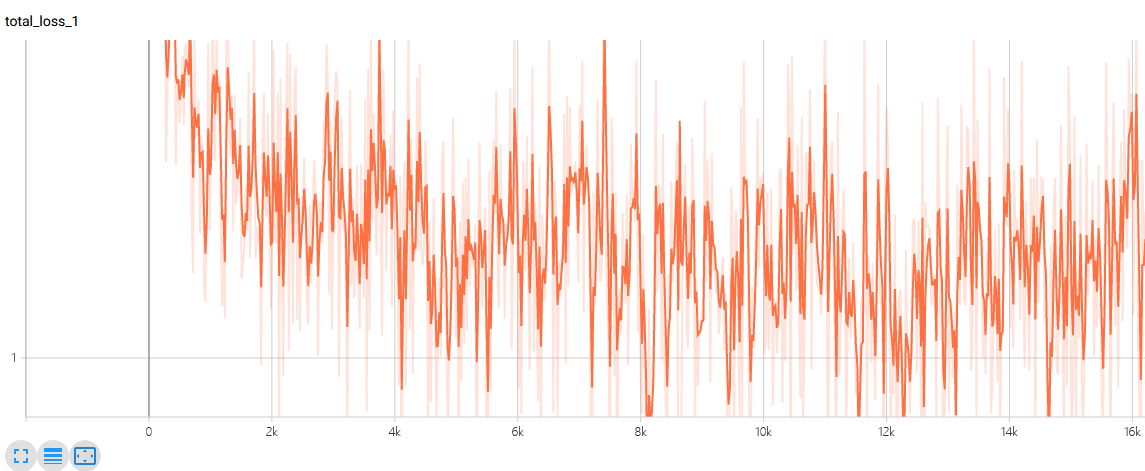
在TensorBoard中,可以看到损失的变化如上图 所示。观察损失曲线有助于调整参数。当损失曲线比较平缓,收敛较慢时,可以考虑增大学习率,以加快收敛速度;如果损失曲线波动较大,无法收敛,就可能是因为学习率过大,此时就可以尝试适当减小学习率。
另外,在上面的学习中,在笔者自己进行试验的过程中,一些小的错误就没有粘贴出来了,读者自行搜索即可得到解决方法。这篇博文主要来自《21个项目玩转深度学习》这本书里面的第三章,内容有删减,还有本书的一些代码的实验结果,经过笔者自己修改,已经能够完全成功运行。随书附赠的代码库链接为:https://github.com/hzy46/Deep-Learning-21-Examples。
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/11749786.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号