Spark学习之Spark调优与调试(一)
一、使用SparkConf配置Spark
对 Spark 进行性能调优,通常就是修改 Spark 应用的运行时配置选项。Spark 中最主要的配置机制是通过 SparkConf 类对 Spark 进行配置。当创建出一个 SparkContext 时,就需要创建出一个 SparkConf 的实例。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
// 创建一个conf对象
val conf = new SparkConf()
conf.set("spark.app.name", "My Spark App")
conf.set("spark.master", "local[4]")
conf.set("spark.ui.port", "36000") // 重载默认端口配置
// 使用这个配置对象创建一个SparkContext
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
}
}
Spark 允许通过 spark-submit 工具动态设置配置项。当应用被 spark-submit 脚本启动时,脚本会把这些配置项设置到运行环境中。当一个新的 SparkConf 被创建出来时,这些环境变量会被检测出来并且自动配好。这样,在使用spark-submit 时,用户应用中只要创建一个“空”的 SparkConf ,并直接传给 SparkContext的构造方法就行了。
spark-submit 工具为常用的 Spark 配置项参数提供了专用的标记,还有一个通用标记--conf 来接收任意 Spark 配置项的值。
$ bin/spark-submit \
--class com.example.MyApp \
--master local[4] \
--name "My Spark App" \
--conf spark.ui.port=36000 \
myApp.jar
spark-submit 也支持从文件中读取配置项的值。这对于设置一些与环境相关的配置项比较有用,方便不同用户共享这些配置(比如默认的 Spark 主节点)。默认情况下, spark-submit 脚本会在 Spark 安装目录中找到 conf/spark-defaults.conf 文件,尝试读取该文件中以空格隔开的键值对数据。你也可以通过 spark-submit 的 --properties-File 标记,自定义该文件的路径。
$ bin/spark-submit \
--class com.example.MyApp \
--properties-file my-config.conf \
myApp.jar
## Contents of my-config.conf ##
spark.master local[4]
spark.app.name "My Spark App"
spark.ui.port 36000
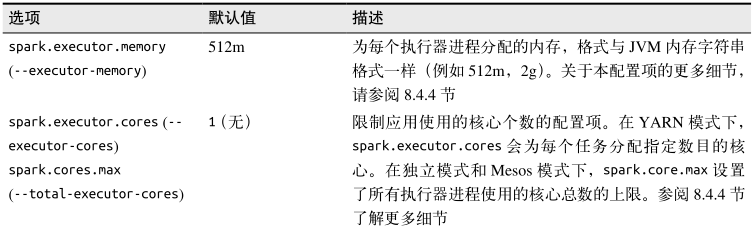
有时,同一个配置项可能在多个地方被设置了。例如,某用户可能在程序代码中直接调用了 setAppName() 方法,同时也通过 spark-submit 的 --name 标记设置了这个值。针对这种情况,Spark 有特定的优先级顺序来选择实际配置。优先级最高的是在用户代码中显式调用 set() 方法设置的选项。其次是通过 spark-submit 传递的参数,再次是写在配置文件中的值,最后是系统的默认值。 下表列出了一些常用的配置项。

二、Spark执行的组成部分:作业、任务和步骤
下面通过一个示例应用来展示 Spark 执行的各个阶段,以了解用户代码如何被编译为下层的执行计划。我们实现的是一个简单的日志分析应用。输入数据是一个由不同严重等级的日志消息和一些分散的空行组成的文本文件,我们希望计算其中各级别的日志消息的条数。

val input = sc.textFile("words.txt") // 读取输入文件
// 切分为单词并且删掉空行 如果大于0的话删除不掉空行
val tokenized = input.map(line=>line.split(" ")).filter(words=>words.size>1) //如果大于0的话删除不掉空行
val counts = tokenized.map(words=>(words(0),1)).reduceByKey((a,b)=>a+b) // 提取出日志等级并进行计数
这一系列代码生成了一个叫作 counts 的 RDD,其中包含各级别日志对应的条目数。在shell 中执行完这些命令之后,程序没有执行任何行动操作。相反,程序定义了一个 RDD对象的有向无环图(DAG),我们可以在稍后行动操作被触发时用它来进行计算。每个RDD 维护了其指向一个或多个父节点的引用,以及表示其与父节点之间关系的信息。比如,当你在 RDD 上调用 val b = a.map() 时, b 这个 RDD 就存下了对其父节点 a 的一个引用。这些引用使得 RDD 可以追踪到其所有的祖先节点。
Spark 提供了 toDebugString() 方法来查看 RDD 的谱系。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object Test {
def main(args: Array[String]): Unit = {
// 创建一个conf对象
val conf = new SparkConf()
conf.set("spark.app.name", "My Spark App")
conf.set("spark.master", "local[4]")
// conf.set("spark.ui.port", "36000") // 重载默认端口配置
// 使用这个配置对象创建一个SparkContext
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val input = sc.textFile("words.txt") // 读取输入文件
// 切分为单词并且删掉空行 如果大于0的话删除不掉空行
val tokenized = input.map(line=>line.split(" ")).filter(words=>words.size>1) //如果大于0的话删除不掉空行
val counts = tokenized.map(words=>(words(0),1)).reduceByKey((a,b)=>a+b) // 提取出日志等级并进行计数
println(input.toDebugString) // 通过toDebugString查看RDD的谱系
println("====================================================")
println(tokenized.toDebugString)
println("====================================================")
println(counts.toDebugString)
}
}
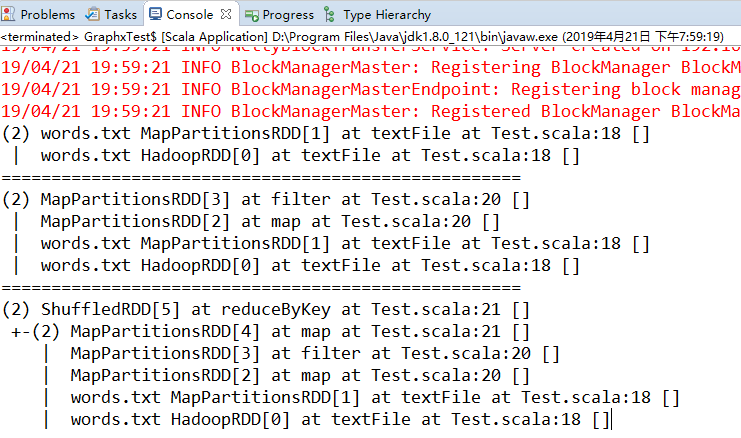
在调用行动操作之前,RDD 都只是存储着可以让我们计算出具体数据的描述信息。要触发实际计算,需要对 counts 调用一个行动操作,比如使用 collect() 将数据收集到驱动器程序中。
counts.collect().foreach(println)
Spark 调度器会创建出用于计算行动操作的 RDD 物理执行计划。我们在此处调用 RDD 的collect() 方法,于是 RDD 的每个分区都会被物化出来并发送到驱动器程序中。Spark 调度器从最终被调用行动操作的 RDD(在本例中是 counts )出发,向上回溯所有必须计算的 RDD。调度器会访问 RDD 的父节点、父节点的父节点,以此类推,递归向上生成计算所有必要的祖先 RDD 的物理计划。我们以最简单的情况为例,调度器为有向图中的每个RDD 输出计算步骤,步骤中包括 RDD 上需要应用于每个分区的任务。然后以相反的顺序执行这些步骤,计算得出最终所求的 RDD。
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/10747245.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号