一致性Hash算法
一、分布式算法
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin)、哈希算法(HASH)、最少连接算法(Least Connection)、响应速度算法(Response Time)、加权法(Weighted )等。其中哈希算法是最为常用的算法。
典型的应用场景是: 有N台服务器提供缓存服务,需要对服务器进行负载均衡,将请求平均分发到每台服务器上,每台机器负责1/N的服务。
常用的算法是对hash结果取余数 (hash() mod N ):对机器编号从0到N-1,按照自定义的 hash()算法,对每个请求的hash()值按N取模,得到余数i,然后将请求分发到编号为i的机器。但这样的算法方法存在致命问题,如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将当掉的服务器从算法从去除,此时候会有(N-1)/N的服务器的缓存数据需要重新进行计算;如果新增一台机器,会有N /(N+1)的服务器的缓存数据需要进行重新计算。对于系统而言,这通常是不可接受的颠簸(因为这意味着大量缓存的失效或者数据需要转移)。那么,如何设计一个负载均衡策略,使得受到影响的请求尽可能的少呢?
在Memcached、Key-Value Store 、Bittorrent DHT、LVS中都采用了Consistent Hashing算法,可以说Consistent Hashing 是分布式系统负载均衡的首选算法。
二、分布式缓存问题
在大型web应用中,缓存可算是当今的一个标准开发配置了。在大规模的缓存应用中,应运而生了分布式缓存系统。分布式缓存系统的基本原理,大家也有所耳闻。key-value如何均匀的分散到集群中?说到此,最常规的方式莫过于hash取模的方式。比如集群中可用机器适量为N,那么key值为K的的数据请求很简单的应该路由到hash(K) mod N对应的机器。的确,这种结构是简单的,也是实用的。但是在一些高速发展的web系统中,这样的解决方案仍有些缺陷。随着系统访问压力的增长,缓存系统不得不通过增加机器节点的方式提高集群的相应速度和数据承载量。增加机器意味着按照hash取模的方式,在增加机器节点的这一时刻,大量的缓存命不中,缓存数据需要重新建立,甚至是进行整体的缓存数据迁移,瞬间会给DB带来极高的系统负载,设置导致DB服务器宕机。 那么就没有办法解决hash取模的方式带来的诟病吗?
假设我们有一个网站,最近发现随着流量增加,服务器压力越来越大,之前直接读写数据库的方式不太给力了,于是我们想引入Memcached作为缓存机制。现在我们一共有三台机器可以作为Memcached服务器,如下图所示。
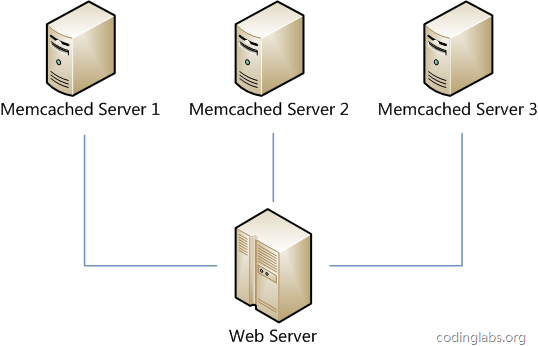
很显然,最简单的策略是将每一次Memcached请求随机发送到一台Memcached服务器,但是这种策略可能会带来两个问题:一是同一份数据可能被存在不同的机器上而造成数据冗余,二是有可能某数据已经被缓存但是访问却没有命中,因为无法保证对相同key的所有访问都被发送到相同的服务器。因此,随机策略无论是时间效率还是空间效率都非常不好。
要解决上述问题只需做到如下一点:保证对相同key的访问会被发送到相同的服务器。很多方法可以实现这一点,最常用的方法是计算哈希。例如对于每次访问,可以按如下算法计算其哈希值:
h = Hash(key) % 3
其中Hash是一个从字符串到正整数的哈希映射函数。这样,如果我们将Memcached Server分别编号为0、1、2,那么就可以根据上式和key计算出服务器编号h,然后去访问。
这个方法虽然解决了上面提到的两个问题,但是存在一些其它的问题。如果将上述方法抽象,可以认为通过:
h = Hash(key) % N
这个算式计算每个key的请求应该被发送到哪台服务器,其中N为服务器的台数,并且服务器按照0 – (N-1)编号。
这个算法的问题在于容错性和扩展性不好。所谓容错性是指当系统中某一个或几个服务器变得不可用时,整个系统是否可以正确高效运行;而扩展性是指当加入新的服务器后,整个系统是否可以正确高效运行。
现假设有一台服务器宕机了,那么为了填补空缺,要将宕机的服务器从编号列表中移除,后面的服务器按顺序前移一位并将其编号值减一,此时每个key就要按h = Hash(key) % (N-1)重新计算;同样,如果新增了一台服务器,虽然原有服务器编号不用改变,但是要按h = Hash(key) % (N+1)重新计算哈希值。因此系统中一旦有服务器变更,大量的key会被重定位到不同的服务器从而造成大量的缓存不命中。而这种情况在分布式系统中是非常糟糕的。
一个设计良好的分布式哈希方案应该具有良好的单调性,即服务节点的增减不会造成大量哈希重定位。一致性哈希算法就是这样一种哈希方案。
Hash 算法的一个衡量指标是单调性( Monotonicity ),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单 hash 算法 hash(object)%N 难以满足单调性要求。
三、 一致性哈希算法
3.1 算法简述
一致性哈希算法(Consistent Hashing Algorithm)是一种分布式算法,常用于负载均衡。Memcached client也选择这种算法,解决将key-value均匀分配到众多Memcached server上的问题。它可以取代传统的取模操作,解决了取模操作无法应对增删Memcached Server的问题(增删server会导致同一个key,在get操作时分配不到数据真正存储的server,命中率会急剧下降)。
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0 - (2^32)-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:
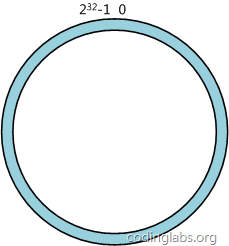
整个空间按顺时针方向组织。0和(2^32)-1在零点中方向重合。
下一步将各个服务器使用H进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如下:
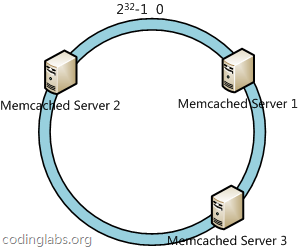
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有A、B、C、D四个数据对象,经过哈希计算后,在环空间上的位置如下:
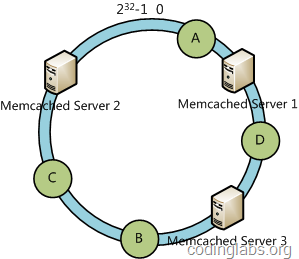
根据一致性哈希算法,数据A会被定为到Server 1上,D被定为到Server 3上,而B、C分别被定为到Server 2上。
3.2 容错性与可扩展性分析
下面分析一致性哈希算法的容错性和可扩展性。现假设Server 3宕机了:
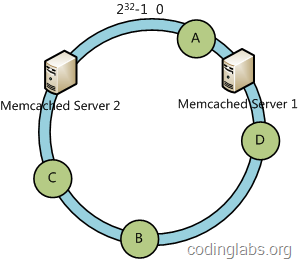
可以看到此时A、C、B不会受到影响,只有D节点被重定位到Server 2。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果我们在系统中增加一台服务器Memcached Server 4:
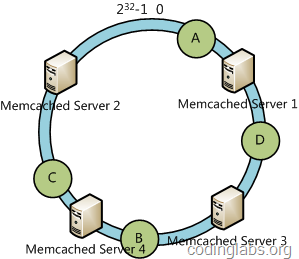
此时A、D、C不受影响,只有B需要重定位到新的Server 4。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即顺着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
3.3 虚拟节点
一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:
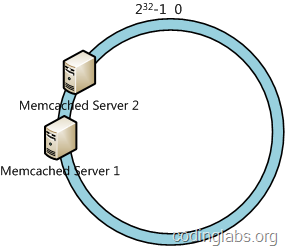
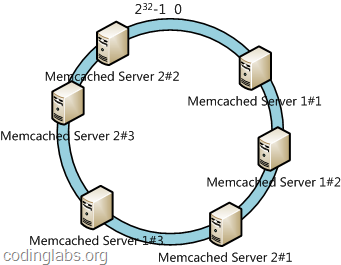
此时必然造成大量数据集中到Server 1上,而只有极少量会定位到Server 2上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Memcached Server 1#1”、“Memcached Server 1#2”、“Memcached Server 1#3”、“Memcached Server 2#1”、“Memcached Server 2#2”、“Memcached Server 2#3”的哈希值,于是形成六个虚拟节点:
四、Java代码实现
简化版本代码:


1 import java.nio.ByteBuffer; 2 import java.nio.ByteOrder; 3 import java.util.ArrayList; 4 import java.util.List; 5 import java.util.Map; 6 import java.util.SortedMap; 7 import java.util.TreeMap; 8 9 /*不考虑数据倾斜*/ 10 public class ConsistentHashing1 { 11 // hash算法,将关键字映射到2^32的环状空间里面 12 static long hash(String key) { 13 ByteBuffer buf = ByteBuffer.wrap(key.getBytes()); 14 int seed = 0x1234ABCD; 15 16 ByteOrder byteOrder = buf.order(); 17 buf.order(ByteOrder.LITTLE_ENDIAN); 18 19 long m = 0xc6a4a7935bd1e995L; 20 int r = 47; 21 22 long h = seed ^ (buf.remaining() * m); 23 24 long k; 25 while (buf.remaining() >= 8) { 26 k = buf.getLong(); 27 28 k *= m; 29 k ^= k >>> r; 30 k *= m; 31 32 h ^= k; 33 h *= m; 34 } 35 36 if (buf.remaining() > 0) { 37 ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN); 38 // for big-endian version, do this first: 39 // finish.position(8-buf.remaining()); 40 finish.put(buf).rewind(); 41 h ^= finish.getLong(); 42 h *= m; 43 } 44 45 h ^= h >>> r; 46 h *= m; 47 h ^= h >>> r; 48 49 buf.order(byteOrder); 50 return Math.abs(h); 51 52 } 53 54 // 机器节点==网络节点 55 static class Node implements HashNode { 56 String name; 57 String ip; 58 59 public Node(String name, String ip) { 60 this.name = name; 61 this.ip = ip; 62 } 63 64 @Override 65 public String toString() { 66 return this.name + "-" + this.ip; 67 } 68 69 @Override 70 public String getName() { 71 return name; 72 } 73 } 74 75 interface HashNode { 76 String getName(); 77 } 78 79 // 节点列表 80 List<Node> nodes; 81 TreeMap<Long, Node> hashAndNode = new TreeMap<>(); 82 TreeMap<Long, Node> keyAndNode = new TreeMap<>(); 83 84 public ConsistentHashing1(List<Node> nodes) { 85 this.nodes = nodes; 86 init(); 87 } 88 89 private void init() { 90 for (int i = 0; i < nodes.size(); i++) { 91 Node node = nodes.get(i); 92 long hash = hash(node.ip); 93 hashAndNode.put(hash, node); 94 } 95 } 96 97 private void add(String key) { 98 long hash = hash(key); 99 SortedMap<Long, Node> subMap = hashAndNode.tailMap(hash);// 找到map中key比fromKey大的所有的键值对,组成一个子Map 100 if (subMap.size() == 0) { 101 keyAndNode.put(hash, hashAndNode.firstEntry().getValue()); 102 } else { 103 Node node = subMap.get(subMap.firstKey());// 第一个节点,key应该归属的节点 104 keyAndNode.put(hash, node); 105 } 106 } 107 108 /** 109 * 增加一个新的机器节点 110 * 111 * @param newNode 112 */ 113 private void add(Node newNode) { 114 long hash = hash(newNode.ip); 115 hashAndNode.put(hash, newNode); 116 // 数据迁移 117 SortedMap<Long, Node> pre = hashAndNode.headMap(hash);// key小于hash的子map 118 if (pre.size() == 0) { 119 SortedMap<Long, Node> between = keyAndNode.subMap(0L, hash); 120 for (Map.Entry<Long, Node> e : between.entrySet()) { 121 e.setValue(newNode); 122 } 123 between = keyAndNode.tailMap(hashAndNode.lastKey()); 124 for (Map.Entry<Long, Node> e : between.entrySet()) { 125 e.setValue(newNode); 126 } 127 } else { 128 long from = pre.lastKey(); 129 long to = hash; 130 SortedMap<Long, Node> between = keyAndNode.subMap(from, to); 131 for (Map.Entry<Long, Node> e : between.entrySet()) { 132 e.setValue(newNode); 133 } 134 } 135 } 136 137 public static void main(String[] args) { 138 List<Node> nodes = new ArrayList<>(); 139 nodes.add(new Node("node1", "192.168.1.2")); 140 nodes.add(new Node("node2", "192.168.1.3")); 141 nodes.add(new Node("node3", "192.168.1.4")); 142 nodes.add(new Node("node4", "192.168.1.5")); 143 nodes.add(new Node("node5", "192.168.1.6")); 144 ConsistentHashing1 obj = new ConsistentHashing1(nodes); 145 for (Map.Entry<Long, Node> entry : obj.hashAndNode.entrySet()) { 146 System.out.println(entry.getKey() + ":" + entry.getValue().getName()); 147 } 148 obj.add("a"); 149 obj.add("b"); 150 obj.add("c"); 151 obj.add("e"); 152 obj.add("zhangsan"); 153 obj.add("lisi"); 154 obj.add("wangwu"); 155 obj.add("zhaoliu"); 156 obj.add("wangchao"); 157 obj.add("mahan"); 158 obj.add("zhanglong"); 159 obj.add("zhaohu"); 160 obj.add("baozheng"); 161 obj.add("gongsun"); 162 obj.add("zhanzhao"); 163 for (Map.Entry<Long, Node> entry : obj.keyAndNode.entrySet()) { 164 System.out.println(entry.getKey() + " ,归属到:" + entry.getValue().getName()); 165 } 166 System.out.println("==========="); 167 obj.add(new Node("node6", "192.168.1.77")); 168 for (Map.Entry<Long, Node> entry : obj.keyAndNode.entrySet()) { 169 System.out.println(entry.getKey() + " ,归属到:" + entry.getValue().getName()); 170 } 171 } 172 }
完整版代码:
1 import org.slf4j.Logger; 2 import org.slf4j.LoggerFactory; 3 4 import java.nio.ByteBuffer; 5 import java.nio.ByteOrder; 6 import java.util.*; 7 import java.util.ArrayList; 8 9 /** 10 * 一致性hash算法 11 */ 12 public class ConsistentHashing<N extends ConsistentHashing.HashNode> { // S类封装了机器节点的信息 13 // ,如name、password、ip、port等 14 private Logger logger = LoggerFactory.getLogger(getClass()); 15 private TreeMap<Long, N> vNodeAndRealNode; // 虚拟节点到真实节点的映射 16 private TreeMap<Long, N> keyAndRealNode; // key到真实节点的映射 17 private List<N> nodes = new java.util.ArrayList<N>(); // 真实机器节点 18 private final int V_NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数 19 boolean flag = false; 20 21 public ConsistentHashing(List<N> nodes) { 22 super(); 23 this.nodes = nodes; 24 init(); 25 } 26 27 public static void main(String[] args) { 28 // logger.debug(hash("w222o1d")); 29 // logger.debug(Long.MIN_VALUE); 30 // logger.debug(Long.MAX_VALUE); 31 Node s1 = new Node("s1", "192.168.1.1"); 32 Node s2 = new Node("s2", "192.168.1.2"); 33 Node s3 = new Node("s3", "192.168.1.3"); 34 Node s4 = new Node("s4", "192.168.1.4"); 35 Node s5 = new Node("s5", "192.168.1.5"); 36 List<Node> nodes = new ArrayList<>(100); 37 nodes.add(s1); 38 nodes.add(s2); 39 nodes.add(s3); 40 nodes.add(s4); 41 42 ConsistentHashing<Node> sh = new ConsistentHashing<>(nodes); 43 sh.keyToNode("101客户端"); 44 sh.keyToNode("102客户端"); 45 sh.keyToNode("103客户端"); 46 sh.keyToNode("104客户端"); 47 sh.keyToNode("105客户端"); 48 sh.keyToNode("106客户端"); 49 sh.keyToNode("107客户端"); 50 sh.keyToNode("108客户端"); 51 sh.keyToNode("109客户端"); 52 53 sh.deleteNode(s2); 54 55 sh.addNode(s5); 56 57 // logger.debug("最后的客户端到主机的映射为:"); 58 sh.printKeyTree(); 59 } 60 61 public void printKeyTree() { 62 logger.debug("当前映射信息为:"); 63 for (Iterator<Long> it = keyAndRealNode.keySet().iterator(); it.hasNext();) { 64 Long lo = it.next(); 65 logger.debug("hash(" + lo + ")连接到主机->" + keyAndRealNode.get(lo)); 66 } 67 68 } 69 70 private void init() { // 初始化一致性hash环 71 vNodeAndRealNode = new TreeMap<Long, N>(); 72 keyAndRealNode = new TreeMap<Long, N>(); 73 for (int i = 0; i != nodes.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点 74 final N shardInfo = nodes.get(i); 75 76 for (int n = 0; n < V_NODE_NUM; n++) 77 // 一个真实机器节点关联NODE_NUM个虚拟节点 78 vNodeAndRealNode.put(hash("SHARD-" + shardInfo.getName() + "-NODE-" + n), shardInfo); 79 } 80 } 81 82 // 增加一个主机 83 public void addNode(N s) { 84 logger.debug("增加主机" + s + "的变化:"); 85 for (int n = 0; n < V_NODE_NUM; n++) 86 addNode(hash("SHARD-" + s.getName() + "-NODE-" + n), s); 87 88 } 89 90 // 添加一个虚拟节点进环形结构,lg为虚拟节点的hash值 91 private void addNode(Long lg, N s) { 92 SortedMap<Long, N> tail = vNodeAndRealNode.tailMap(lg); 93 SortedMap<Long, N> head = vNodeAndRealNode.headMap(lg); 94 Long begin = 0L; 95 Long end = 0L; 96 SortedMap<Long, N> between; 97 if (head.size() == 0) { 98 between = keyAndRealNode.tailMap(vNodeAndRealNode.lastKey()); 99 flag = true; 100 } else { 101 begin = head.lastKey(); 102 between = keyAndRealNode.subMap(begin, lg); 103 flag = false; 104 } 105 vNodeAndRealNode.put(lg, s); 106 for (Iterator<Long> it = between.keySet().iterator(); it.hasNext();) { 107 Long lo = it.next(); 108 if (flag) { 109 keyAndRealNode.put(lo, vNodeAndRealNode.get(lg)); 110 logger.debug("hash(" + lo + ")改变到->" + tail.get(tail.firstKey())); 111 } else { 112 keyAndRealNode.put(lo, vNodeAndRealNode.get(lg)); 113 logger.debug("hash(" + lo + ")改变到->" + tail.get(tail.firstKey())); 114 } 115 } 116 } 117 118 // 删除真实节点是s 119 public void deleteNode(N s) { 120 if (s == null) { 121 return; 122 } 123 logger.debug("删除主机" + s + "的变化:"); 124 for (int i = 0; i < V_NODE_NUM; i++) { 125 // 定位s节点的第i的虚拟节点的位置 126 SortedMap<Long, N> tail = vNodeAndRealNode.tailMap(hash("SHARD-" + s.getName() + "-NODE-" + i)); 127 SortedMap<Long, N> head = vNodeAndRealNode.headMap(hash("SHARD-" + s.getName() + "-NODE-" + i)); 128 Long begin = 0L; 129 Long end = 0L; 130 131 SortedMap<Long, N> between; 132 if (head.size() == 0) { 133 between = keyAndRealNode.tailMap(vNodeAndRealNode.lastKey()); 134 end = tail.firstKey(); 135 tail.remove(tail.firstKey()); 136 vNodeAndRealNode.remove(tail.firstKey());// 从nodes中删除s节点的第i个虚拟节点 137 flag = true; 138 } else { 139 begin = head.lastKey(); 140 end = tail.firstKey(); 141 tail.remove(tail.firstKey()); 142 between = keyAndRealNode.subMap(begin, end);// 在s节点的第i个虚拟节点的所有key的集合 143 flag = false; 144 } 145 for (Iterator<Long> it = between.keySet().iterator(); it.hasNext();) { 146 Long lo = it.next(); 147 if (flag) { 148 keyAndRealNode.put(lo, tail.get(tail.firstKey())); 149 logger.debug("hash(" + lo + ")改变到->" + tail.get(tail.firstKey())); 150 } else { 151 keyAndRealNode.put(lo, tail.get(tail.firstKey())); 152 logger.debug("hash(" + lo + ")改变到->" + tail.get(tail.firstKey())); 153 } 154 } 155 } 156 157 } 158 159 // 映射key到真实节点 160 public void keyToNode(String key) { 161 SortedMap<Long, N> tail = vNodeAndRealNode.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点 162 if (tail.size() == 0) { 163 return; 164 } 165 Long virtualNodeKey = tail.firstKey(); 166 N realNode = tail.get(virtualNodeKey); 167 keyAndRealNode.put(hash(key), realNode); 168 logger.debug(key + "(hash:" + hash(key) + ")连接到主机->" + realNode); 169 } 170 171 /** 172 * MurMurHash算法,是非加密HASH算法,性能很高, 173 * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免) 174 * 等HASH算法要快很多,而且据说这个算法的碰撞率很低. http://murmurhash.googlepages.com/ 175 */ 176 private static Long hash(String key) { 177 178 ByteBuffer buf = ByteBuffer.wrap(key.getBytes()); 179 int seed = 0x1234ABCD; 180 181 ByteOrder byteOrder = buf.order(); 182 buf.order(ByteOrder.LITTLE_ENDIAN); 183 184 long m = 0xc6a4a7935bd1e995L; 185 int r = 47; 186 187 long h = seed ^ (buf.remaining() * m); 188 189 long k; 190 while (buf.remaining() >= 8) { 191 k = buf.getLong(); 192 193 k *= m; 194 k ^= k >>> r; 195 k *= m; 196 197 h ^= k; 198 h *= m; 199 } 200 201 if (buf.remaining() > 0) { 202 ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN); 203 // for big-endian version, do this first: 204 // finish.position(8-buf.remaining()); 205 finish.put(buf).rewind(); 206 h ^= finish.getLong(); 207 h *= m; 208 } 209 210 h ^= h >>> r; 211 h *= m; 212 h ^= h >>> r; 213 214 buf.order(byteOrder); 215 return h; 216 } 217 218 static class Node implements HashNode { 219 String name; 220 String ip; 221 222 public Node(String name, String ip) { 223 this.name = name; 224 this.ip = ip; 225 } 226 227 @Override 228 public String toString() { 229 return this.name + "-" + this.ip; 230 } 231 232 @Override 233 public String getName() { 234 return name; 235 } 236 } 237 238 interface HashNode { 239 String getName(); 240 } 241 242 }
参考链接:https://my.oschina.net/xianggao/blog/394545?fromerr=Df6BNkP4
本文来自博客园,作者:|旧市拾荒|,转载请注明原文链接:https://www.cnblogs.com/xiaoyh/p/10390568.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号