

querylist 在laravel框架中的简单采集数据(专业5)
安装querylist 插件
laravel 定时采集:
https://zhuanlan.zhihu.com/p/109741054
composer require jaeger/querylist
采集1:
//爬虫网站路由 Route::get('/querylist/list','querylistControllers@querylist');
//控制器

<?php namespace App\Http\Controllers; use App\models\querylistModel; use Illuminate\Http\Request; use QL\QueryList; class querylistControllers extends Controller { // public function querylist() { //1,要爬虫的网站 $url = "http://cms.querylist.cc/news/566.html"; //2获取网页的内容 $content = file_get_contents($url); // var_dump($content); //采集规则 $rules = [ 'title' => ['h1', 'text'], //文章的标题 'time'=>['span','text'],//文章的时间 ]; //采集的范围 $rang = '.post_title'; //采集的数据结果 $result = QueryList::get($url) ->rules($rules) ->range($rang)->query() ->getData() ->all(); // var_dump($result); $success=querylistModel::querylist($result); if ($success){ echo '采集成功'; }else{ echo '采集失败'; } } }
模型
class querylistModel extends Model { // protected $table='querylist'; public $primaryKey='id'; public $timestamps=false; public static function querylist($params){ return self::insert($params); } }
效果图:

采集2:
现代健康简易采集
laravel:控制器代码:
/** * * 数据数据抓取 * */ public function quertList() { //采集的网址 $url = 'http://www.rz-tea.com/'; $content = file_get_contents($url); //范围 $range = '.grid-item'; $rules = [ 'title' => ['.article-title', 'text'], 'img' => ['img', 'src'], ]; $data = QueryList::html($content)->range($range)->rules($rules)->queryData(); $result = DB::table('querylists')->insert($data); if ($result) { echo 'success'; } echo 'error'; }
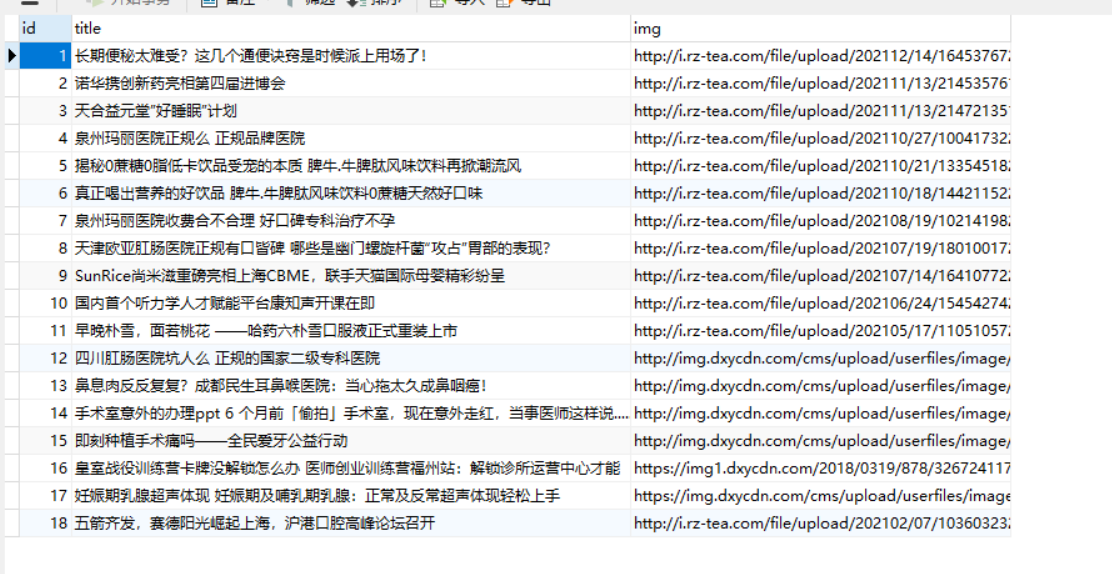
采集3:
/** * queryList 采集 *users:闫兵 *Data:2022/4/23 *Time:13:52 */ public function queryListData(){ //1,要爬虫的网站 $url = "http://www.guandian.cn/news/"; //2获取网页的内容 $content = file_get_contents($url); //采集规则 $rules = [ 'title' => [' a > h3', 'text'], //文章的标题 'source'=>[' #keyword > a ','text'],//文章来源 'image'=>['a > img','src'],//文章的图片 'content'=>['p','text'],//文章的内容 'created_at'=>['#keyword > span','text']//时间 ]; //采集的范围 $rang = 'li'; //采集的数据结果 $result = QueryList::get($url) ->rules($rules) ->range($rang) ->query() ->getData() ->all(); // 定义一个空的数组 $inserData=[]; foreach ($result as $key =>$value){ $inserData[$key]['title']=$value['title']; $inserData[$key]['source']=$value['source']; $inserData[$key]['image']=$value['image']; $inserData[$key]['content']=$value['content']; $inserData[$key]['created_at']=$value['created_at']; } $model=Factory::info(); $success=$model::insert($inserData); if ($success){ echo '采集成功'; }else{ echo '采集失败'; } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现