

GaussDB技术解读——存储引擎数据读取
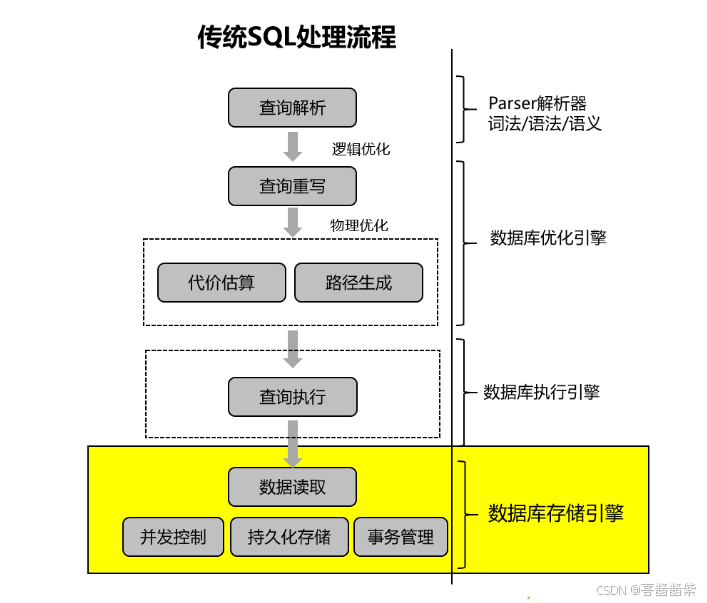
存储引擎主要实现高效存储数据确保数据库ACID(原子性、一致性、隔离性、持久性),正确并发读写、高性能读写等问题,从查询处理的视角通常执行算子Scan层调用存储引擎的数据读取接口进行数据读写,传统的存储引擎在查询处理的位置如下图
GaussDB包含多种存储模式,按照存储格式划分可分为行存储格式、列存储格式,其中前者,主要适合在线交易类型业务(OLTP)而后者主要适合数据分析类型业务 (OLAP),此外还包含PAX混合存储格式,目前商用数据库支持的不多,开源的如ORC, Parquet格式,主要也是用于OLAP场景。
存储引擎主要核心模块:
(1)数据页面缓存池:数据页面读写先从页面缓存里读取和修改,如果缓存里不存在,再从数据文件读取页面。
(2)堆表Heap:表数据存储格式和访问接口
(3)索引Index:高效查询表数据
(4)日志WAL: 修改数据页面,必须先写WAL日志(redo log), 事务提交之前和脏页写盘之前必须保证WAL日志持久化到存储设备。
(5)事务并发控制: 正确读写,高性能并发读写。
(6)事务提交日志: 事务状态和提交时间戳
(7)WAL日志恢复:从检查点日志往后回放WAL日志
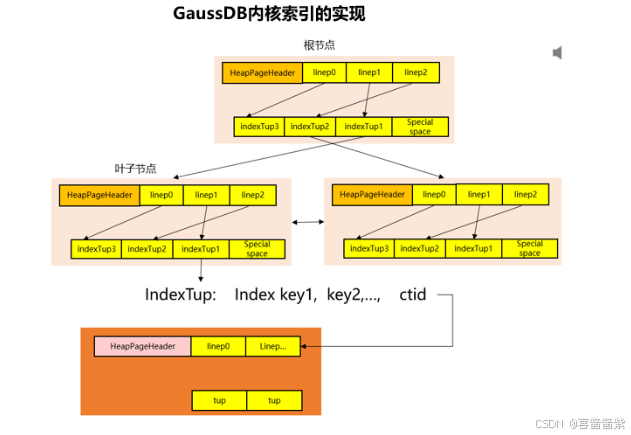
索引技术
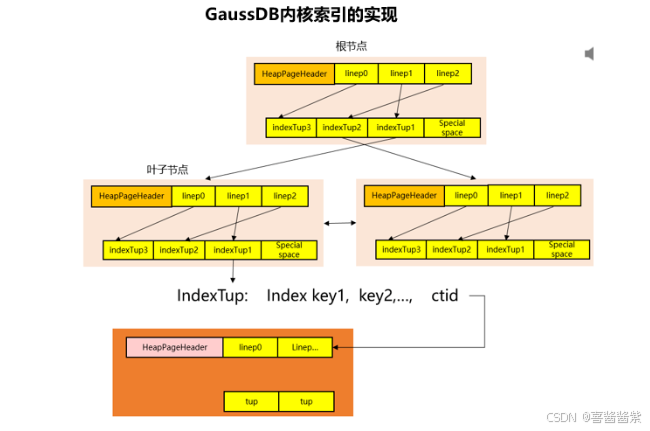
索引在数据库中的实现为B树结构,索引的键值按照B树进行排序,能够将索引键值的查找由线性查找优化成B树查找。
(1)对于非叶子节点,indexTup指向下一个节点,而对于叶子节点,indexTup指向堆表里的行
(2)Special space中,实现了两个指针,用于指向左右兄弟节点。
(3)索引元组有序,第一个叶子节点中indexTup3实际为最大健值索引元组,即high key,第二个叶子节点中IndexTup1跟indexTup3指向相同的堆表中的行。High key是为了减少比较次数。
数据页面缓冲区

数据页面缓冲池设计主要是为了减少磁盘的读写。读页面尽可能多的命中内存buffer page,减少磁盘读取页面, 写操作批量刷盘, 而不是每修改一条数据,就写数据页面。
(1)为了提高缓存命中率,设计缓存淘汰算法来保证频繁访问的热页面尽量在内存buffer里
(2)设计多个buffer pool用于缓存不同的对象,一方面为了减少冲突,同时也提高了缓存命中率
(3)对于批量导入和批量读取的场景, 为避免污染整个buffer pool, 顺序读取一遍表数据,把整个buffer pool里页面都淘汰。
设计buffer 批量读写获取策略,采用buffer ring的策略,固定范围的获取free buffer。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2022-11-28 1、MySQLDUMP 常用数据导入导出