

GaussDB技术解读——分布式优化器
GaussDB技术解读——分布式优化器
分布式数据库场景下表分布在各个节点上,数据的本地性Data Locality是分布式优化器中生成执行计划时重点考虑的因素,基于Share Nothing的分布式数据库中有一个很关键概念就是“移动数据不如移动计算”,之所以有数据本地性就是因为数据在网络中传输会有不小的I/O消耗,网络的overhead通常情况下会大于本地的计算,因此分布式数据库优化的一个重要的原则就是尽量减少这个网络I/O消耗就能够提升效率。例如有以下例子一个聚集查询的例子:
表信息:- T1: distribute By HASH(c1)执行查询:- select sum(c1), c2 from t1 group by c2
由于表T1的分布列为c1但实际上要按照c2为键值进行聚集,对聚集列进行重分布是不可避免的一步操作,因此先做聚集还是先做数据迁移重分布就成为分布式优化器的一个选项,针对这一情况可以有以下两种分布式执行计划选择:
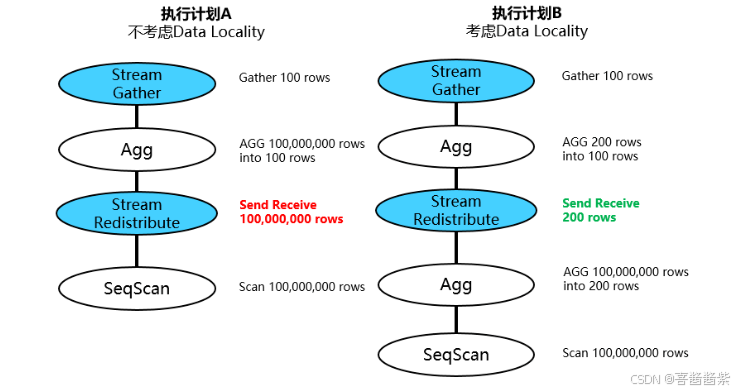
说明:
(1)执行计划A未考虑Data Locality的优化按照聚集的逻辑直接从扫描输出的100m元组进行重分布操作,造成大量的数据传输和网络资源消耗。
(2)执行计划B考虑Data Locality的优化,把AGG算子分解成2次AGG,其中第一次AGG在本地执行对原始数据进行缩减然后再通过网络重分布进入第二次AGG,虽说执行计划B相比A多了1个AGG算子,尽管计算的总量未发生变化但是节省了大量的网络IO操作,端到端提升了查询性能。
表关联也是类似的原理,如果当join列与分布列不一致时,需要网络stream节点算子对数据进行重分布或者复制确保查询执行的语义正确。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!