
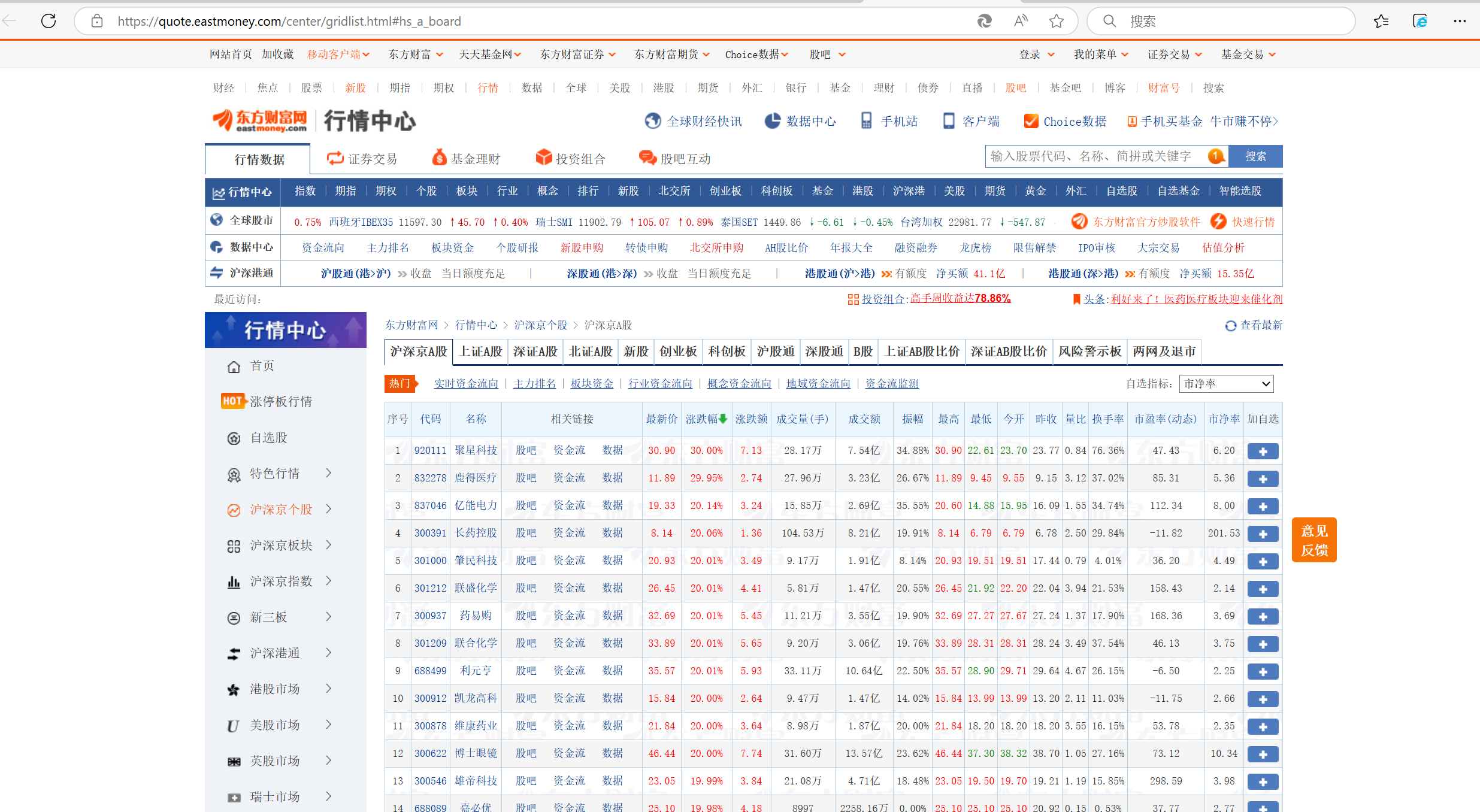
数据采集作业4
作业1
代码及图片:
点击查看代码
def spider(page_num):
cnt = 0
while cnt < page_num:
spiderOnePage()
driver.find_element(By.XPATH,'//a[@class="next paginate_button"]').click()
cnt +=1
time.sleep(2)

作业心得:
本次作业让我对 Selenium 和数据库交互有了更深入理解,同时也意识到处理超时异常和优化代码结构对程序稳定运行的重要性。
Gitee文件夹链接:点这里
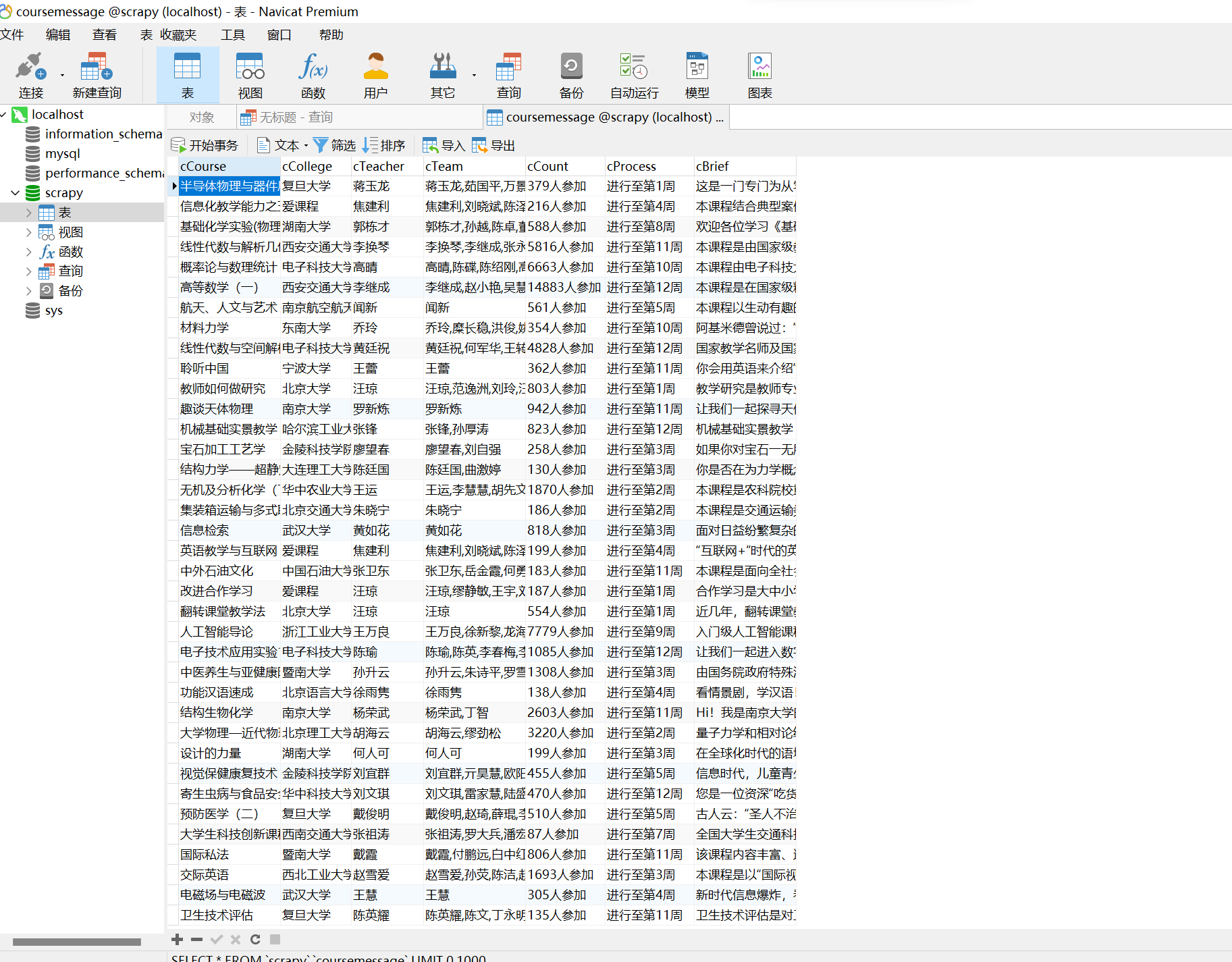
作业2
代码及图片:
点击查看代码
def spiderOnePage():
time.sleep(5) # 等待页面加载完成
courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')
current_window_handle = driver.current_window_handle
for course in courses:
cCourse = course.find_element(By.XPATH, './/h3').text # 课程名
cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 大学名称
cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 主讲老师
cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 参与该课程的人数
cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 课程进展
course.click() # 点击进入课程详情页,在新标签页中打开
Handles = driver.window_handles # 获取当前浏览器的所有页面的句柄
driver.switch_to.window(Handles[1]) # 跳转到新标签页
time.sleep(5) # 等待页面加载完成
# 爬取课程详情数据
# cBrief = WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'j-rectxt2'))).text
cBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
if len(cBrief) == 0:
cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')
cBrief = ""
for c in cBriefs:
cBrief += c.text
# 将文本中的引号进行转义处理,防止插入表格时报错
cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")
cBrief = cBrief.strip()
# 爬取老师团队信息
nameList = []
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
# 如果有下一页的标签,就点击它,然后继续爬取
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
while len(nextButton) != 0:
nextButton[0].click()
time.sleep(3)
cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')
for Teacher in cTeachers:
name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()
nameList.append(name)
nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')
cTeam = ','.join(nameList)
driver.close() # 关闭新标签页
driver.switch_to.window(current_window_handle) # 跳转回原始页面
try:
cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (
cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
except Exception as e:
print(e)
作业心得:
通过本次作业,我熟练掌握了 Selenium 框架的各项操作,如查找元素、模拟登录、爬取 Ajax 数据等,也进一步体会到结合 MySQL 存储爬取信息的便捷与实用。
Gitee文件夹链接:点这里
作业3
图片:
-
开通MapReduce服务:
![]()
-
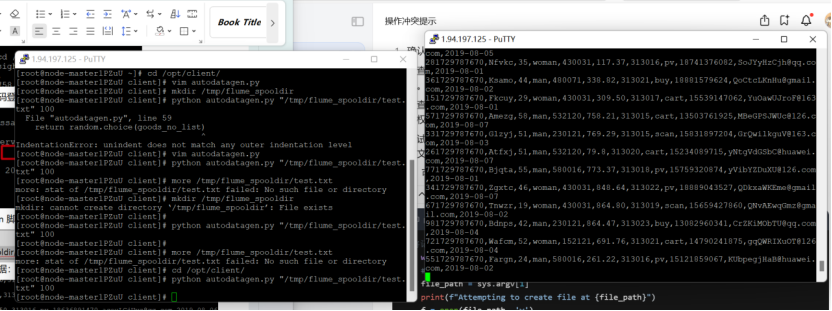
Python脚本生成测试数据:
![]()
-
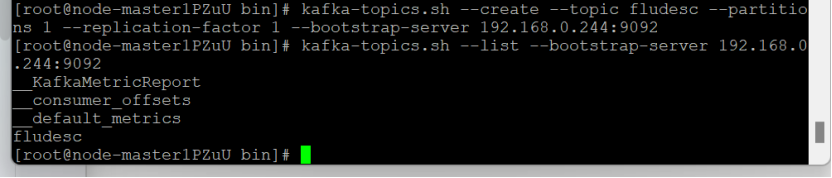
配置Kafka:
![]()
![]()
![]()
-
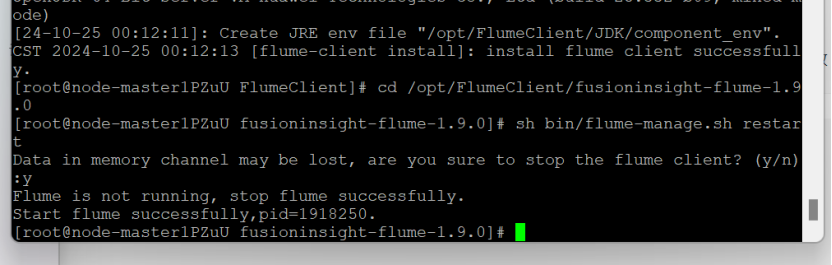
安装Flume客户端:
![]()
![]()
![]()
-
配置Flume采集数据:
![]()

本文来自博客园,作者:小鹿的博客,转载请注明原文链接:https://www.cnblogs.com/xiaoxolu/p/18542192

 浙公网安备 33010602011771号
浙公网安备 33010602011771号