
数据采集作业3
作业1
代码及图片:(这里只给出爬虫代码,settings.py等代码都在Gitee中)
点击查看代码
import scrapy
from Practical_work3.items import work1_Item
class Work1Spider(scrapy.Spider):
name = 'work1'
# allowed_domains = ['www.weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
img_datas = selector.xpath('//a/img/@src')
for img_data in img_datas:
item = work1_Item()
item['img_url'] = img_data.extract()
yield item
作业心得:
通过本次使用 Scrapy 框架爬取中国气象网图片的实践,我深刻体会到 Scrapy 在处理多线程爬取任务时的强大性能。单线程和多线程的实现方式对比明显,多线程显著提升了爬取效率。
同时,通过控制总页数和下载图片数量,我学会了如何有效地限制爬取范围,避免过度抓取资源。总体而言,Scrapy 框架不仅简化了爬虫开发流程,还提供了灵活的并发控制和数据处理机制,为后续的爬虫项目打下了坚实的基础。
Gitee文件夹链接:点这里
作业2
代码及图片:
点击查看代码
from typing import Iterable
import scrapy
from scrapy.http import Request
import re
import json
from Practical_work3.items import work2_Item
class Work2Spider(scrapy.Spider):
name = 'work2'
# allowed_domains = ['25.push2.eastmoney.com']
start_urls = ['http://25.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124021313927342030325_1696658971596&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696658971636']
def parse(self, response):
data = response.body.decode()
item = work2_Item()
data = re.compile('"diff":\[(.*?)\]',re.S).findall(data)
columns={'f2':'最新价','f3':'涨跌幅(%)','f4':'涨跌额','f5':'成交量','f6':'成交额','f7':'振幅(%)','f12':'代码','f14':'名称','f15':'最高',
'f16':'最低','f17':'今开','f18':'昨收'}
for one_data in re.compile('\{(.*?)\}',re.S).findall(data[0]):
data_dic = json.loads('{' + one_data + '}')
for k,v in data_dic.items():
item[k] = v
yield item
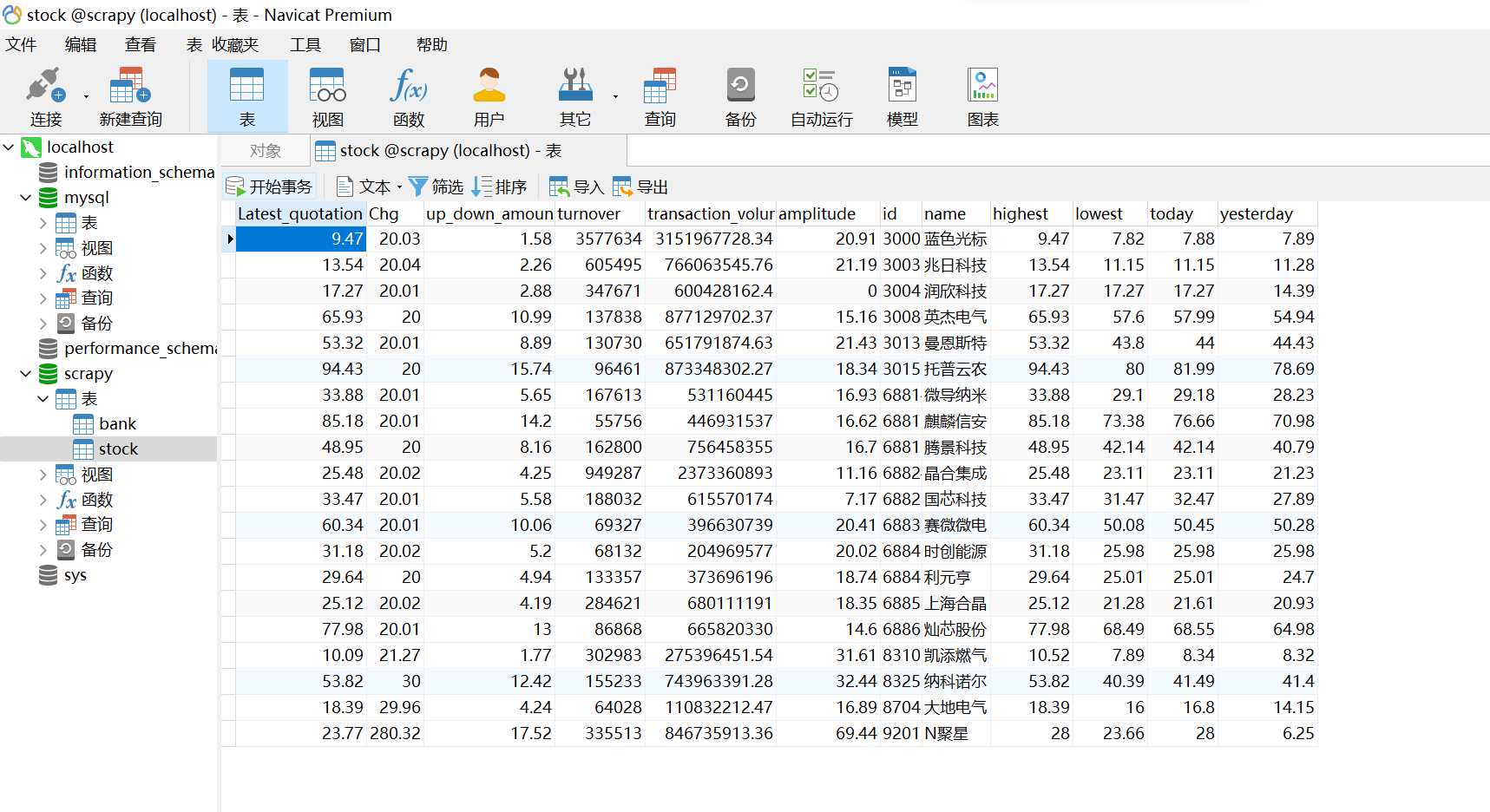
作业心得:
通过本次作业,我深入理解了Scrapy框架中Item和Pipeline的使用,特别是如何将爬取的数据通过Pipeline进行清洗、验证并存储到MySQL数据库中。
掌握XPath选择器在复杂HTML结构中提取所需信息的能力,使我能够高效地抓取东方财富网股票相关信息。整个过程不仅提升了我对数据爬取和存储技术的理解,也增强了我对Web数据处理流程的掌控能力。
Gitee文件夹链接:点这里
作业3
代码及图片:
点击查看代码
import scrapy
from Practical_work3.items import work3_Item
class Work3Spider(scrapy.Spider):
name = 'work3'
# allowed_domains = ['www.boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
data = response.body.decode()
selector=scrapy.Selector(text=data)
data_lists = selector.xpath('//table[@align="left"]/tr')
for data_list in data_lists:
datas = data_list.xpath('.//td')
if datas != []:
item = work3_Item()
keys = ['name','price1','price2','price3','price4','price5','date']
str_lists = datas.extract()
for i in range(len(str_lists)-1):
item[keys[i]] = str_lists[i].strip('<td class="pjrq"></td>').strip()
yield item
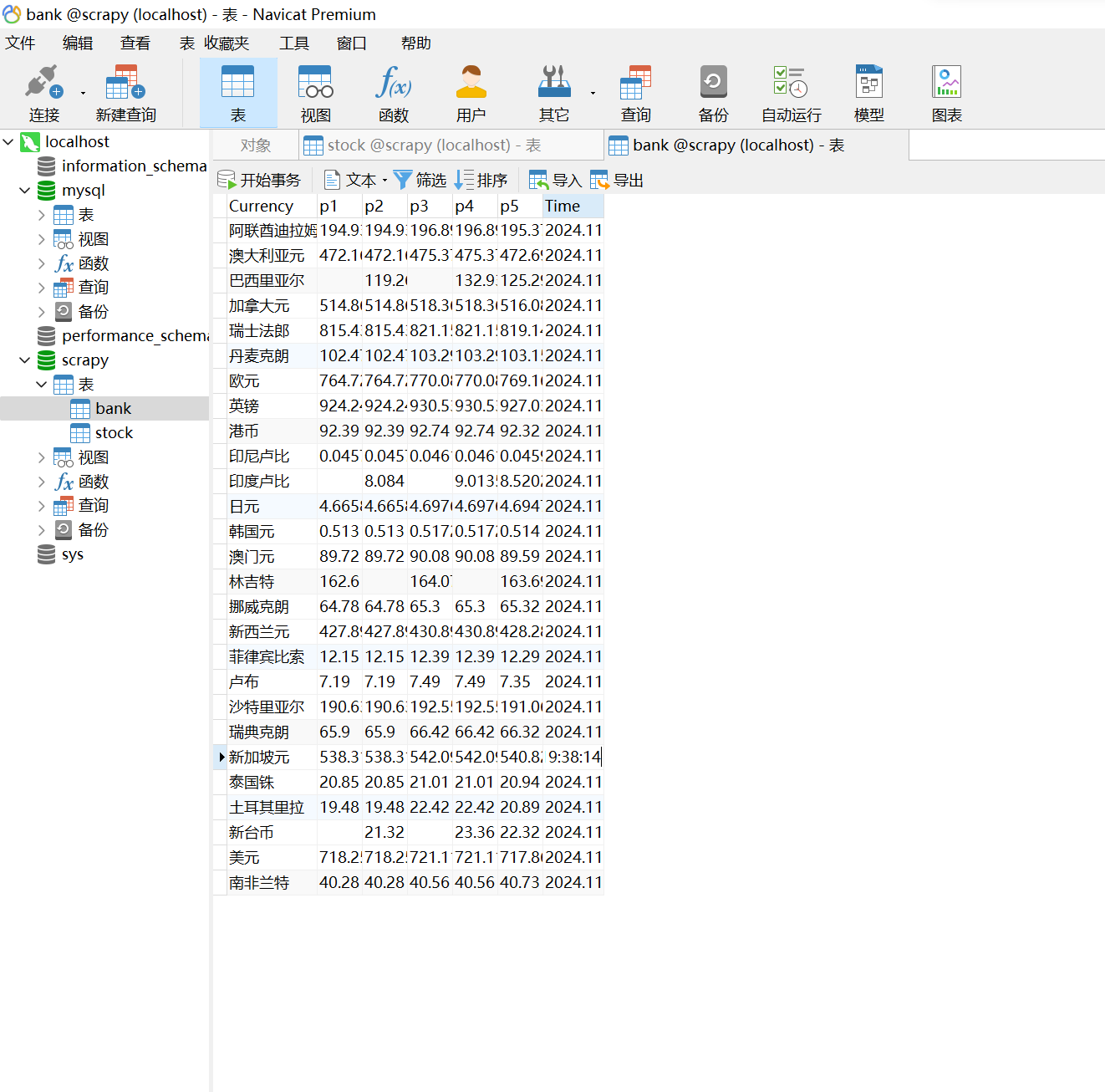
作业心得:
在完成本次作业的过程中,我深入学习了如何使用Scrapy框架结合XPath选择器来爬取中国银行的外汇牌价数据,并通过Pipeline将数据序列化后存储到MySQL数据库中。
通过这个项目,我不仅掌握了如何解析复杂的表格数据,还学会了如何处理多页数据抓取和存储的流程。这让我对Scrapy框架在实际数据抓取中的应用有了更全面的理解,并提升了我在数据存储和序列化方面的技能
Gitee文件夹链接:点这里
本文来自博客园,作者:小鹿的博客,转载请注明原文链接:https://www.cnblogs.com/xiaoxolu/p/18540549

 浙公网安备 33010602011771号
浙公网安备 33010602011771号