
数据采集作业2
作业1
代码及图片:
点击查看代码
def fetch_data(self, city):
if city not in self.cityCode.keys():
print(f"{city} code cannot be found")
return None
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
return dammit.unicode_markup
except Exception as err:
print(f"Error fetching data for {city}: {type(err).__name__} - {err}")
return None
def parse_data(self, data, city):
weather_data = []
if data is not None:
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
weather_data.append([city, date, weather, temp])
except Exception as err:
print(f"Error parsing data for {city}: {type(err).__name__} - {err}")
return weather_data
def forecastCity(self, city):
data = self.fetch_data(city)
return self.parse_data(data, city)
def process_and_export(self, cities, filename="weather_data.csv"):
all_weather_data = []
for city in cities:
city_weather_data = self.forecastCity(city)
all_weather_data.extend(city_weather_data)
# Write all data to CSV
with open(filename, 'w', newline='', encoding='utf-8') as csv_file:
writer = csv.writer(csv_file)
writer.writerow(["City", "Date", "Weather", "Temperature"]) # Write header
writer.writerows(all_weather_data) # Write data rows
print(f"Data successfully exported to {filename}")

作业心得:
这次作业,让我巩固了网络爬虫、HTML 解析和数据处理知识。
过程有挑战,如页面解析和异常处理,但通过分析页面结构和完善 try - except 块解决了。我收获满满,也为后续学习相关知识更添信心。
Gitee文件夹链接:点这里
作业2
过程:
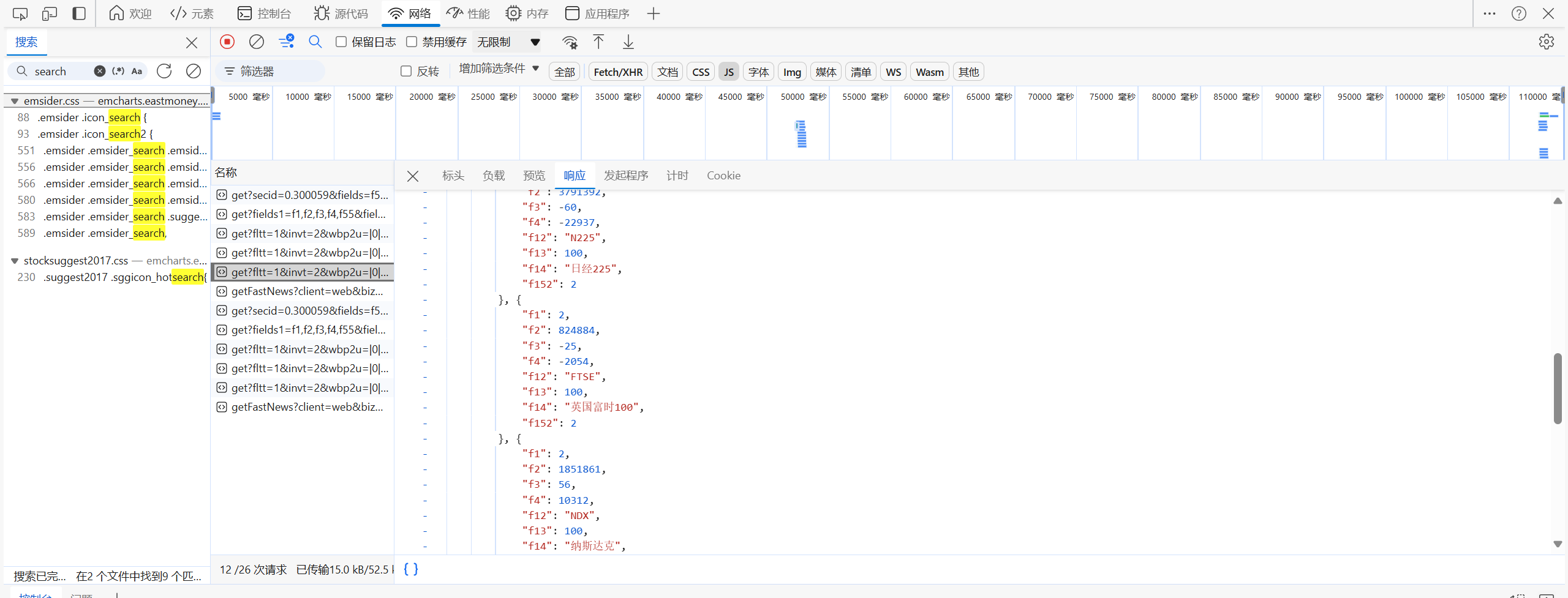
- 1.找到api:
![]()
- 2.找到cookie:
![]()
- 3.找到url:
![]()


代码及图片:
点击查看代码
# 发送请求获取数据的函数
def fetch_data(page_number):
url = f'https://1.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409952374347191637_1728983306168&pn={page_number}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_={1728983306169 + page_number}'
try:
response = requests.get(url, headers=headers, cookies=cookies)
return response
except Exception as err:
print(f"Error fetching data for page {page_number}: {type(err).__name__} - {err}")
return None
# 解析响应数据的函数
def parse_data(response):
if response and response.status_code == 200:
json_data = response.text
# 提取 JSON 格式的有效数据,去掉回调函数名称
json_data = json_data[json_data.index('(') + 1: -2] # 去掉回调函数的包裹
data = json.loads(json_data) # 解析 JSON 数据
return data
else:
print(f'Failed to parse data. Status code: {response.status_code if response else "None"}')
return None
# 翻页爬取数据的函数
def scrape_data(page_number):
response = fetch_data(page_number)
return parse_data(response)
# 爬取多页数据并存储到 DataFrame
def scrape_multiple_pages(max_pages=5):
all_data = [] # 用于存储所有页的数据
for page_number in range(1, max_pages + 1): # 从第一页开始,直到 max_pages
print(f"正在爬取第 {page_number} 页数据...")
data = scrape_data(page_number)
if data and 'data' in data and 'diff' in data['data']:
for stock in data['data']['diff']:
stock_info = {
'名称': stock.get('f14'), # 股票名称
'最新价': stock.get('f2'), # 最新价
'涨跌幅': stock.get('f3'), # 涨跌幅
'成交量(手)': stock.get('f4'), # 成交量(手)
'成交额': stock.get('f5'), # 成交额
'振幅': stock.get('f6'), # 振幅
'最高价': stock.get('f7'), # 最高价
'最低价': stock.get('f8') # 最低价
}
all_data.append(stock_info) # 将每条数据追加到列表中
else:
print(f"第 {page_number} 页没有数据或请求失败")
break # 如果某页没有数据,终止循环
return all_data
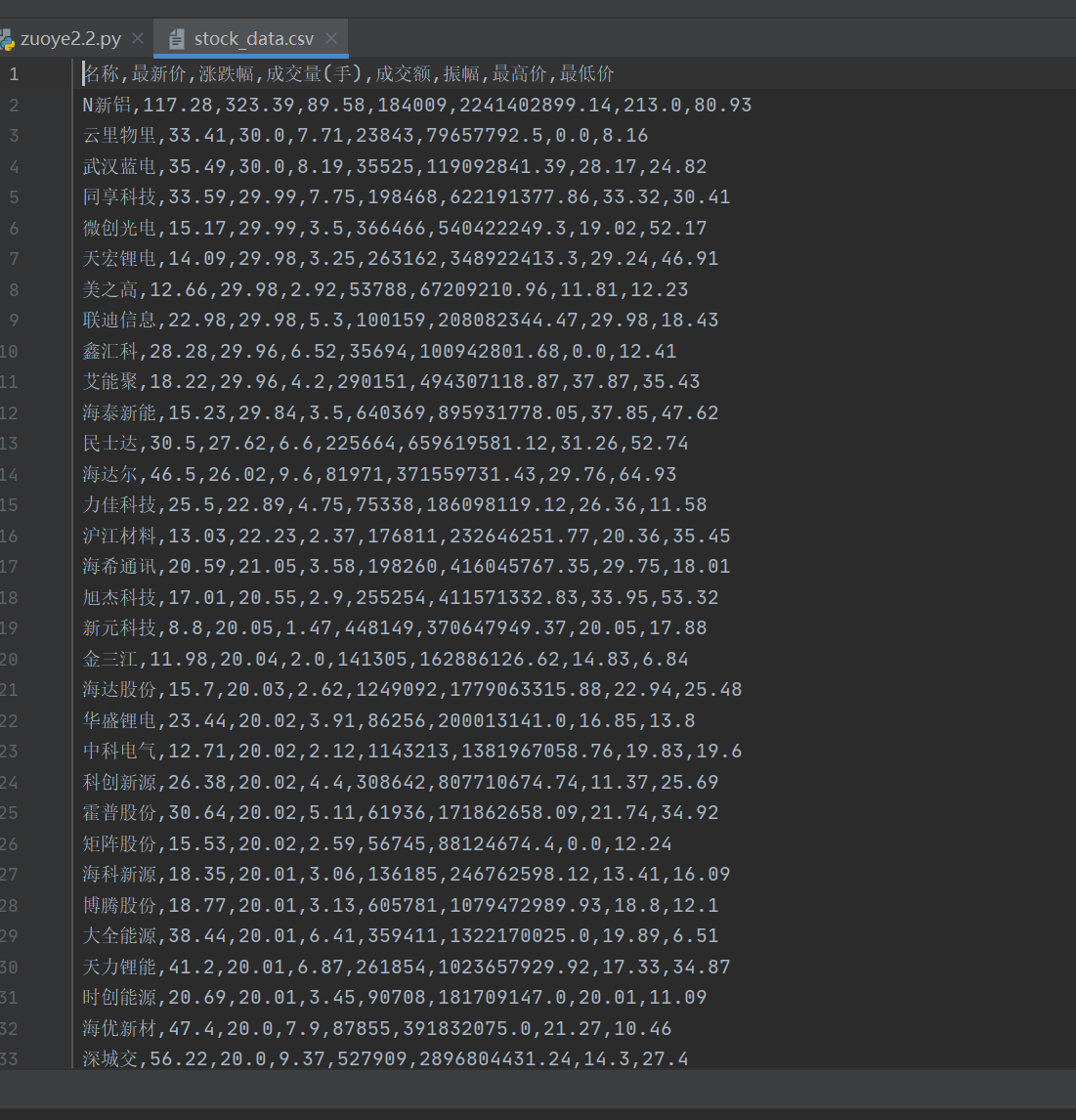
作业心得:
这次用 requests 和 BeautifulSoup 库爬取股票信息作业让我收获颇丰。在过程中深入实践了爬虫技术,提升了数据获取与分析能力,也体验了数据库交互。
虽遇到页面解析、API 参数理解和数据库存储问题,但通过努力都解决了,为后续学习积累了经验。
Gitee文件夹链接:点这里
作业3
过程:
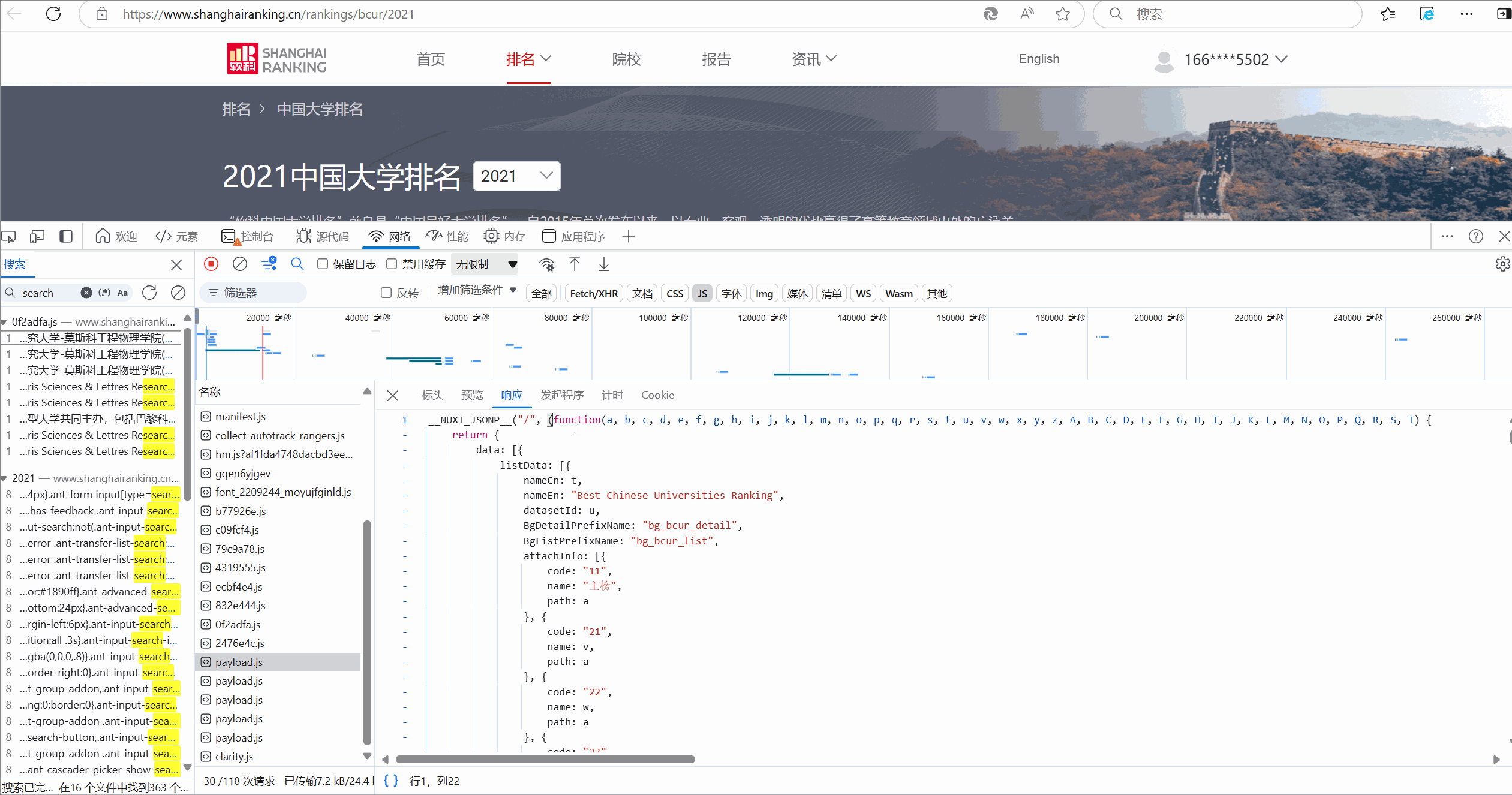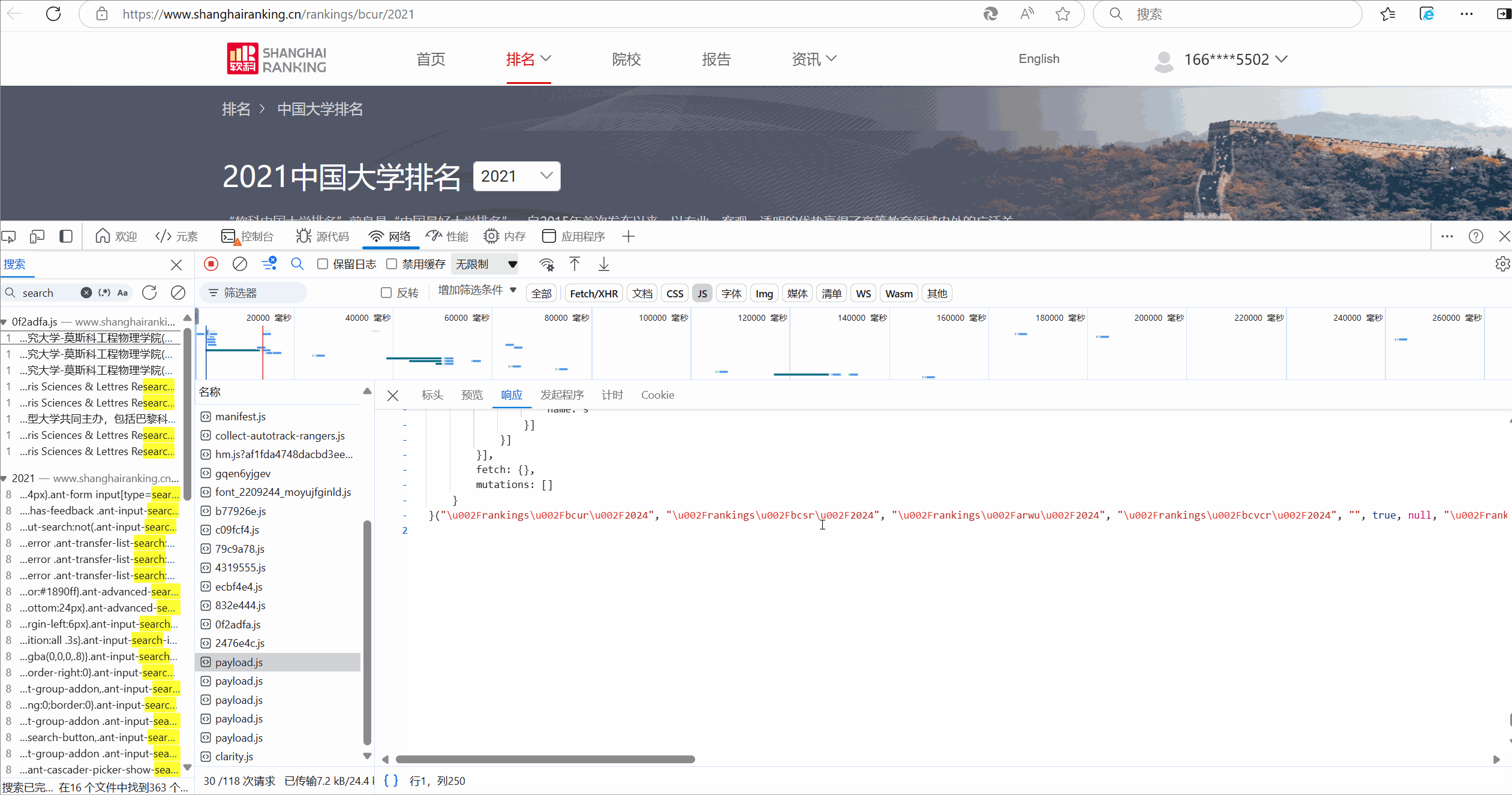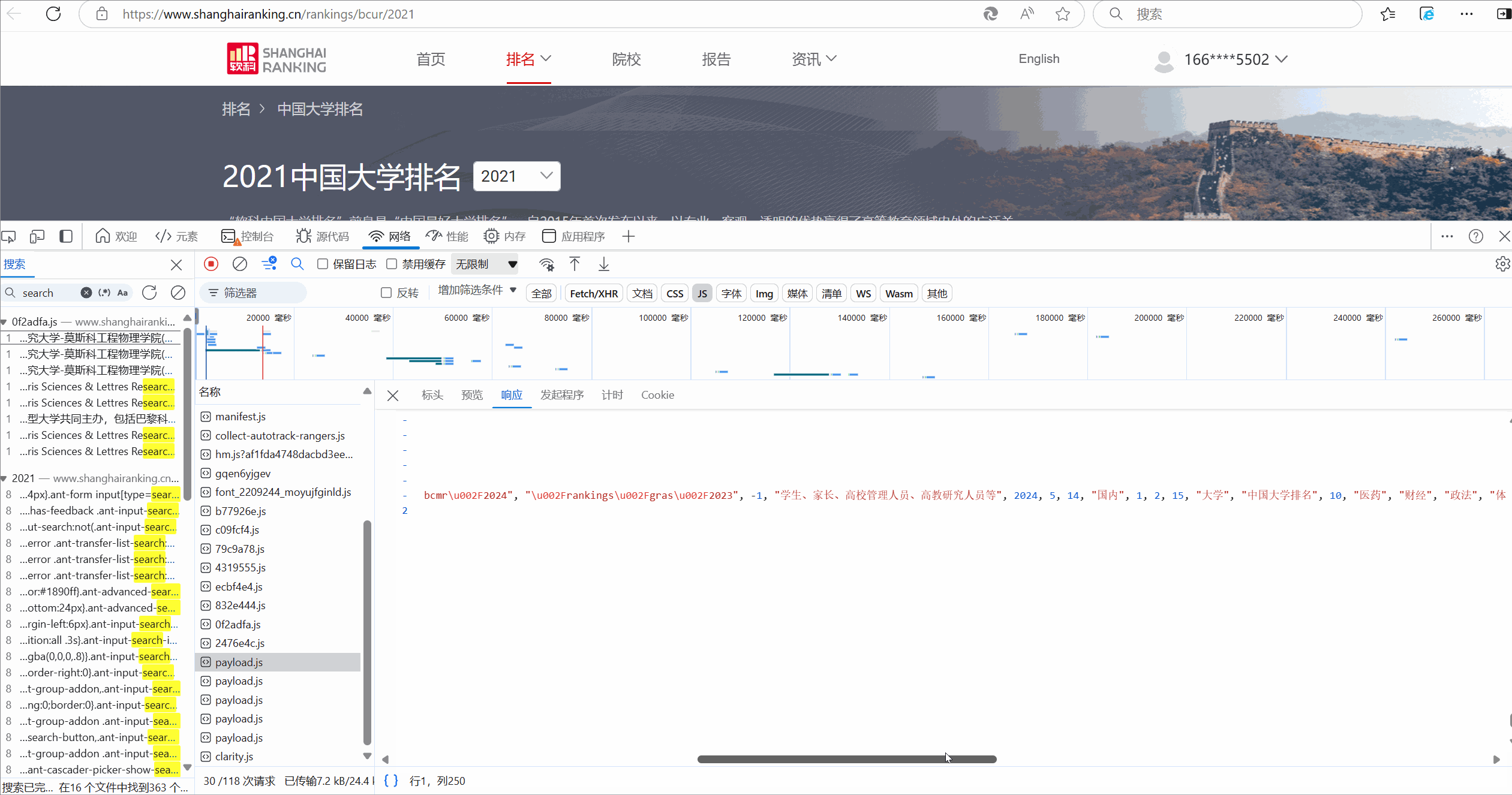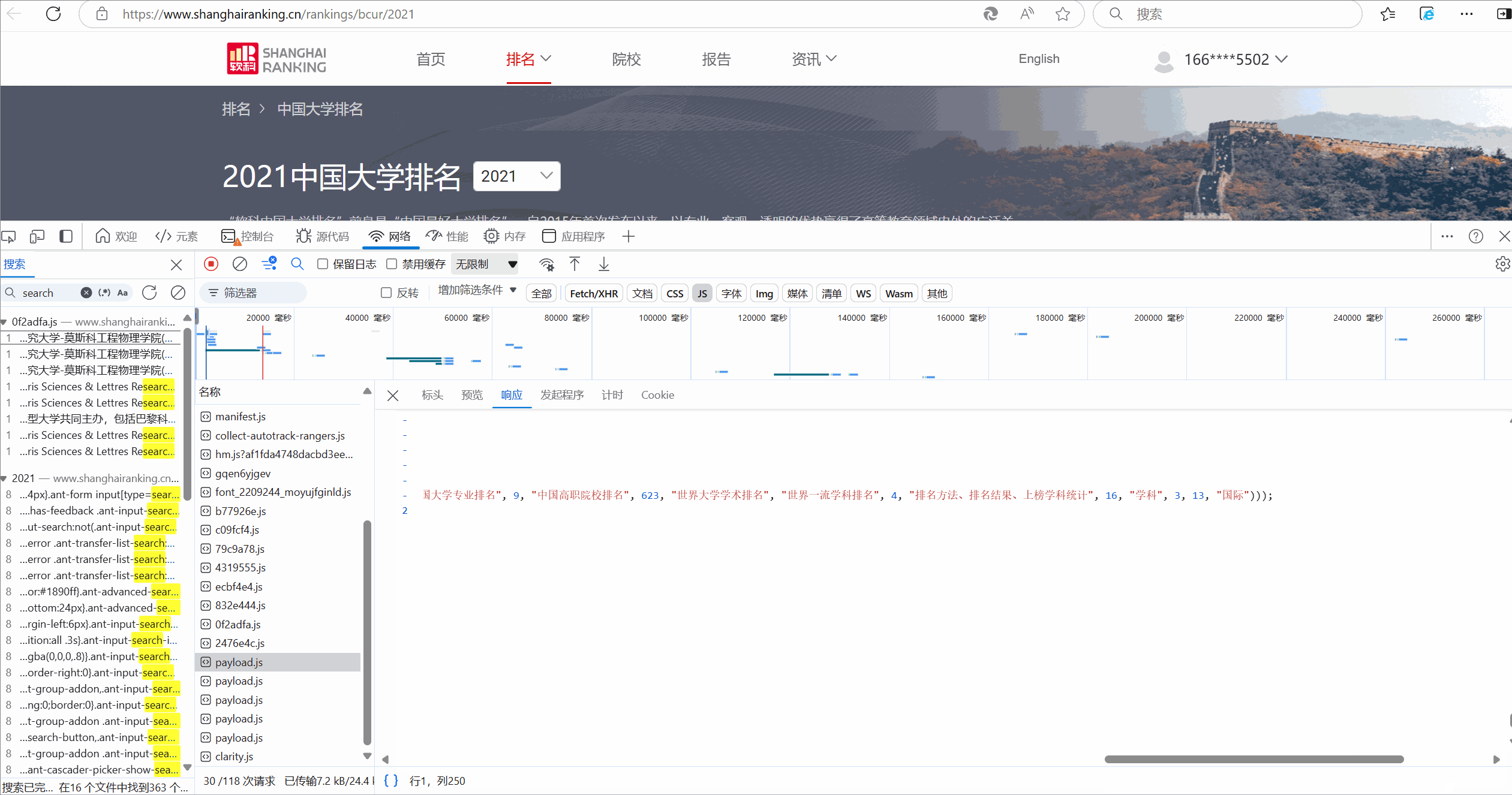
-
1.找到api:
![]()
-
2.分析api文件,显然,一些值被映射成码:
![]()

代码及图片:
点击查看代码
# 对 data2 中的每个元素进行映射
new_data2 = []
for item in data2:
result_dict = item.groupdict()
updated_result_dict = {}
for key, value in result_dict.items():
if key in ["type", "province", "ranking"]:
value = value.strip('"')
if value in dict:
updated_result_dict[key] = dict[value]
else:
updated_result_dict[key] = value
else:
updated_result_dict[key] = value
new_data2.append(updated_result_dict)
# 将 new_data2 赋值给 data2,实现永久改变
data2 = new_data2
# 现在无论在哪里输出 data2,都是映射后的结果
for item in data2:
print(item)
# 存储到文件里
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = list(data2[0].keys()) if data2 else []
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for item in data2:
writer.writerow(item)
作业心得:
在完成此次作业的过程中,我收获颇丰。分析网站的发包情况和获取数据的 API 是整个任务的关键所在。这让我深刻体会到理解网页数据获取机制的重要性,不能仅仅局限于看到的页面内容,还要深入挖掘背后的数据交互。
通过研究这些隐藏的信息,我学会了如何更精准地获取目标数据,这不仅是技术上的锻炼,更提升了我解决问题的思维能力。
同时,将调试分析过程录制成 Gif 加入博客这一要求,也让我重视起成果展示的完整性和直观性,更好地和他人分享自己的实践过程。
Gitee文件夹链接:点这里
本文来自博客园,作者:小鹿的博客,转载请注明原文链接:https://www.cnblogs.com/xiaoxolu/p/18504764

 浙公网安备 33010602011771号
浙公网安备 33010602011771号