
1.1.3-玩转Python3金融API应用-easyutils/__init__.py及stock.py和各种坑
__init__.py
看看easyutils文件夹内的__init__.py文件源代码:
# coding:utf8 from .timeutils import * from .stock import * __version__ = '0.1.6'
也就是从自己模块引入了timeutils子模块的全部内容,又从自己模块引入了stock子模块的全部内容。其版本是0.1.6版。注意引用自己的子模块时前面加上了一个“.”。
stock.py
stock.py子模块源代码详解
这个子模块的内部内容全部和股票相关。让我们把这一部分的代码分成多个部分来看。
# coding:utf8 import re import datetime import requests import io
这个部分很基础,显示了编码用utf-8(python3程序很多时候不是太需要写这一行),引入了正则表达式模块re,日期时间模块datetime,常用爬虫模块requests以及处理输入输出流(I/O, Input/Output)的模块io。
def get_stock_type(stock_code): """判断股票ID对应的证券市场 匹配规则 ['50', '51', '60', '90','110'] 为 sh ['00', '13', '18', '15','16', '18', '20', '30', '39', '115'] 为 sz ['5', '6', '9'] 开头的为 sh, 其余为 sz :param stock_code:股票ID, 若以 'sz', 'sh'开头直接返回对应类型,否则使用内置规则判断 :return 'sh' or'sz'""" assert type(stock_code) isstr, 'stock code need str type' if stock_code.startswith(('sh', 'sz')): return stock_code[:2] if stock_code.startswith(('50', '51', '60', '90', '110', '113', '132', '204')): return 'sh' if stock_code.startswith(('00', '13', '18', '15', '16', '18', '20', '30', '39','115', '1318')): return 'sz' if stock_code.startswith(('5','6', '9', '7')): return 'sh' return 'sz'
这个函数定义的内容就是前文提到的get_stock_type(stock_code)了。这是用来判断用户提供的股票代码(stock_code参数)在哪个交易所上市的函数。
从函数体中可以看到,注释内容之后先有一个assert xxx is yyy这样的判断句。在这个函数体中,assert命令用于判断stock_code的类型是不是str的。如果不是的话,返回'stock code need str type',也就是告诉使用者你输入的stock_code不是字符串格式。assert命令很有意思,值得大家学习。
随后的连续if判断就是用来检测输入的股票代码以判断其所在的交易所了。利用字符串的函数startwith来检测stock_code的开始部分(用tuple传入检测的多种可能),然后根据注释中所提的内容去安排返回什么值。
看到这里,你可能就会有一定程度自己的思考了。比如,这里的if判断或许中间写成elif的判断更好。因为这里只是判断一个stock_code的类别,而且if…elif…else的模式只要有一个成功了,后面的就会舍弃,理论上可以让程序运行快一点。
def get_code_type(code): """ 判断代码是属于那种类型,目前仅支持 ['fund', 'stock'] :return str 返回code类型, fund 基金 stock 股票 """ if code.startswith(('00','30', '60')): return 'stock' return 'fund'
这个函数定义的是get_code_type(code),即判断证券是什么类别的金融资产。当前仅支持股票’stock’和基金’fund’的区分。从函数体可以看到,如果代码开头是00、30或60的是股票,其余的代码都是基金。不过这里并没有做到对板块代码、B股、新三板等证券的代码进行区分,它会认为B股也是基金……所以这里应默认是A股的股票。这一点的BUG只有看源代码才能知道!
def get_all_stock_codes(): """获取所有股票ID""" all_stock_codes_url ='http://www.shdjt.com/js/lib/astock.js' grep_stock_codes =re.compile('~(\d+)`') response =requests.get(all_stock_codes_url) stock_codes =grep_stock_codes.findall(response.text) return stock_codes
这里是定义get_all_stock_codes(),也就是获取所有的沪深两市股票、基金和板块指数等代码。我运行这个代码之后发现返回的列表并没包括转债的数据等。想自己运行代码,就把这一段拷贝到自己电脑上的python3里面并直接执行就好了。从函数体中可以看出,这里使用了爬虫方法和正则表达式去提取想要的信息,最后返回的是“所有股票”代码的列表。
首先给出了爬取的网页http://www.shdjt.com/js/lib/astock.js,网页来自散户大家庭这个网站的js网页,这是通过抓包分析出来的。抓包方式请百度,主要通过各浏览器的开发者工具或者fiddler类专门的抓包工具。然后函数体描述了正则表达式匹配的样式。至于正则表达式,这是一个十分丰富且有用的内容,可以直接百度进行学习。然后就用到requests.get(url)的方式来抓取网页内容,最后通过re模块的findall功能对抓取到的网页文本中的证券数字代码进行分离,最终的stock_codes就是所有股票代码汇集成的一个列表。
截至2018年3月13日,stock_codes这个列表里面有5032个证券代码,这就说明这里面的内容除了00、30和60开头的股票外,还有B股、板块指数等其他股票或其他非个股内容。所以如果直接拿着这个列表里面的内容去应用get_code_type(code)函数的话,是可能会出错的。
def round_price_by_code(price, code): """ 根据代码类型[股票,基金] 截取制定位数的价格 :param price: 证券价格 :param code: 证券代码 :return: str 截断后的价格的字符串表示 """ if isinstance(price, str): return price typ = get_code_type(code) if typ == 'fund': return'{:.3f}'.format(price) return'{:.2f}'.format(price)
这个函数定义round_price_by_code(price,code),也就是针对不同的资产选取价格的小数位数。传入两个参数,一个是price证券价格,另一个是code证券代码。在国内A股市场,股票都是2位小数,而基金是3位小数的。这也是之前将证券代码区分为股票或者基金的意义吧。
根据函数体的内容,函数首先判断传输进来的价格(price)是不是str格式,如果是,函数直接返回字符串的price。如果不是字符串格式,则会跳过这个部分。这里如果传入的价格是字符串,直接返回字符串形式的price可能不太好。万一传入的price位数出现较多的非正常情况,结果返回可能就不太正常了。
然后函数体通过get_code_type(code)内容判断当前传入的代码是股票还是基金。这里如果只传入A股部分的证券代码就不会判断出错。判断结果(即’stock’或’fund’)会赋值给typ这个变量。
函数体最后的部分是根据传入的code类型(股票或者基金)来确定保留的小数位数。如果是基金,保留3位;如果是不是,保留2位。这里保留位数用的是format命令,四舍五入,可以自行百度了解其功能。另外str(round(price , 2))也能起到相同的效果。
def get_ipo_info(only_today=False): import pyquery
# 为了显示方便换下行(肖西耶注) response =requests.get('''http://vip.stock.finance.sina.com.cn/corp/go.php
/vRPD_NewStockIssue/page/1.phtml''',headers={'accept-encoding': 'gzip, deflate, sdch'}) html =response.content.decode('gbk') html_obj =pyquery.PyQuery(html) table_html =html_obj('#con02-0').html() import pandas as pd df =pd.read_html(io.StringIO(table_html), skiprows=3, converters={ '证券代码': str, '申购代码': str} )[0] if only_today: today =datetime.datetime.now().strftime('%Y-%m-%d') df = df[df['上网发行日期↓'] ==today] return df
这里定义函数get_ipo_info(only_today=False),初始参数only_today是False值,通过阅读函数体发现,这里only_today参数是用于确定爬取上网发行日期的日期是不是仅限于今天。如果这里函数不给任何参数,那么就默认为only_today为False,那么就会爬取全表所有将或已经上网发行的股票IPO信息。关于股票IPO及打新的相关信息请自行百度。
首先导入pyquery模块。这个模块能应用CSS选择器(selector)来获取所需要的信息。类似CSS选择器功能的模块有lxml,这是应用Xpath来工作的模块。关于CSS和Xpath的语法,请各位百度进行学习,这和学习正则表达式一样,需要一段时间来记忆。
然后就是爬虫套路requests.get,网址是新浪的:
http://vip.stock.finance.sina.com.cn/corp/go.php/vRPD_NewStockIssue/page/1.phtml
这里用了headers来获取网页信息。然而有的时候你直接把这个函数拿来尝试的话,你会发现程序卡住了。这说明一定是程序的问题吗?不一定!我此前有时候直接运行requests.get(url, headers)的话会卡住,曾经一度百思不得其解。后来我才想到我现在在美国……通过访问国内的云服务器,发现在位于国内的云服务器上果然可以轻松打开这个程序。这就说明,这里如果不对源代码进行测试的话,很可能我在用这个模块的时候对遭遇的卡顿束手无策。——因此在实际应用这个包的时候,我不会使用这个函数。当然,当我回国之后我就可以使用这个函数了。
相较于上面的情况,当我回国之后,如果我需要登录境外网站时,很可能会遇到和现在一样的问题(被墙了)。届时可能我可能就需要搞一个位于境外的云服务器了,或者选择能够直接打开的网址获取数据……
接下来函数体对获取的网页内容用'gbk'方式进行解码,将网页内容解码出中文。一些情况下,bytes类型的字节流在python3中使用gbk是能解读出中文的,而utf-8是做不到的。
然后,利用pyquery的PyQuery类将html解析为css语法可以操作的内容,再通过css语法提取出网页中的表格。(请自行学习css语法)
此时,引入pandas模块并命名为pd。pandas模块可以用来专业处理表格。利用pd.read_html,配合io模块的StringIO命令,跳过3行,提取出证券代码和申购代码。提出的内容是一个列表。将列表序号为0的项赋值给df。
如果一开始传入函数的only_today为False(无论是你赋值的False还是一开始没有传入参数),那么函数体就会直接返回df。否则,当only_today为True时,函数体会获取函数当时运行的日期并通过strftime函数改成'%Y-%m-%d'格式(即类似’2018-03-13’),然后提取出df中关于函数体当天的网上IPO信息,赋值给df最终返回。
如果你能打开这个新浪的网址的话,你看到的返回信息量是很大的,类似这样:
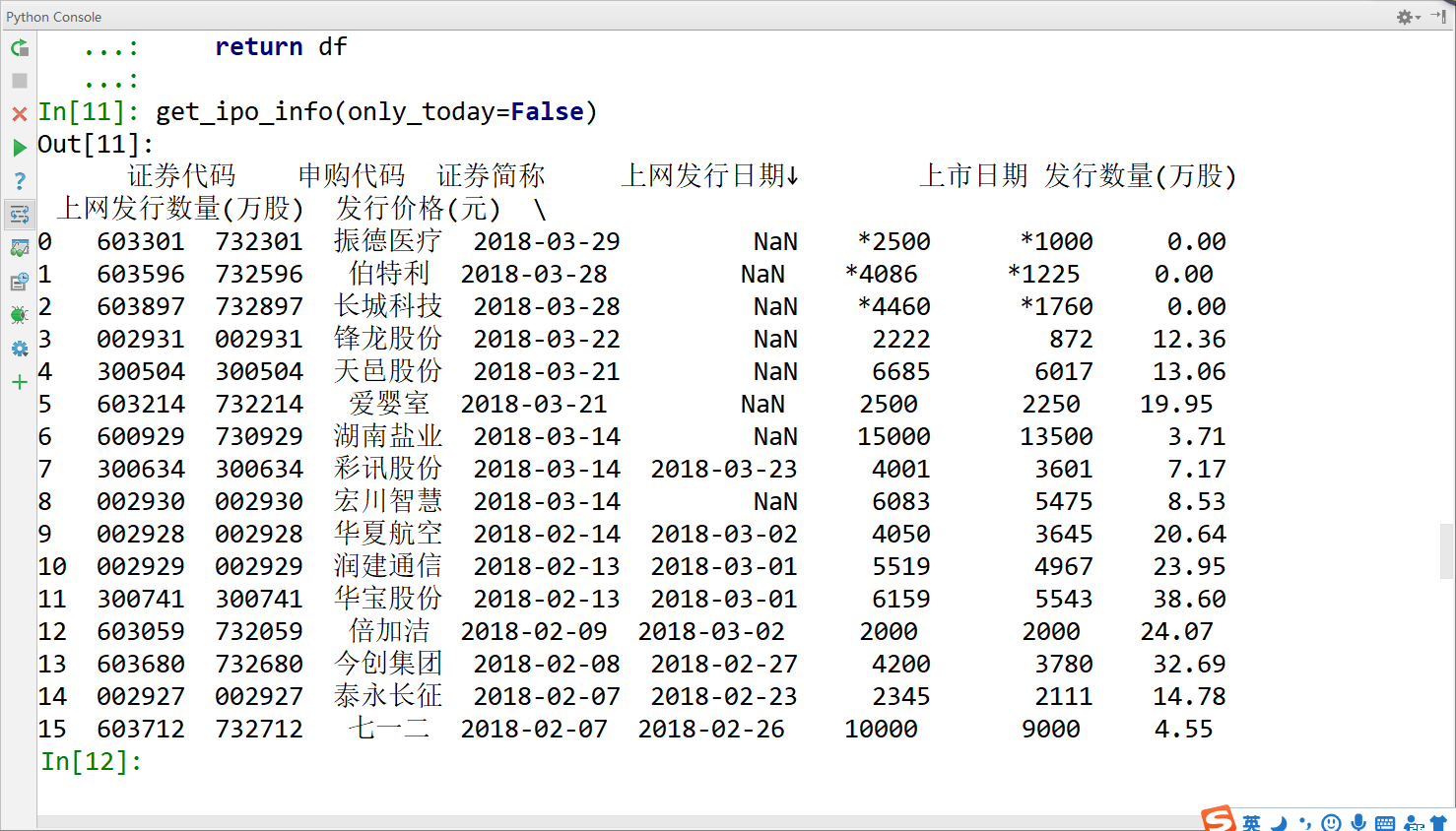
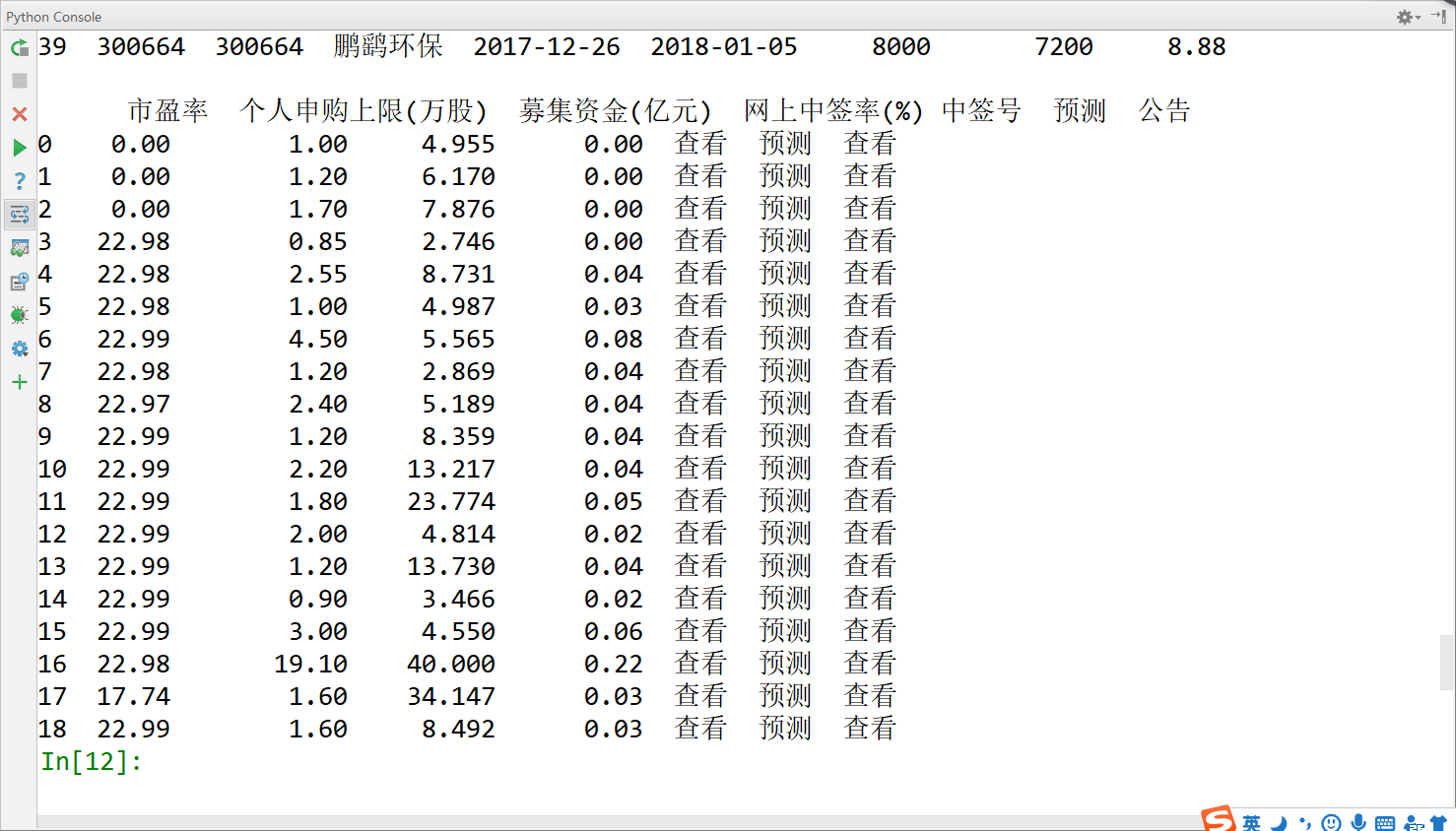
由于有时候我无法直接访问这个新浪的网址,因此我需要自行解决这个问题。
如果是我的话,我会尝试使用东方财富的数据,因为其数据在美国也是很方便就能够打开的:
http://data.eastmoney.com/xg/xg/default.html
可以发现,在用gbk编码后,文本中defjson里面的data就是我们需要的数据。博主的正则功力很弱,所以就想了其他办法,如果有大神,欢迎提供方案!最后遍历打印用了制表符\t,这样打印出来可以好看些。
我这里只考虑输出股票名称和申购日期:
def get_ipo_info(): # 从东方财富网新股日历中爬取 r = requests.get('http://data.eastmoney.com/xg/xg/default.html') # 对于字节流,用gbk方式编码 r.encoding = "gbk" # 将编码后的str格式网页信息存入wenben wenben = r.text # 由于博主的正则功底很弱,所以就考虑土办法了 # 最近data:的位置 start = wenben.find('data:', wenben.find('defjson')) + 5 # data最后的符号 end = wenben.find('param:', wenben.find('defjson')) data = wenben[start:end].strip()[:-2] # 此时获得的data是str格式的json,可以转为python了 data_python = json.loads(data) # 此时的data_python是一个列表,列表中的每一个元素是一个字典 # 包含上市新股的各种信息。我们只需要遍历股票的名字和日期就可以了 # 其中securityshortname是股票名称,purchasedate是申购日期 # 循环打印,用制表符\t让打印出来的列表好看点。 for i in data_python: name = i['securityshortname'] purchase_date = i['purchasedate'][:10] print(name + '\t' + purchase_date)
输出结果的一部分为:
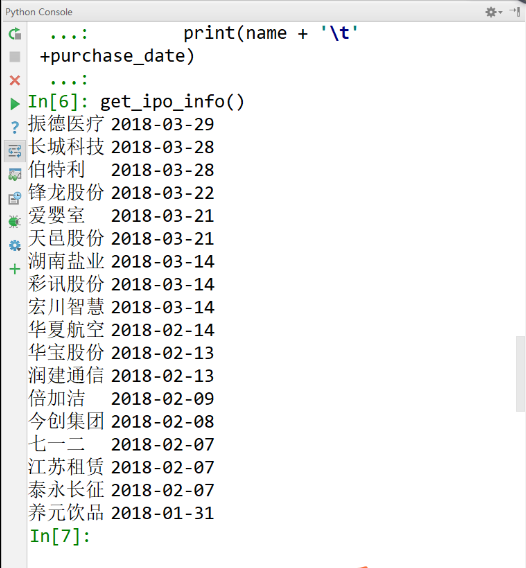
stock.py子模块函数总结
stock.py子模块所包含的所有函数及大致功能如下:
get_stock_type(stock_code):判断证券ID(stock_code)对应的证券市场。
get_code_type(code):判断证券代码(code)属于哪种金融资产。只有输入代码是A股证券代码才能保证正确——读取源代码才能发现。
get_all_stock_codes():获取所有的证券ID。但是获取的ID中却没有包括东财转债这样的转债,因此也不是全部证券。事实上,这个列表里面也不全是股票,还包括一系列板块指数。所以直接从这个列表中拿证券代码去get_code_type(code)判断的话会出错的。
round_price_by_code(price, code):根据证券代码(code)的金融资产类别对证券价格(price)按照报价小数点位进行四舍五入。股票是2位小数,基金是3位小数。由于这个函数用到了get_code_type(code),所以code必须是A股证券代码。
get_ipo_info(only_today=False):获取网上ipo打新的信息。——这个函数访问的新浪新股日历有时候打不开(针对在国外的情况),导致函数卡死。
看完这个模块的代码之后,不知道大家感觉如何?那么,下期咱们来讲easyutils包的timeutils.py模块。
