
在 ubuntu21.04 上使用 kubeadm 安装单机 kubenetes 笔记
系统:ubuntu21.04
虚拟机:两台(每台 2CPU、2G 内存)
安装 master
安装运行时(runtime)
sudo apt install docker.io
编辑 /etc/docker/daemon.json,配置 registry-mirrors 和 live-restore:
{
"registry-mirrors": ["https://alzgoonw.mirrors.aliyuncs.com"],
"live-restore": true
}当 docker 守护进程终止时,会关闭正在运行的 docker 容器。从 Docker Engine1.12 开始,可以配置 live-restore 是容器在守护进程终止时依然保持运行。
启动 docker
systemctl daemon-reload
systemct start docker
systemctl enable docker
把当前用户添加到 docker 用户组
sudo usermod -aG docker $USER
安装 kubeadm、kubelet 和 kubectl
编辑 /etc/apt/sources.list.d/kubernetes.list
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main执行安装命令
sudo apt update && sudo apt install -y kubeadm kubelet kubectl
-y 表示自动 yes
创建 kubernetes
sudo kubeadm init --ignore-preflight-errors=Swap --image-repository=registry.aliyuncs.com/google_containers
分析解决错误
发现报错:
[kubelet-check] Initial timeout of 40s passed.
[kubelet-check] It seems like the kubelet isn't running or healthy.
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.执行命令查询 kubelet 的 systemd 日志,命令如下:
journalctl -xeu kubelet
原始日志如下:
10月 12 11:20:03 k8s-master kubelet[1064046]: E1012 11:20:03.706633 1064046 server.go:294] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \>
日志中报错信息说 kubelet 的 cgroup driver 是 systemd,与 docker 的 cgroup driver 是不一致的。
使用 docker info | grep -i cgroup 查看 cgroup driver,发现是 cgroupfs,为了与 kebelet 保持一致,需要把 cgroup driver 改为 systemd。
修改 docker 的 cgroup driver
这里选择使用 systemd 作为 cgroup driver,编辑 /etc/docker/daemon.json,添加 exec-opts 配置项,如下所示:
{
"registry-mirrors": ["https://alzgoonw.mirrors.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore": true
}反之亦可,即把 kebelet 的 cgroup driver 改为 cgroupfs,与 docker 保持一致即可。
修改 kubelet 的 cgroup driver
编辑 /etc/systemd/system/kubelet.services.d/10-kubeadm.conf,如下图所示:

重启 docker,并查询 docker 状态、信息
systemctl restart docker
systemctl status docker
docker info | grep -i cgroup
docker 的 cgroup driver 变成了 systemd
再次执行 kubeadm init
看到 "Your Kubernetes control-plane has initialized successfully!",表示执行成功。
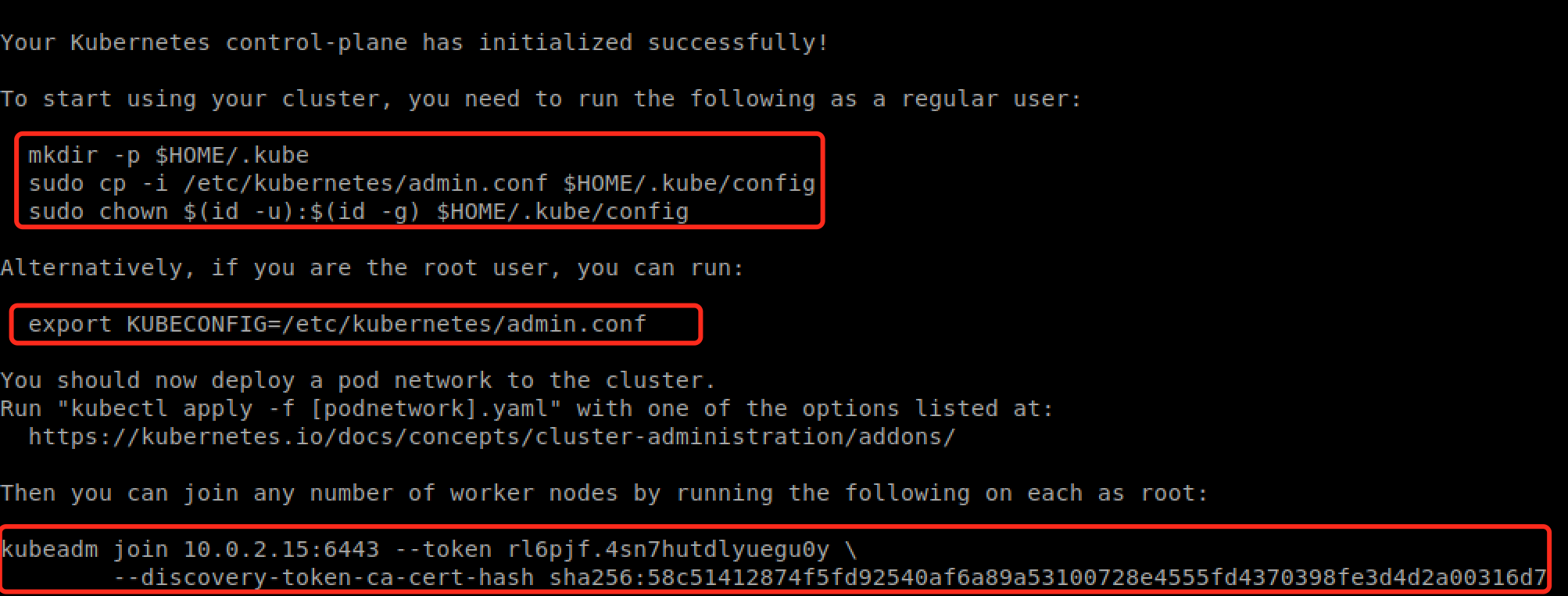
根据提示配置即可。
设置 kube 配置
执行提示信息中的命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
配置 KUBECONFIG 环境变量
export KUBECONFIG=$HOME/.kube/config
至此配置基本完成!
执行 "kubectl get pod -A" 命令,看到如下信息,表示安装成功

问题一:kubeadm init 安装完后,node 状态为 NotReady,coredns 的 pod 状态为 Pending

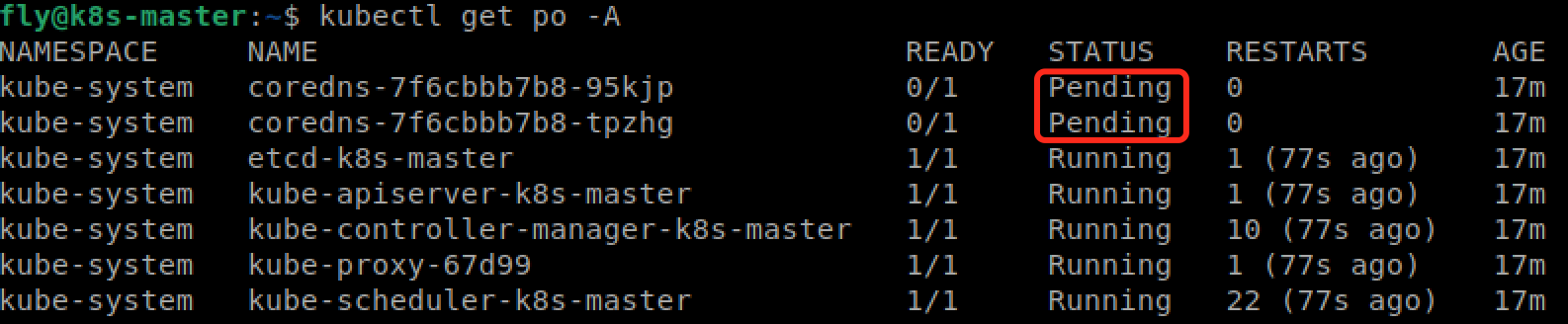
使用 “kubectl describe node k8s-master” 命令查看 node 信息,发现
Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:Network plugin returns error: cni plugin not initialized解决方法:
- 单机版的 k8s 不需要 cni 插件,编辑 /var/lib/kubelet/kubeadm-flags.env,从 KUBELET_KUBEADM_ARGS 中去掉 “--network-pulgin=cni”
- 执行 “systemctl restart kubelet” 命令,再重新查看 node 状态变为 Ready,coredns 状态变为了 Running,都恢复正常了
安装 worker
在第二台虚拟机上,安装 kubeadm、kubelet
把 /var/lib/kubectl/kubeadm-flags.env 里的 --network-pulgin=cni 去掉
执行 "kubeadm join xxx" 命令
执行成功后,在 master 上执行 kubectl get node 便可以看到 master 和 worker 两个节点。
参考:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号