
从零开始实现lmax-Disruptor队列(四)多线程生产者MultiProducerSequencer原理解析
MyDisruptor V4版本介绍
在v3版本的MyDisruptor实现多线程消费者后。按照计划,v4版本的MyDisruptor需要支持线程安全的多线程生产者功能。
由于该文属于系列博客的一部分,需要先对之前的博客内容有所了解才能更好地理解本篇博客
- v1版本博客:从零开始实现lmax-Disruptor队列(一)RingBuffer与单生产者、单消费者工作原理解析
- v2版本博客:从零开始实现lmax-Disruptor队列(二)多消费者、消费者组间消费依赖原理解析
- v3版本博客:从零开始实现lmax-Disruptor队列(三)多线程消费者WorkerPool原理解析
MyDisruptor支持多线程生产者
- 之前的v3版本实现了多线程消费者,提供并发消费的能力以加速消费速度。同理,disruptor也提供了多线程生产者机制以支持更快的生产速度。
- disruptor的多线程生产者机制,其本质是提供了一个线程安全的生产者序列器。
线程安全的生产者序列器允许多个线程并发的通过next方法申请可用的生产序列号和publish发布序列号,内部通过cas机制保证每个生产者线程拿到的序列号是独一无二的。 - disruptor的多线程生产者中通过AvailableBuffer数组机制,巧妙地避免了多个线程发布时并发的修改可用的最大生产者序列。
不根据一个单独的序列对象来标识,而是通过一整个数组来标识可用的最大生产者序列,发布时每个生产者线程都只会更新属于该线程自己的下标值,不会出现多写争抢。
如何设计一个线程安全的多生产者?
在开始介绍disruptor的实现方式之前,可以站在设计者的角度先大致思考一下如何设计一个线程安全的生产者序列器(其功能、使用方法最好和单线程生产者序列器保持一致)。
第一个要解决的问题是:如何保证多个线程能够线程安全的获取序列号,不会获取到重复的序列号而互相覆盖?
- 可以参考多线程消费者,在next方法中通过cas的争抢来实现。
第二个问题是二阶段生产+多线程并发的场景下,如何避免消费者消费到还未发布完成的事件?
- disruptor的生产者生产时是分为两个阶段的,首先通过next方法获取可用的序列号,然后通过publish发布序列号,令生产完成的序列号对消费者可见,消费者监听到生产者序列号的变化便会进行对应的消费。
- 举个例子,当前生产者已成功发布了序列号11,线程a通过next方法获取到了序列号12,线程b获取到了13,线程c获取到了14。此时线程c生产完毕后,如果按照常规的思路直接更新当前生产者序列为14的话是不行的。
因为这样消费者会认为14以及之前的12、13都已经发布完成,会错误的消费实际还未完成生产的序列号为12、13的事件。
那么是否需要引入一个已发布的最小生产者序列号属性呢?
- 上述情况下,如果引入最小生产者序列号机制,那么虽然线程c生产完了序列14的事件,但对外可见的最小生产者序列号依然是11,不会有问题。
那么线程c完成了序列14的生产后,是否可以继续next获取新的序列15进行生产呢?
- 如果不可以,那么多线程生产者的吞吐量就会受到影响,性能大大降低。
- 如果可以,当线程a、b完成了序列12、13的序列号生产后,又该如何知道序列14对应地事件已经生产完成可以发布,使得最小生产者序列号能正确的变为14呢?
可以看到从设计者的角度出发,可以想到非常多的方案。其中有的可行,有的不可行;可行的方案中有的性能更好,有的更简洁优雅,读者可以尝试着发散一下思维,这里限于篇幅就不再展开了。
多线程生产者MyMultiProducerSequencer介绍
disruptor的设计者当初肯定也对各种方案进行了评估,下面我们就来看看disruptor开发团队认为的最好的多线程生产者设计方案吧。
disruptor多线程生产者的next方法实现和单线程生产者原理差不多,但为了实现线程安全在几处关键地方有所不同。
如何保证多个线程能够线程安全的获取序列号,不会获取到重复的序列号而互相覆盖?
- 单线程消费者中最新的消费者序列值是一个普通的long类型变量,而多线程消费者中则通过一个Sequence对象来保存缓存的最新消费者序列值实现线程间的可见。
- 同时Sequence类中还提供了一个CAS方法compareAndSet(MySequence的v4版本新增该方法)。
通过Sequence提供的cas方法,多个生产者线程并发调用next方法时,每个线程通过对currentProducerSequence进行cas争抢可以保证返回独一无二的序列号。
二阶段生产+多线程并发的场景下,如何避免消费者消费到还未发布完成的事件?
- 多线程生产者中新增了一个和队列长度保持一致的数组availableBuffer,用于维护对应序列号的发布状态。
每个生产者发布对应序列号时,也会通过按照availableBuffer长度求余数的方式,更新对应位置的数据。这样一来就能记录一个序列号段区间内,到底哪些序列号已发布哪些还未发布(例如序列号11已发布、12、13未发布,14已发布)。 - 前面提到多线程生产者中在next方法中,还未发布就更新了currentProducerSequence的值,使得对外暴露的最大可用生产者队列变得不准确了。
因此多线程生产者中currentProducerSequence(cursor)不再用于标识可用的最大生产者序列,而仅标识已发布的最大生产者序列。
如何兼容之前单线程生产者场景下,SequenceBarrier/WaitStrategy中利用currentProducerSequence(cursor)进行消费进度约束的设计呢?
- 之前SequenceBarrier中维护了currentProducerSequence最大可用生产者序列,通过这个来避免消费者消费越界,访问到还未完成生产的事件。
但多线程生产者中小于currentProducerSequence的序列号可能还未发布,其实际含义已经变了,disruptor在SequenceBarrier的waitFor方法中被迫打了个补丁来做兼容。(下文展开说明)
/**
* 多线程生产者(仿disruptor.MultiProducerSequencer)
*/
public class MyMultiProducerSequencer implements MyProducerSequencer{
private final int ringBufferSize;
private final MySequence currentProducerSequence = new MySequence();
private final List<MySequence> gatingConsumerSequenceList = new ArrayList<>();
private final MyWaitStrategy myWaitStrategy;
private final MySequence gatingSequenceCache = new MySequence();
private final int[] availableBuffer;
private final int indexMask;
private final int indexShift;
/**
* 通过unsafe访问availableBuffer数组,可以在读写时按需插入读/写内存屏障
*/
private static final Unsafe UNSAFE = UnsafeUtil.getUnsafe();
private static final long BASE = UNSAFE.arrayBaseOffset(int[].class);
private static final long SCALE = UNSAFE.arrayIndexScale(int[].class);
public MyMultiProducerSequencer(int ringBufferSize, final MyWaitStrategy myWaitStrategy) {
this.ringBufferSize = ringBufferSize;
this.myWaitStrategy = myWaitStrategy;
this.availableBuffer = new int[ringBufferSize];
this.indexMask = this.ringBufferSize - 1;
this.indexShift = log2(ringBufferSize);
initialiseAvailableBuffer();
}
private void initialiseAvailableBuffer() {
for (int i = availableBuffer.length - 1; i >= 0; i--) {
this.availableBuffer[i] = -1;
}
}
private static int log2(int i) {
int r = 0;
while ((i >>= 1) != 0) {
++r;
}
return r;
}
@Override
public long next() {
return next(1);
}
@Override
public long next(int n) {
do {
// 保存申请前的最大生产者序列
long currentMaxProducerSequenceNum = currentProducerSequence.get();
// 申请之后的生产者位点
long nextProducerSequence = currentMaxProducerSequenceNum + n;
// 新申请的位点下,生产者恰好超过消费者一圈的环绕临界点序列
long wrapPoint = nextProducerSequence - this.ringBufferSize;
// 获得当前已缓存的消费者位点(使用Sequence对象维护位点,volatile的读。因为多生产者环境下,多个线程会并发读写gatingSequenceCache)
long cachedGatingSequence = this.gatingSequenceCache.get();
// 消费者位点cachedValue并不是实时获取的(因为在没有超过环绕点一圈时,生产者是可以放心生产的)
// 每次发布都实时获取反而会触发对消费者sequence强一致的读,迫使消费者线程所在的CPU刷新缓存(而这是不需要的)
if(wrapPoint > cachedGatingSequence){
long gatingSequence = SequenceUtil.getMinimumSequence(currentMaxProducerSequenceNum, this.gatingConsumerSequenceList);
if(wrapPoint > gatingSequence){
// 如果确实超过了一圈,则生产者无法获取队列空间
LockSupport.parkNanos(1);
// park短暂阻塞后continue跳出重新进入循环
continue;
// 为什么不能像单线程生产者一样在这里while循环park?
// 因为别的生产者线程也在争抢currentMaxProducerSequence,如果在这里直接阻塞,会导致当前拿到的序列号可能也被别的线程获取到
// 但最终是否可用需要通过cas的结果来决定,所以每次循环必须重新获取gatingSequenceCache最新的值
}
// 满足条件了,则缓存获得最新的消费者序列
// 因为不是实时获取消费者序列,可能gatingSequence比上一次的值要大很多
// 这种情况下,待到下一次next申请时就可以不用去强一致的通过getMinimumSequence读consumerSequence了(走else分支)
this.gatingSequenceCache.set(gatingSequence);
}else {
if (this.currentProducerSequence.compareAndSet(currentMaxProducerSequenceNum, nextProducerSequence)) {
// 由于是多生产者序列,可能存在多个生产者同时执行next方法申请序列,因此只有cas成功的线程才视为申请成功,可以跳出循环
return nextProducerSequence;
}
// cas更新失败,重新循环获取最新的消费位点
// continue;
}
}while (true);
}
@Override
public void publish(long publishIndex) {
setAvailable(publishIndex);
this.myWaitStrategy.signalWhenBlocking();
}
@Override
public MySequenceBarrier newBarrier() {
return new MySequenceBarrier(this,this.currentProducerSequence,this.myWaitStrategy,new ArrayList<>());
}
@Override
public MySequenceBarrier newBarrier(MySequence... dependenceSequences) {
return new MySequenceBarrier(this,this.currentProducerSequence,this.myWaitStrategy,new ArrayList<>(Arrays.asList(dependenceSequences)));
}
@Override
public void addGatingConsumerSequenceList(MySequence newGatingConsumerSequence) {
this.gatingConsumerSequenceList.add(newGatingConsumerSequence);
}
@Override
public void addGatingConsumerSequenceList(MySequence... newGatingConsumerSequences) {
this.gatingConsumerSequenceList.addAll(Arrays.asList(newGatingConsumerSequences));
}
@Override
public MySequence getCurrentProducerSequence() {
return this.currentProducerSequence;
}
@Override
public int getRingBufferSize() {
return this.ringBufferSize;
}
@Override
public long getHighestPublishedSequence(long lowBound, long availableSequence) {
// lowBound是消费者传入的,保证是已经明确发布了的最小生产者序列号
// 因此,从lowBound开始,向后寻找,有两种情况
// 1 在lowBound到availableSequence中间存在未发布的下标(isAvailable(sequence) == false),
// 那么,找到的这个未发布下标的前一个序列号,就是当前最大的已经发布了的序列号(可以被消费者正常消费)
// 2 在lowBound到availableSequence中间不存在未发布的下标,那么就和单生产者的情况一样
// 包括availableSequence以及之前的序列号都已经发布过了,availableSequence就是当前可用的最大的的序列号(已发布的)
for(long sequence = lowBound; sequence <= availableSequence; sequence++){
if (!isAvailable(sequence)) {
// 属于上述的情况1,lowBound和availableSequence中间存在未发布的序列号
return sequence - 1;
}
}
// 属于上述的情况2,lowBound和availableSequence中间不存在未发布的序列号
return availableSequence;
}
private void setAvailable(long sequence){
int index = calculateIndex(sequence);
int flag = calculateAvailabilityFlag(sequence);
// 计算index对应下标相对于availableBuffer引用起始位置的指针偏移量
long bufferAddress = (index * SCALE) + BASE;
// 功能上等价于this.availableBuffer[index] = flag,但添加了写屏障
// 和单线程生产者中的lazySet作用一样,保证了对publish发布的event事件对象的更新一定先于对availableBuffer对应下标值的更新
// 避免消费者拿到新的发布序列号时由于新event事件未对其可见,而错误的消费了之前老的event事件
UNSAFE.putOrderedInt(availableBuffer, bufferAddress, flag);
}
private int calculateAvailabilityFlag(long sequence) {
return (int) (sequence >>> indexShift);
}
private int calculateIndex(long sequence) {
return ((int) sequence) & indexMask;
}
public boolean isAvailable(long sequence) {
int index = calculateIndex(sequence);
int flag = calculateAvailabilityFlag(sequence);
// 计算index对应下标相对于availableBuffer引用起始位置的指针偏移量
long bufferAddress = (index * SCALE) + BASE;
// 功能上等价于this.availableBuffer[index] == flag
// 但是添加了读屏障保证了强一致的读,可以让消费者实时的获取到生产者新的发布
return UNSAFE.getIntVolatile(availableBuffer, bufferAddress) == flag;
}
}
/**
* 序列号对象(仿Disruptor.Sequence)
*
* 由于需要被生产者、消费者线程同时访问,因此内部是一个volatile修饰的long值
* */
public class MySequence {
/**
* 序列起始值默认为-1,保证下一序列恰好是0(即第一个合法的序列号)
* */
private volatile long value = -1;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static {
try {
// 由于提供给cas内存中字段偏移量的unsafe类只能在被jdk信任的类中直接使用,这里使用反射来绕过这一限制
Field getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);
UNSAFE = (Unsafe) getUnsafe.get(null);
VALUE_OFFSET = UNSAFE.objectFieldOffset(MySequence.class.getDeclaredField("value"));
}
catch (final Exception e) {
throw new RuntimeException(e);
}
}
public MySequence() {
}
public MySequence(long value) {
this.value = value;
}
public long get() {
return value;
}
public void set(long value) {
this.value = value;
}
public void lazySet(long value) {
UNSAFE.putOrderedLong(this, VALUE_OFFSET, value);
}
public boolean compareAndSet(long expect, long update){
return UNSAFE.compareAndSwapLong(this, VALUE_OFFSET, expect, update);
}
}
public class UnsafeUtil {
private static final Unsafe UNSAFE;
static {
try {
// 由于提供给cas内存中字段偏移量的unsafe类只能在被jdk信任的类中直接使用,这里使用反射来绕过这一限制
Field getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);
UNSAFE = (Unsafe) getUnsafe.get(null);
}
catch (final Exception e) {
throw new RuntimeException(e);
}
}
public static Unsafe getUnsafe(){
return UNSAFE;
}
}
SequenceBarrier中的补丁
- SequenceBarrier中也维护了生产者序列器对象,并且生产者序列器对象实现了getHighestPublishedSequence接口,供SequenceBarrier使用(MyDisruptor v4版本新增)。
单线程生产者的getHighestPublishedSequence实现中,和之前逻辑一样,availableSequence就是可用的最大生产者序列。
多线程生产者的getHighestPublishedSequence实现中,则返回availableBuffer中的连续的最大序列号(具体的原理在下文详细讲解)。
/**
* 序列栅栏(仿Disruptor.SequenceBarrier)
* */
public class MySequenceBarrier {
private final MyProducerSequencer myProducerSequencer;
private final MySequence currentProducerSequence;
private final MyWaitStrategy myWaitStrategy;
private final List<MySequence> dependentSequencesList;
public MySequenceBarrier(MyProducerSequencer myProducerSequencer, MySequence currentProducerSequence,
MyWaitStrategy myWaitStrategy, List<MySequence> dependentSequencesList) {
this.myProducerSequencer = myProducerSequencer;
this.currentProducerSequence = currentProducerSequence;
this.myWaitStrategy = myWaitStrategy;
if(!dependentSequencesList.isEmpty()) {
this.dependentSequencesList = dependentSequencesList;
}else{
// 如果传入的上游依赖序列为空,则生产者序列号作为兜底的依赖
this.dependentSequencesList = Collections.singletonList(currentProducerSequence);
}
}
/**
* 获得可用的消费者下标(disruptor中的waitFor)
* */
public long getAvailableConsumeSequence(long currentConsumeSequence) throws InterruptedException {
long availableSequence = this.myWaitStrategy.waitFor(currentConsumeSequence,currentProducerSequence,dependentSequencesList);
if (availableSequence < currentConsumeSequence) {
return availableSequence;
}
// 多线程生产者中,需要进一步约束(于v4版本新增)
return myProducerSequencer.getHighestPublishedSequence(currentConsumeSequence,availableSequence);
}
}
availableBuffer标识发布状态工作原理解析
- 构造函数初始化时通过initialiseAvailableBuffer方法将availableBuffer内部的值都设置为-1的初始值。
- availableBuffer中的值标识的是ringBuffer中对应下标位置的事件第几次被覆盖。
举个例子:一个长度为8的ringBuffer,其内部数组下标为2的位置,当序列号为2时其值会被设置为0(第一次被设置值,未被覆盖),序列号为10时其值会被设置为1(被覆盖一次),序列号为18时其值会被设置为2(被覆盖两次),以此类推。
序列号对应的下标值通过calculateIndex求模运算获得,而被覆盖的次数通过calculateAvailabilityFlag方法对当前发布的序列号做对数计算出来。 - 在MultiProducerSequencer的publish方法中,通过setAvailable来标示当前序号为已发布状态的,原理如上所述。
- 而在消费者序列屏障中被调用的getHighestPublishedSequence方法中,则通过isAvailable来判断传入的序列号是否已发布。
isAvailable方法相当于对setAvailable做了个逆运算,如果对应的序列号确实已经发布过了,那么availableBuffer对应下标的值一定做了对数运算的值,否则就是还未发布。 - 由于在next方法中控制、约束了可申请到的生产者序列号不会超过最慢的消费者一轮(ringBuffer的长度),因此不用担心位于不同轮次的序列号发布会互相覆盖。
如果没有next方法中的最大差异约束,之前举例的场景中,ringBuffer长度为8,此时序列号10还未发布,序列号18却发布了,则availableBuffer中下标为2的位置就被覆盖了(无法真实记录序列号10是否发布)。
也正是因为有了这个约束,在setAvailable中可以不需要做额外的校验直接更新就行。
Unsafe+偏移量访问数组原理解析
在lab1中提到单线程的生产者SingleProducerSequencer在publish方法中通过一个lazySet方法设置了一个写内存屏障,使得对entry事件对象的更新操作一定先于对序列号的更新,且消费者也是使用读屏障进行强一致的读,避免指令重排序和高速缓存同步延迟导致消费者线程消费到错误的事件。
那么在多线程生产者中,由于引入了一个availableBuffer数组,并且在消费者调用了isAvailable对其进行了访问。
那么对于数组的更新和读取应该如何插入读、写屏障呢?
- java的unsafe类提供了一些基础的方法,可以在读、写数组时按需设置读写内存屏障;其底层是通过计算对应下标数据在数组中的指针偏移量实现的。
- 获取数组中对应下标数据的偏移值主要取决于两个属性:数组对象实际存放数据至数组引用的偏移base和每一个数据所占用的空间大小scale
base:java中数组也是一个对象,在内存分配时需要设置对象头、类指针、数组长度信息,因此实际存放数据的位置相对于数组引用是有一定偏移的,需要通过UNSAFE.arrayBaseOffset获得具体的偏移
scale:不同类型的数组中所存储的数据大小是不一样的,比如int类型数组中每一个数据占4个字节,而long类型数组中每一个数据则占8个字节,需要动态获取 - 综上可得,下标存放数据相对数组引用的偏移量 = base + (下标值 * scale)
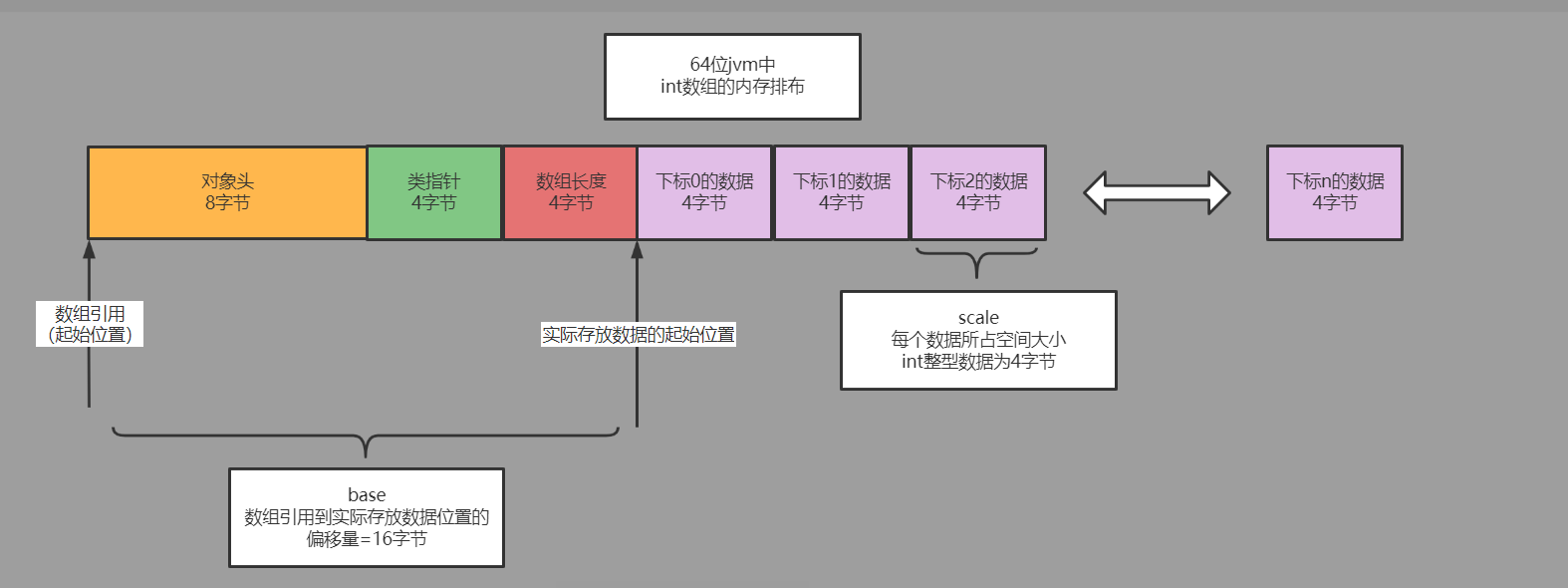
- 和单线程生产者中一样,发布时setAvailable方法通过UNSAFE.putOrderedInt在更新前插入一个写屏障。
- 在getHighestPublishedSequence的isAvailable方法中,消费者线程通过UNSAFE.getIntVolatile强一致的读取数组中对应下标的值。
MyProducerSequencer接口统一两种类型的生产者
disruptor需要支持单线程、多线程两种类型的生产者。所以抽象了一个生产者序列器接口ProducerSequencer用于兼容两者的差异。
/**
* 生产者序列器接口(仿disruptor.ProducerSequencer)
* */
public interface MyProducerSequencer {
/**
* 获得一个可用的生产者序列值
* @return 可用的生产者序列值
* */
long next();
/**
* 获得一个可用的生产者序列值区间
* @param n 区间长度
* @return 可用的生产者序列区间的最大值
* */
long next(int n);
/**
* 发布一个生产者序列
* @param publishIndex 需要发布的生产者序列号
* */
void publish(long publishIndex);
/**
* 创建一个无上游消费者依赖的序列屏障
* @return 新的序列屏障
* */
MySequenceBarrier newBarrier();
/**
* 创建一个有上游依赖的序列屏障
* @param dependenceSequences 上游依赖的序列集合
* @return 新的序列屏障
* */
MySequenceBarrier newBarrier(MySequence... dependenceSequences);
/**
* 向生产者注册一个消费者序列
* @param newGatingConsumerSequence 新的消费者序列
* */
void addGatingConsumerSequenceList(MySequence newGatingConsumerSequence);
/**
* 向生产者注册一个消费者序列集合
* @param newGatingConsumerSequences 新的消费者序列集合
* */
void addGatingConsumerSequenceList(MySequence... newGatingConsumerSequences);
/**
* 获得当前的生产者序列(cursor)
* @return 当前的生产者序列
* */
MySequence getCurrentProducerSequence();
/**
* 获得ringBuffer的大小
* @return ringBuffer大小
* */
int getRingBufferSize();
/**
* 获得最大的已发布的,可用的消费者序列值
* @param nextSequence 已经明确发布了的最小生产者序列号
* @param availableSequence 需要申请的,可能的最大的序列号
* @return 最大的已发布的,可用的消费者序列值
* */
long getHighestPublishedSequence(long nextSequence, long availableSequence);
}
MyDisruptor v4版本demo解析
public class MyRingBufferV4Demo {
public static void main(String[] args) {
// 环形队列容量
int ringBufferSize = 16;
// 创建环形队列(多线程生产者,即多线程安全的生产者(可以并发的next、publish))
MyRingBuffer<OrderEventModel> myRingBuffer = MyRingBuffer.createMultiProducer(
new OrderEventProducer(), ringBufferSize, new MyBusySpinWaitStrategy());
// 获得ringBuffer的序列屏障(最上游的序列屏障内只维护生产者的序列)
MySequenceBarrier mySequenceBarrier = myRingBuffer.newBarrier();
// ================================== 基于生产者序列屏障,创建消费者A
MyBatchEventProcessor<OrderEventModel> eventProcessorA =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerA"), mySequenceBarrier);
MySequence consumeSequenceA = eventProcessorA.getCurrentConsumeSequence();
// RingBuffer监听消费者A的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceA);
// ================================== 消费者组依赖上游的消费者A,通过消费者A的序列号创建序列屏障(构成消费的顺序依赖)
MySequenceBarrier workerSequenceBarrier = myRingBuffer.newBarrier(consumeSequenceA);
// 基于序列屏障,创建多线程消费者B
MyWorkerPool<OrderEventModel> workerPoolProcessorB =
new MyWorkerPool<>(myRingBuffer, workerSequenceBarrier,
new OrderWorkHandlerDemo("workerHandler1"),
new OrderWorkHandlerDemo("workerHandler2"),
new OrderWorkHandlerDemo("workerHandler3"));
MySequence[] workerSequences = workerPoolProcessorB.getCurrentWorkerSequences();
// RingBuffer监听消费者C的序列
myRingBuffer.addGatingConsumerSequenceList(workerSequences);
// ================================== 通过消费者A的序列号创建序列屏障(构成消费的顺序依赖),创建消费者C
MySequenceBarrier mySequenceBarrierC = myRingBuffer.newBarrier(consumeSequenceA);
MyBatchEventProcessor<OrderEventModel> eventProcessorC =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerC"), mySequenceBarrierC);
MySequence consumeSequenceC = eventProcessorC.getCurrentConsumeSequence();
// RingBuffer监听消费者C的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceC);
// ================================== 基于多线程消费者B,单线程消费者C的序列屏障,创建消费者D
MySequence[] bAndCSequenceArr = new MySequence[workerSequences.length+1];
// 把多线程消费者B的序列复制到合并的序列数组中
System.arraycopy(workerSequences, 0, bAndCSequenceArr, 0, workerSequences.length);
// 数组的最后一位是消费者C的序列
bAndCSequenceArr[bAndCSequenceArr.length-1] = consumeSequenceC;
MySequenceBarrier mySequenceBarrierD = myRingBuffer.newBarrier(bAndCSequenceArr);
MyBatchEventProcessor<OrderEventModel> eventProcessorD =
new MyBatchEventProcessor<>(myRingBuffer, new OrderEventHandlerDemo("consumerD"), mySequenceBarrierD);
MySequence consumeSequenceD = eventProcessorD.getCurrentConsumeSequence();
// RingBuffer监听消费者D的序列
myRingBuffer.addGatingConsumerSequenceList(consumeSequenceD);
// 启动消费者线程A
new Thread(eventProcessorA).start();
// 启动workerPool多线程消费者B
workerPoolProcessorB.start(Executors.newFixedThreadPool(10, new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"worker" + mCount.getAndIncrement());
}
}));
// 启动消费者线程C
new Thread(eventProcessorC).start();
// 启动消费者线程D
new Thread(eventProcessorD).start();
// 启动多线程生产者
ExecutorService executorService = Executors.newFixedThreadPool(10, new ThreadFactory() {
private final AtomicInteger mCount = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"workerProducer" + mCount.getAndIncrement());
}
});
for(int i=1; i<4; i++) {
int num = i;
executorService.submit(() -> {
// 每个生产者并发发布100个事件
for (int j = 0; j < 100; j++) {
long nextIndex = myRingBuffer.next();
OrderEventModel orderEvent = myRingBuffer.get(nextIndex);
orderEvent.setMessage("message-" + num + "-" + j);
orderEvent.setPrice(num * j * 10);
myRingBuffer.publish(nextIndex);
}
});
}
}
}
- v4版本的demo和v3版本的逻辑几乎一致,唯一的区别在于通过RingBuffer提供的createMultiProducer方法创建了一个支持多线程生产的RingBuffer。
- 多线程生产者允许多个线程并发的调用next方法、publish方法进行事件的生产发布。
总结
- disruptor的多线程生产者实现中维护了一个与当前RingBuffer一样大小的数组availableBuffer,利用覆盖机制巧妙的存储了每个当前有效的序列号的发布状态。
比起一般思路中引入一个最小的生产者序列号,令多个生产者线程并发更新的方案;disruptor的实现方案拆分了竞争的变量,避免了多写多读的场景。
每个生产者线程获得自己独占的序列号并且独占的更新,做到了一写多读,在多占用一定空间的情况下,提高了队列的整体吞吐量。 - 使用基于Unsafe + 偏移量的机制读写数组,除了可以引入内存屏障,还绕过了java正常访问数组时的下标越界检查。
这样的实现就和C语言中一样,运行时不校验下标是否越界,略微提高性能的同时也引入了野指针问题,使得访问时下标真的越界时会出现各种奇怪的问题,需要程序员更加仔细的编码。
disruptor无论在整体设计还是最终代码实现上都有很多值得反复琢磨和学习的细节,希望能帮助到对disruptor感兴趣的小伙伴。
本篇博客的完整代码在我的github上:https://github.com/1399852153/MyDisruptor 分支:feature/lab4

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步