
ucore操作系统学习(五) ucore lab5用户进程管理
1. ucore lab5介绍
ucore在lab4中实现了进程/线程机制,能够创建并进行内核线程的调度。通过上下文的切换令线程分时的获得CPU,使得不同线程能够并发的运行。
在lab5中需要更进一步,实现我们平常开发接触到的、运行在用户态的进程/线程机制。用户线程通常用于承载和运行应用程序,为了保护操作系统内核,避免其被不够鲁棒的应用程序破坏。应用程序都运行在低特权级中,无法直接访问高特权级的内核数据结构,也无法通过程序指令直接的访问各种外设。
但应用程序访问高特权级数据、外设的需求是不可避免的(即使简单的打印数据到控制台中也是在对显卡这一外设进行控制),因此ucore在lab5中也实现了系统调用机制。应用程序平常运行在用户态,在有需要时可以通过系统调用的方式间接的访问外设等受到保护的资源。
系统调用介绍
系统调用是操作系统提供的一种特殊api接口,底层是通过中断实现的。应用程序调用系统中断时,其CPL特权级会被暂时的提升到ring0,因此便获得了访问外设、内核数据的能力。这一提升CPL特权级从外层用户态到里层内核态的过程,也被称为陷入内核(系统调用会陷入内核,但是陷入内核的方式除了系统调用外,还包括触发保护异常等)。
由于系统调用是操作系统的开发人员精心设计的,且对传入的参数等等有着很严格的控制,确保了系统调用不会对内核造成破坏。同时,在系统调用中断返回时,也会将其CPL特权级对应用程序透明的还原到用户态。在ucore的lab5中,提供了一些用户态的demo应用程序,并在内核实现了诸如fork、exit、kill、yield、wait等等系统调用功能以及C实现的应用程序系统调用库。
通过lab5的学习,可以更深入的了解操作系统中用户态应用程序的加载、运行和退出机制,以及系统调用的工作原理。
lab5是建立在之前实验的基础之上的,需要先理解之前的实验内容才能顺利理解lab5的内容。
可以参考一下我关于前面实验的博客:
1. ucore操作系统学习(一) ucore lab1系统启动流程分析
2. ucore操作系统学习(二) ucore lab2物理内存管理分析
3. ucore操作系统学习(三) ucore lab3虚拟内存管理分析
4. ucore操作系统学习(四) ucore lab4内核线程管理
2. ucore lab5实验细节分析
下面通过解析lab5实验的源码,进一步分析在ucore中加载、并运行一个用户态应用程序的机制,以及系统调用是如何实现的。
2.1 lab5中线程控制块的变化
lab5中引入了用户进程/线程机制,用户进程/线程会随着程序的执行不断的被创建、退出并销毁。同时也引入了父子进程的概念,在子进程退出时,由于其内核栈和子进程自己的进程控制块无法进行自我回收,因此需要通知其父进程进行最后的回收工作。
为此,ucore在lab5中在进程控制块proc_sturct中加入了exit_code、wait_state以及标识线程之间父子关系的链表节点*cptr, *yptr, *optr。
lab5中proc_struct:
/** * 进程控制块结构(ucore进程和线程都使用proc_struct进行管理) * */ struct proc_struct { 。。。 只列出了lab5中新增加的属性项
// 当前线程退出时的原因(在回收子线程时会发送给父线程) int exit_code; // exit code (be sent to parent proc) // 当前线程进入wait阻塞态的原因 uint32_t wait_state; // waiting state /** * cptr即child ptr,当前线程子线程(链表结构) * yptr即younger sibling ptr; * optr即older sibling ptr; * cptr为当前线程的子线程双向链表头结点,通过yptr和optr可以找到关联的所有子线程 * */ struct proc_struct *cptr, *yptr, *optr; // relations between processes };
2.2 系统调用的实现原理
系统调用贯穿着整个lab5实验的内容,只有理解了系统调用的实现原理后才能更进一步的理解lab5给出的demo程序中应用程序加载、运行及退出的机制。
系统调用是提供给运行在用户态的应用程序使用的,且由于需要进行CPL特权级的提升,因此是通过硬件中断来实现的。
ucore在初始化中断描述符表的/trap/trap.c的idt_init函数中,在前面实验的基础上额外设置了一个用于系统调用的中断描述符。
idt_init实现:
#define T_SYSCALL 0x80 /* idt_init - initialize IDT to each of the entry points in kern/trap/vectors.S */ void idt_init(void) { extern uintptr_t __vectors[]; int i; // 首先通过tools/vector.c通过程序生成/kern/trap/verctor.S,并在加载内核时对之前已经声明的全局变量__vectors进行整体的赋值 // __vectors数组中的每一项对应于中断描述符的中断服务例程的入口地址,在SETGATE宏的使用中可以体现出来 // 将__vectors数组中每一项关于中断描述符的描述设置到下标相同的idt中,通过宏SETGATE构造出最终的中断描述符结构 for (i = 0; i < sizeof(idt) / sizeof(struct gatedesc); i ++) { // 遍历idt数组,将其中的内容(中断描述符)设置进IDT中断描述符表中(默认的DPL特权级都是内核态DPL_KERNEL-0) SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL); } // 设置系统调用的中断描述符(T_SYSCALL 0x80),因为是提供给应用程序使用的,因此DPL特权级设置为用户态(DPL_USER) SETGATE(idt[T_SYSCALL], 1, GD_KTEXT, __vectors[T_SYSCALL], DPL_USER); // load the IDT 令IDTR中断描述符表寄存器指向idt_pd,加载IDT // idt_pd结构体中的前16位为描述符表的界限,pd_base指向之前完成了赋值操作的idt数组的起始位置 lidt(&idt_pd); }
可以看到在idt_init中,额外的设置了一个中断号为T_SYSCALL(0x80)的中断描述符用于处理系统调用,且其DPL特权级为用户态,使得用户程序可以在用户态主动的发起该中断,获得操作系统内核提供的服务。
对应的,在lab5的/trap/trap.c的中断处理分发逻辑trap_dispatch函数中,也实现了对应的中断服务例程用于处理T_SYSCALL系统调用中断。
trap_dispatch函数:
static void trap_dispatch(struct trapframe *tf) { char c; int ret=0; switch (tf->tf_trapno) { 。。。 省略其它中断号的处理逻辑 case T_SYSCALL: syscall(); break; 。。。 省略其它中断号的处理逻辑 }
syscall函数(内核中系统调用处理逻辑):
static int (*syscalls[])(uint32_t arg[]) = { [SYS_exit] sys_exit, [SYS_fork] sys_fork, [SYS_wait] sys_wait, [SYS_exec] sys_exec, [SYS_yield] sys_yield, [SYS_kill] sys_kill, [SYS_getpid] sys_getpid, [SYS_putc] sys_putc, [SYS_pgdir] sys_pgdir, }; #define NUM_SYSCALLS ((sizeof(syscalls)) / (sizeof(syscalls[0]))) void syscall(void) { struct trapframe *tf = current->tf; uint32_t arg[5]; int num = tf->tf_regs.reg_eax; if (num >= 0 && num < NUM_SYSCALLS) { if (syscalls[num] != NULL) { arg[0] = tf->tf_regs.reg_edx; arg[1] = tf->tf_regs.reg_ecx; arg[2] = tf->tf_regs.reg_ebx; arg[3] = tf->tf_regs.reg_edi; arg[4] = tf->tf_regs.reg_esi; tf->tf_regs.reg_eax = syscalls[num](arg); return ; } } print_trapframe(tf); panic("undefined syscall %d, pid = %d, name = %s.\n", num, current->pid, current->name); }
ucore构造了一个当前系统所支持的系统调用处理表(syscalls数组),根据系统调用中断时传入的系统调用号(保存在eax中),跳转执行对应的系统调用逻辑。
ucore的系统调用允许通过edx、ecx、ebx、edi和esi这5个寄存器传递最多5个参数,并且在对应的系统调用逻辑完成后通过eax寄存器存放系统调用的返回值。另一方面,可以从ucore提供的在用户态执行的系统调用库函数实现中看到应用程序是如何发起系统调用的,主要逻辑位于/user/lib/syscall.c中。
库函数syscall.c中不同的系统调用最终都通过syscall函数进行统一处理,syscall通过内联汇编的形式,执行了int i 0x80(T_SYSCALL)以发起系统调用中断。系统调用号num赋值给了eax(a),且将需要传递的参数赋值(a[i])分别给了edx(d)、ecx(c)、ebx(b)、edi(D)和esi(S),且令返回值ret等于中断返回后的eax(=a ret)。
可以通过互相比对调用方用户态syscall.c库函数以及内核中的syscall实现,加深对系统调用工作机制的理解。
syscall.c(用户态的系统调用函数库):
#include <defs.h> #include <unistd.h> #include <stdarg.h> #include <syscall.h> #define MAX_ARGS 5 static inline int syscall(int num, ...) { va_list ap; va_start(ap, num); uint32_t a[MAX_ARGS]; int i, ret; for (i = 0; i < MAX_ARGS; i ++) { a[i] = va_arg(ap, uint32_t); } va_end(ap); asm volatile ( "int %1;" : "=a" (ret) : "i" (T_SYSCALL), "a" (num), "d" (a[0]), "c" (a[1]), "b" (a[2]), "D" (a[3]), "S" (a[4]) : "cc", "memory"); return ret; } int sys_exit(int error_code) { return syscall(SYS_exit, error_code); } int sys_fork(void) { return syscall(SYS_fork); } int sys_wait(int pid, int *store) { return syscall(SYS_wait, pid, store); } int sys_yield(void) { return syscall(SYS_yield); } int sys_kill(int pid) { return syscall(SYS_kill, pid); } int sys_getpid(void) { return syscall(SYS_getpid); } int sys_putc(int c) { return syscall(SYS_putc, c); } int sys_pgdir(void) { return syscall(SYS_pgdir); }
在前面的实验中提到过,如果包括系统调用在内的中断发生时,80386CPU将会在中断栈帧中压入中断发生前一刻的CS的值。如果是位于ring3用户态的应用程序发起的系统调用中断,那么内核在接受中断栈帧时其CS的CPL将会是ring3,并在执行中断服务例程时被临时的设置CS的CPL特权级为ring0以提升特权级,获得访问内核数据、外设的权限。
在系统调用处理完毕返回后,iret指令会将之前CPU硬件自动压入的cs(ring3的CPL)弹出。系统调用处理完毕中断返回时,应用程序便自动无感知的回到了ring3这一低特权级中。
2.3 应用程序的加载
lab4在总控函数kern_init中通过proc_init创建了两个内核线程idle_proc和init_proc,其中init_proc只是单单在控制台中打印了hello world。
但lab5中在init_proc中fork了一个内核线程执行user_main,在user_main中执行了sys_execve系统调用,用于执行BIOS引导时与ucore内核一起被加载到内存中的用户程序/user/exit.c,让exit.c在用户态中执行。(之所以要以这种方式加载exit.c是因为ucore目前还没有实现文件系统,无法以文件的形式去加载二进制的应用程序)
init_main实现(init_proc执行逻辑):
// init_main - the second kernel thread used to create user_main kernel threads static int init_main(void *arg) { size_t nr_free_pages_store = nr_free_pages(); size_t kernel_allocated_store = kallocated(); // fork创建一个线程执行user_main int pid = kernel_thread(user_main, NULL, 0); if (pid <= 0) { panic("create user_main failed.\n"); } // do_wait等待回收僵尸态子线程(第一个参数pid为0代表回收任意僵尸子线程) while (do_wait(0, NULL) == 0) { // 回收一个僵尸子线程后,进行调度 schedule(); } // 跳出了上述循环代表init_main的所有子线程都退出并回收完了 cprintf("all user-mode processes have quit.\n"); assert(initproc->cptr == NULL && initproc->yptr == NULL && initproc->optr == NULL); assert(nr_process == 2); assert(list_next(&proc_list) == &(initproc->list_link)); assert(list_prev(&proc_list) == &(initproc->list_link)); assert(nr_free_pages_store == nr_free_pages()); assert(kernel_allocated_store == kallocated()); cprintf("init check memory pass.\n"); return 0; }
user_main实现:
// user_main - kernel thread used to exec a user program static int user_main(void *arg) { #ifdef TEST KERNEL_EXECVE2(TEST, TESTSTART, TESTSIZE); #else KERNEL_EXECVE(exit); #endif panic("user_main execve failed.\n"); } #define __KERNEL_EXECVE(name, binary, size) ({ \ cprintf("kernel_execve: pid = %d, name = \"%s\".\n", \ current->pid, name); \ kernel_execve(name, binary, (size_t)(size)); \ }) #define KERNEL_EXECVE(x) ({ \ extern unsigned char _binary_obj___user_##x##_out_start[], \ _binary_obj___user_##x##_out_size[]; \ __KERNEL_EXECVE(#x, _binary_obj___user_##x##_out_start, \ _binary_obj___user_##x##_out_size); \ }) #define __KERNEL_EXECVE2(x, xstart, xsize) ({ \ extern unsigned char xstart[], xsize[]; \ __KERNEL_EXECVE(#x, xstart, (size_t)xsize); \ }) #define KERNEL_EXECVE2(x, xstart, xsize) __KERNEL_EXECVE2(x, xstart, xsize) // kernel_execve - do SYS_exec syscall to exec a user program called by user_main kernel_thread static int kernel_execve(const char *name, unsigned char *binary, size_t size) { int ret, len = strlen(name); // 内核中执行系统调用SYS_exec asm volatile ( "int %1;" : "=a" (ret) : "i" (T_SYSCALL), "0" (SYS_exec), "d" (name), "c" (len), "b" (binary), "D" (size) : "memory"); return ret; }
exit.c用户程序的加载
在usermain中,通过kernel_execve函数,在内核态发起了系统调用号为SYS_exec的系统调用。通过前面对系统调用机制的介绍,kernel_execve函数发起系统调用号为SYS_exec编号的系统调用后,最终逻辑会执行到系统调用处理表syscalls中的对应的sys_exec函数中。
sys_exec接受四个参数,arg[0]和arg[1]用于指定所要创建、执行的线程名以及其字符串长度;arg[2]和arg[3]用于指定对应elf格式的二进制程序在内存中的地址以及程序的大小。在sys_exec的核心逻辑位于其调用的do_execve中。
sys_exec函数:
static int sys_exec(uint32_t arg[]) { const char *name = (const char *)arg[0]; size_t len = (size_t)arg[1]; unsigned char *binary = (unsigned char *)arg[2]; size_t size = (size_t)arg[3]; return do_execve(name, len, binary, size); }
do_execve函数解析:
在视频的实验公开课中提到,do_execve实现的大致原理就是令被加载的binary二进制程序借着当前线程的壳,用被加载的二进制程序的内存空间替换掉之前线程的内存空间,达到腾笼换鸟的目的。
具体到代码中来,可以看到在进行了基础的校验之后,do_execve首先一步就是将当前线程current对应的mm_struct替换掉,且如果发现被替换掉的mm_struct没有再被其它线程共享,则将其彻底销毁释放。之后通过一个较为复杂的load_icode函数,解析对应的binary二进制程序,生成一个完全不同的,属于被加载程序的mm_struct。
对当前线程current对应的内存总管理器mm_struct的一删一增,导致current当前线程所执行的代码段、所属的数据段和之前完全不同,巧妙的实现了借着之前线程的壳,重新执行一个截然不同的程序的目标。从这里也能更深入的体会到静态的程序与动态的进程/线程的关系。
do_execve实现:
// do_execve - call exit_mmap(mm)&put_pgdir(mm) to reclaim memory space of current process // - call load_icode to setup new memory space accroding binary prog. // 执行binary对应的应用程序 int do_execve(const char *name, size_t len, unsigned char *binary, size_t size) { struct mm_struct *mm = current->mm; if (!user_mem_check(mm, (uintptr_t)name, len, 0)) { return -E_INVAL; } if (len > PROC_NAME_LEN) { len = PROC_NAME_LEN; } char local_name[PROC_NAME_LEN + 1]; memset(local_name, 0, sizeof(local_name)); memcpy(local_name, name, len); if (mm != NULL) { lcr3(boot_cr3); // 由于一般是通过fork一个新线程来执行do_execve,然后通过load_icode进行腾笼换鸟 // 令所加载的新程序占据这个被fork出来的临时线程的壳,所以需要先令当前线程的mm被引用次数-1(后续会创建新的mm给当前线程) if (mm_count_dec(mm) == 0) { // 如果当前线程的mm被引用次数为0,回收整个mm exit_mmap(mm); put_pgdir(mm); mm_destroy(mm); } current->mm = NULL; } int ret; // 开始腾笼换鸟,将二进制格式的elf文件加载到内存中,令current线程执行被加载完毕后的新程序 if ((ret = load_icode(binary, size)) != 0) { goto execve_exit; } // 设置进程名 set_proc_name(current, local_name); return 0; execve_exit: do_exit(ret); panic("already exit: %e.\n", ret); }
load_icode函数解析:
load_icode函数是lab5中十分核心、重要的一个部分。在load_icode中,按顺序执行以下几个步骤,为需要加载运行的新程序构造了完整的运行环境。
1. 为当前进程创建一个新的mm结构。
2. 为新的mm分配并设置一个新的页目录表。
3. 在二进制数据空间中分配内存(虚拟、物理内存空间),从elf格式的二进制程序中复制出对应的代码/数据段,并初始化BSS段(需要对ELF格式的文件有一定的了解)。
4. 为当前进程创建、分配对应的用户栈。
5. 将前面构造好的新的mm_struct结构与当前线程关联起来。
6. 为了令当前应用程序能够在加载后顺利的回到用户态执行,需要构造对应的中断栈帧(设置中断返回时的应用程序入口以及用户态权限的代码段寄存器、数据段、栈段寄存器等等)。在中断返回后欺骗CPU,令CPU以为当前线程在之前发生了一次特权级切换的中断(其实已经是一个和之前线程完全不同的新程序了)。
/* load_icode - load the content of binary program(ELF format) as the new content of current process * @binary: the memory addr of the content of binary program * @size: the size of the content of binary program */ static int load_icode(unsigned char *binary, size_t size) { if (current->mm != NULL) { panic("load_icode: current->mm must be empty.\n"); } int ret = -E_NO_MEM; struct mm_struct *mm; //(1) create a new mm for current process // 为当前进程创建一个新的mm结构 if ((mm = mm_create()) == NULL) { goto bad_mm; } //(2) create a new PDT, and mm->pgdir= kernel virtual addr of PDT // 为mm分配并设置一个新的页目录表 if (setup_pgdir(mm) != 0) { goto bad_pgdir_cleanup_mm; } //(3) copy TEXT/DATA section, build BSS parts in binary to memory space of process // 从进程的二进制数据空间中分配内存,复制出对应的代码/数据段,建立BSS部分 struct Page *page; //(3.1) get the file header of the binary program (ELF format) // 从二进制程序中得到ELF格式的文件头(二进制程序数据的最开头的一部分是elf文件头,以elfhdr指针的形式将其映射、提取出来) struct elfhdr *elf = (struct elfhdr *)binary; //(3.2) get the entry of the program section headers of the bianry program (ELF format) // 找到并映射出binary中程序段头的入口起始位置 struct proghdr *ph = (struct proghdr *)(binary + elf->e_phoff); //(3.3) This program is valid? // 根据elf的魔数,判断其是否是一个合法的ELF文件 if (elf->e_magic != ELF_MAGIC) { ret = -E_INVAL_ELF; goto bad_elf_cleanup_pgdir; } uint32_t vm_flags, perm; // 找到并映射出binary中程序段头的入口截止位置(根据elf->e_phnum进行对应的指针偏移) struct proghdr *ph_end = ph + elf->e_phnum; // 遍历每一个程序段头 for (; ph < ph_end; ph ++) { //(3.4) find every program section headers if (ph->p_type != ELF_PT_LOAD) { // 如果不是需要加载的段,直接跳过 continue ; } if (ph->p_filesz > ph->p_memsz) { // 如果文件头标明的文件段大小大于所占用的内存大小(memsz可能包括了BSS,所以这是错误的程序段头) ret = -E_INVAL_ELF; goto bad_cleanup_mmap; } if (ph->p_filesz == 0) { // 文件段大小为0,直接跳过 continue ; } //(3.5) call mm_map fun to setup the new vma ( ph->p_va, ph->p_memsz) // vm_flags => VMA段的权限 // perm => 对应物理页的权限(因为是用户程序,所以设置为PTE_U用户态) vm_flags = 0, perm = PTE_U; // 根据文件头中的配置,设置VMA段的权限 if (ph->p_flags & ELF_PF_X) vm_flags |= VM_EXEC; if (ph->p_flags & ELF_PF_W) vm_flags |= VM_WRITE; if (ph->p_flags & ELF_PF_R) vm_flags |= VM_READ; // 设置程序段所包含的物理页的权限 if (vm_flags & VM_WRITE) perm |= PTE_W; // 在mm中建立ph->p_va到ph->va+ph->p_memsz的合法虚拟地址空间段 if ((ret = mm_map(mm, ph->p_va, ph->p_memsz, vm_flags, NULL)) != 0) { goto bad_cleanup_mmap; } unsigned char *from = binary + ph->p_offset; size_t off, size; uintptr_t start = ph->p_va, end, la = ROUNDDOWN(start, PGSIZE); ret = -E_NO_MEM; //(3.6) alloc memory, and copy the contents of every program section (from, from+end) to process's memory (la, la+end) end = ph->p_va + ph->p_filesz; //(3.6.1) copy TEXT/DATA section of bianry program // 上面建立了合法的虚拟地址段,现在为这个虚拟地址段分配实际的物理内存页 while (start < end) { // 分配一个内存页,建立la对应页的虚实映射关系 if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) { goto bad_cleanup_mmap; } off = start - la, size = PGSIZE - off, la += PGSIZE; if (end < la) { size -= la - end; } // 根据elf中程序头的设置,将binary中的对应数据复制到新分配的物理页中 memcpy(page2kva(page) + off, from, size); start += size, from += size; } //(3.6.2) build BSS section of binary program // 设置当前程序段的BSS段 end = ph->p_va + ph->p_memsz; // start < la代表BSS段存在,且最后一个物理页没有被填满。剩下空间作为BSS段 if (start < la) { /* ph->p_memsz == ph->p_filesz */ if (start == end) { continue ; } off = start + PGSIZE - la, size = PGSIZE - off; if (end < la) { size -= la - end; } // 将BSS段所属的部分格式化清零 memset(page2kva(page) + off, 0, size); start += size; assert((end < la && start == end) || (end >= la && start == la)); } // start < end代表还需要为BSS段分配更多的物理空间 while (start < end) { // 为BSS段分配更多的物理页 if ((page = pgdir_alloc_page(mm->pgdir, la, perm)) == NULL) { goto bad_cleanup_mmap; } off = start - la, size = PGSIZE - off, la += PGSIZE; if (end < la) { size -= la - end; } // 将BSS段所属的部分格式化清零 memset(page2kva(page) + off, 0, size); start += size; } } //(4) build user stack memory // 建立用户栈空间 vm_flags = VM_READ | VM_WRITE | VM_STACK; // 为用户栈设置对应的合法虚拟内存空间 if ((ret = mm_map(mm, USTACKTOP - USTACKSIZE, USTACKSIZE, vm_flags, NULL)) != 0) { goto bad_cleanup_mmap; } assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-PGSIZE , PTE_USER) != NULL); assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-2*PGSIZE , PTE_USER) != NULL); assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-3*PGSIZE , PTE_USER) != NULL); assert(pgdir_alloc_page(mm->pgdir, USTACKTOP-4*PGSIZE , PTE_USER) != NULL); //(5) set current process's mm, sr3, and set CR3 reg = physical addr of Page Directory // 当前mm被线程引用次数+1 mm_count_inc(mm); // 设置当前线程的mm current->mm = mm; // 设置当前线程的cr3 current->cr3 = PADDR(mm->pgdir); // 将指定的页表地址mm->pgdir,加载进cr3寄存器 lcr3(PADDR(mm->pgdir)); //(6) setup trapframe for user environment // 设置用户环境下的中断栈帧 struct trapframe *tf = current->tf; memset(tf, 0, sizeof(struct trapframe)); /* LAB5:EXERCISE1 YOUR CODE * should set tf_cs,tf_ds,tf_es,tf_ss,tf_esp,tf_eip,tf_eflags * NOTICE: If we set trapframe correctly, then the user level process can return to USER MODE from kernel. So * tf_cs should be USER_CS segment (see memlayout.h) * tf_ds=tf_es=tf_ss should be USER_DS segment * tf_esp should be the top addr of user stack (USTACKTOP) * tf_eip should be the entry point of this binary program (elf->e_entry) * tf_eflags should be set to enable computer to produce Interrupt */ // 为了令内核态完成加载的应用程序能够在加载流程完毕后顺利的回到用户态运行,需要对当前的中断栈帧进行对应的设置 // CS段设置为用户态段(平坦模型下只有一个唯一的用户态代码段USER_CS) tf->tf_cs = USER_CS; // DS、ES、SS段设置为用户态的段(平坦模型下只有一个唯一的用户态数据段USER_DS) tf->tf_ds = tf->tf_es = tf->tf_ss = USER_DS; // DS // 设置用户态的栈顶指针 tf->tf_esp = USTACKTOP; // 设置系统调用中断返回后执行的程序入口,令其为elf头中设置的e_entry(中断返回后会复原中断栈帧中的eip) tf->tf_eip = elf->e_entry; // 默认中断返回后,用户态执行时是开中断的 tf->tf_eflags = FL_IF; ret = 0; out: return ret; bad_cleanup_mmap: exit_mmap(mm); bad_elf_cleanup_pgdir: put_pgdir(mm); bad_pgdir_cleanup_mm: mm_destroy(mm); bad_mm: goto out; }
2.4 exit.c应用程序执行流程分析
在load_icode、sys_exec函数返回,整个系统中断的服务例程完成之后。根据构造好的trapframe中断栈帧,执行iret指令中断返回后,CPU的指令指针寄存器eip将指向elf->entry,即用户程序的执行入口(exit.c的main函数入口)。且其CS代码段寄存器、DS/ES/SS等数据段寄存器的特权级均处于ring3用户态。
在exit.c中,main函数中通过ulib.h中提供的用户库,执行了fork系统调用。fork完成后将会出现父子两个线程,其中子线程在进行了多次yield后调用了exit库函数进行了线程退出操作。而父线程则在fork完毕后通过调用waitpid的库函数等待对应的子线程退出,将其最终回收。而作为应用程序的父线程在另一方面也是内核线程initproc创建的子线程(init_main函数)。当父线程的main函数执行完毕后,initmain函数中initproc也调用了do_wait函数在等待用户态的user_main线程最终退出。
exit.c应用程序:
#include <stdio.h> #include <ulib.h> int magic = -0x10384; /** * 用户态的应用程序 * */ int main(void) { int pid, code; cprintf("I am the parent. Forking the child...\n"); // 通过fork库函数执行do_fork系统调用复制一个子线程执行 if ((pid = fork()) == 0) { // 子线程fork返回后的pid为0 cprintf("I am the child.\n"); yield(); yield(); yield(); yield(); yield(); yield(); yield(); // 通过exit库函数执行do_exit系统调用,退出子线程 exit(magic); } else { // 父线程会执行到这里,fork返回的pid为子线程的pid,不等于0 cprintf("I am parent, fork a child pid %d\n",pid); } assert(pid > 0); cprintf("I am the parent, waiting now..\n"); // 父线程通过wait库函数执行do_wait系统调用,等待子线程退出并回收(waitpid返回值=0代表回收成功) assert(waitpid(pid, &code) == 0 && code == magic); // 再次回收会失败waitpid返回值不等于0 assert(waitpid(pid, &code) != 0 && wait() != 0); cprintf("waitpid %d ok.\n", pid); cprintf("exit pass.\n"); return 0; }
init_main函数:
// init_main - the second kernel thread used to create user_main kernel threads static int init_main(void *arg) { size_t nr_free_pages_store = nr_free_pages(); size_t kernel_allocated_store = kallocated(); // fork创建一个线程执行user_main int pid = kernel_thread(user_main, NULL, 0); if (pid <= 0) { panic("create user_main failed.\n"); } // do_wait等待回收僵尸态子线程(第一个参数pid为0代表回收任意僵尸子线程) while (do_wait(0, NULL) == 0) { // 回收一个僵尸子线程后,进行调度 schedule(); } // 跳出了上述循环代表init_main的所有子线程都退出并回收完了 cprintf("all user-mode processes have quit.\n"); assert(initproc->cptr == NULL && initproc->yptr == NULL && initproc->optr == NULL); assert(nr_process == 2); assert(list_next(&proc_list) == &(initproc->list_link)); assert(list_prev(&proc_list) == &(initproc->list_link)); assert(nr_free_pages_store == nr_free_pages()); assert(kernel_allocated_store == kallocated()); cprintf("init check memory pass.\n"); return 0; }
lab5_answer执行的结果截图:
可以看到,exit.c中的打印语句和init_main中的打印语句按照各自父子线程的退出顺序,依次的被执行了。
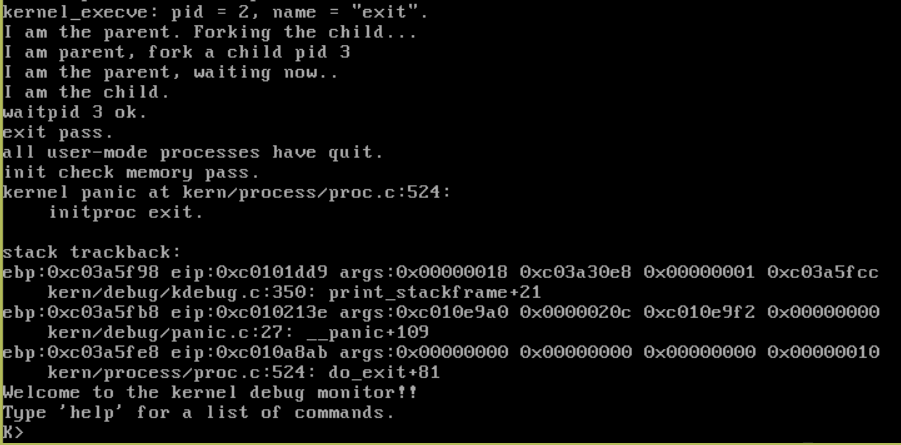
下面我们分析exit.c应用程序执行的流程,分析为什么会以这样的顺序执行打印语句?
首先,前面分析了内核线程在user_main里在内核状态下发起了sys_execve系统调用,解析并加载了应用程序exit.c。在系统调用中断返回后,exit.c回到了用户态并跳转到main函数入口处开始执行。
在exit.c的main函数中,首先执行了语句"cprintf("I am the parent. Forking the child...\n");",然后便通过用户库执行了fork系统调用,fork系统调用最终的处理逻辑在内核的syscall.c中定义的sys_fork处。sys_fork中调用do_fork函数用于fork复制一个子线程。
sys_fork函数:
static int sys_fork(uint32_t arg[]) { struct trapframe *tf = current->tf; uintptr_t stack = tf->tf_esp; return do_fork(0, stack, tf); }
do_fork函数:
/* do_fork - parent process for a new child process * @clone_flags: used to guide how to clone the child process * @stack: the parent's user stack pointer. if stack==0, It means to fork a kernel thread. * @tf: the trapframe info, which will be copied to child process's proc->tf */ int do_fork(uint32_t clone_flags, uintptr_t stack, struct trapframe *tf) { int ret = -E_NO_FREE_PROC; struct proc_struct *proc; if (nr_process >= MAX_PROCESS) { goto fork_out; } ret = -E_NO_MEM; // 1. call alloc_proc to allocate a proc_struct // 2. call setup_kstack to allocate a kernel stack for child process // 3. call copy_mm to dup OR share mm according clone_flag // 4. call copy_thread to setup tf & context in proc_struct // 5. insert proc_struct into hash_list && proc_list // 6. call wakeup_proc to make the new child process RUNNABLE // 7. set ret vaule using child proc's pid // 分配一个未初始化的线程控制块 if ((proc = alloc_proc()) == NULL) { goto fork_out; } // 其父进程属于current当前进程 proc->parent = current; assert(current->wait_state == 0); // 设置,分配新线程的内核栈 if (setup_kstack(proc) != 0) { // 分配失败,回滚释放之前所分配的内存 goto bad_fork_cleanup_proc; } // 由于是fork,因此fork的一瞬间父子线程的内存空间是一致的(clone_flags决定是否采用写时复制) if (copy_mm(clone_flags, proc) != 0) { // 分配失败,回滚释放之前所分配的内存 goto bad_fork_cleanup_kstack; } // 复制proc线程时,设置proc的上下文信息 copy_thread(proc, stack, tf); bool intr_flag; local_intr_save(intr_flag); { // 生成并设置新的pid proc->pid = get_pid(); // 加入全局线程控制块哈希表 hash_proc(proc); set_links(proc); } local_intr_restore(intr_flag); // 唤醒proc,令其处于就绪态PROC_RUNNABLE wakeup_proc(proc); ret = proc->pid; fork_out: return ret; bad_fork_cleanup_kstack: put_kstack(proc); bad_fork_cleanup_proc: kfree(proc); goto fork_out; }
fork返回时父子线程的返回值为什么不同?
do_fork函数在lab4中有着比较详细的介绍,而在lab5中需要注意的一点是:由于fork函数会在复制创建新的子线程的那一瞬间将父线程对应的mm_struct进行复制,因此其指令指针在fork的一瞬间是一致的。对于父线程而言,执行执行完copy_thread函数之后,会继续执行do_fork函数的后续逻辑。
如果父线程的fork流程执行过程中没有出错最终会执行到ret = proc->pid,do_fork系统调用再到最终用户库的fork函数便会返回子线程的pid,一个大于0的值。
子线程则由于在do_fork的copy_thread逻辑中,通过"proc->tf->tf_regs.reg_eax = 0;"设置了中断栈帧的eax的值为0,且由于其陷入内核时的中断栈帧中指令指针和父线程一样(sys_fork函数中传入的中断栈帧),在iret返回到用户态时,也会进行fork函数的调用返回。但返回时用户态中断栈帧复原时eax的值为0,导致exit.c中子线程fork函数的返回值为0。
父线程fork时返回的是子线程的pid,而子线程fork的返回值为0。可以通过判断fork函数的返回值是否为0,编写对应父子线程的不同处理逻辑。
copy_thread函数:
// copy_thread - setup the trapframe on the process's kernel stack top and // - setup the kernel entry point and stack of process static void copy_thread(struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) { // 令proc-tf 指向proc内核栈顶向下偏移一个struct trapframe大小的位置 proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1; // 将参数tf中的结构体数据复制填入上述proc->tf指向的位置(正好是上面struct trapframe指针-1腾出来的那部分空间) *(proc->tf) = *tf; proc->tf->tf_regs.reg_eax = 0; proc->tf->tf_esp = esp; proc->tf->tf_eflags |= FL_IF; // 令proc上下文中的eip指向forkret,切换恢复上下文后,新线程proc便会跳转至forkret proc->context.eip = (uintptr_t)forkret; // 令proc上下文中的esp指向proc->tf,指向中断返回时的中断栈帧 proc->context.esp = (uintptr_t)(proc->tf); }
在父线程fork完成之后,fork的返回值不为0,因此会执行else块的逻辑打印(I am parent, fork a child pid %d),以及打印(I am the parent, waiting now..)。子线程则会打印(I am the child)。
在exit子线程的逻辑中,最终会通过exit,执行sys_exit系统调用,用于退出当前线程。
在ucore lab5的参考示例代码中,idleproc线程的pid为0、initproc线程的pid为1;而执行user_main的父线程pid为2,其fork出的子线程pid为3。
sys_exit实现:
在sys_exit的实现中,由于线程需要退出,当前需要退出的线程会尽可能的将自己持有的包括占用的内存空间的等各种资源释放。但是由于要执行指令,需要退出的线程的内核栈是无法自己回收的;当前退出线程的线程控制块由于调度的需要,也是无法自己回收掉的。线程退出最终的回收工作需要其父线程来完成。
因此,在do_exit函数的最后,当前线程会将自己的线程状态设置为僵尸态,并且尝试着唤醒可能在等待子线程退出而被阻塞的父线程。
如果当前退出的子线程还拥有着自己的子线程,那么还需要将其托管给内核的第一个线程initproc,令initproc代替被退出线程,成为这些子线程的父线程,以完成后续的子线程回收工作(initproc作为后续创建的其它线程的祖先,是用来兜底的)。
static int sys_exit(uint32_t arg[]) { int error_code = (int)arg[0]; return do_exit(error_code); } // do_exit - called by sys_exit // 1. call exit_mmap & put_pgdir & mm_destroy to free the almost all memory space of process // 调用exit_mmap & put_pgdir & mm_destroy去释放退出线程占用的几乎全部的内存空间(线程栈等需要父进程来回收) // 2. set process' state as PROC_ZOMBIE, then call wakeup_proc(parent) to ask parent reclaim itself. // 设置线程的状态为僵尸态PROC_ZOMBIE,然后唤醒父进程去回收退出的进程 // 3. call scheduler to switch to other process // 调用调度器切换为其它线程 int do_exit(int error_code) { if (current == idleproc) { panic("idleproc exit.\n"); } if (current == initproc) { panic("initproc exit.\n"); } struct mm_struct *mm = current->mm; if (mm != NULL) { // 内核线程的mm是null,mm != null说明是用户线程退出了 lcr3(boot_cr3); // 由于mm是当前进程内所有线程共享的,当最后一个线程退出时(mm->mm_count == 0),需要彻底释放整个mm管理的内存空间 if (mm_count_dec(mm) == 0) { // 解除mm对应一级页表、二级页表的所有虚实映射关系 exit_mmap(mm); // 释放一级页表(页目录表)所占用的内存空间 put_pgdir(mm); // 将mm中的vma链表清空(释放所占用内存),并回收mm所占物理内存 mm_destroy(mm); } current->mm = NULL; } // 设置当前线程状态为僵尸态,等待父线程回收 current->state = PROC_ZOMBIE; // 设置退出线程的原因(exit_code) current->exit_code = error_code; bool intr_flag; struct proc_struct *proc; local_intr_save(intr_flag); { proc = current->parent; // 如果父线程等待状态为WT_CHILD if (proc->wait_state == WT_CHILD) { // 唤醒父线程,令其进入就绪态,准备回收该线程(调用了do_wait等待) wakeup_proc(proc); } // 遍历当前退出线程的子线程(通过子线程链表) while (current->cptr != NULL) { // proc为子线程链表头 proc = current->cptr; // 遍历子线程链表的每一个子线程 current->cptr = proc->optr; proc->yptr = NULL; if ((proc->optr = initproc->cptr) != NULL) { initproc->cptr->yptr = proc; } // 将退出线程的子线程托管给initproc,令其父线程为initproc proc->parent = initproc; initproc->cptr = proc; if (proc->state == PROC_ZOMBIE) { // 如果当前遍历的线程proc为僵尸态 if (initproc->wait_state == WT_CHILD) { // initproc等待状态为WT_CHILD(调用了do_wait等待) // 唤醒initproc,令其准备回收僵尸态的子线程 wakeup_proc(initproc); } } } } local_intr_restore(intr_flag); // 当前线程退出后,进行其它就绪态线程的调度 schedule(); panic("do_exit will not return!! %d.\n", current->pid); }
在exit父线程的逻辑中,会调用waitpid同步阻塞等待对应pid的子线程退出,完成最终的回收工作。wait_pid最终会执行sys_wait系统调用,主要逻辑位于内核的sys_wait函数中。
sys_wait实现:
sys_wait的核心逻辑在do_wait函数中,根据传入的参数pid决定是回收指定pid的子线程还是任意一个子线程。
1. 如果当前线程不存在任何可以回收的子线程,sys_wait会直接返回一个错误码。
2. 如果调用sys_wait时当前线程能够找到一个符合要求的,且可以立即回收的僵尸态子线程,那么就会将其回收(一次sys_wait只会回收一个子线程)。
3. 如果调用sys_wait时当前线程存在可以回收的子线程,但是却不是僵尸态。那么当前线程将进入阻塞态,等待可以回收的子线程退出(前面介绍的sys_exit中就有子线程退出时对应的父线程唤醒机制)。
static int sys_wait(uint32_t arg[]) { int pid = (int)arg[0]; int *store = (int *)arg[1]; return do_wait(pid, store); } // do_wait - wait one OR any children with PROC_ZOMBIE state, and free memory space of kernel stack // - proc struct of this child. // 令当前线程等待一个或多个子线程进入僵尸态,并且回收其内核栈和线程控制块 // NOTE: only after do_wait function, all resources of the child proces are free. // 注意:只有在do_wait函数执行完成之后,子线程的所有资源才被完全释放 int do_wait(int pid, int *code_store) { struct mm_struct *mm = current->mm; if (code_store != NULL) { if (!user_mem_check(mm, (uintptr_t)code_store, sizeof(int), 1)) { return -E_INVAL; } } struct proc_struct *proc; bool intr_flag, haskid; repeat: haskid = 0; if (pid != 0) { // 参数指定了pid(pid不为0),代表回收pid对应的僵尸态线程 proc = find_proc(pid); // 对应的线程必须是当前线程的子线程 if (proc != NULL && proc->parent == current) { haskid = 1; if (proc->state == PROC_ZOMBIE) { // pid对应的线程确实是僵尸态,跳转found进行回收 goto found; } } } else { // 参数未指定pid(pid为0),代表回收当前线程的任意一个僵尸态子线程 proc = current->cptr; for (; proc != NULL; proc = proc->optr) { // 遍历当前线程的所有子线程进行查找 haskid = 1; if (proc->state == PROC_ZOMBIE) { // 找到了一个僵尸态子线程,跳转found进行回收 goto found; } } } if (haskid) { // 当前线程需要回收僵尸态子线程,但是没有可以回收的僵尸态子线程(如果找到去执行found段会直接返回,不会执行到这里) // 令当前线程进入休眠态,让出CPU current->state = PROC_SLEEPING; // 令其等待状态置为等待子进程退出 current->wait_state = WT_CHILD; // 进行一次线程调度(当有子线程退出进入僵尸态时,父线程会被唤醒) schedule(); if (current->flags & PF_EXITING) { // 如果当前线程被杀了(do_kill),将自己退出(被唤醒之后发现自己已经被判了死刑,自我了断) do_exit(-E_KILLED); } // schedule调度完毕后当前线程被再次唤醒,跳转到repeat循环起始位置,继续尝试回收一个僵尸态子线程 goto repeat; } return -E_BAD_PROC; found: if (proc == idleproc || proc == initproc) { // idleproc和initproc是不应该被回收的 panic("wait idleproc or initproc.\n"); } if (code_store != NULL) { // 将子线程退出的原因保存在*code_store中返回 *code_store = proc->exit_code; } local_intr_save(intr_flag); { // 暂时关中断,避免中断导致并发问题 // 从线程控制块hash表中移除被回收的子线程 unhash_proc(proc); // 从线程控制块链表中移除被回收的子线程 remove_links(proc); } local_intr_restore(intr_flag); // 释放被回收的子线程的内核栈 put_kstack(proc); // 释放被回收的子线程的线程控制块结构 kfree(proc); return 0; }
在exit.c中fork完毕的子线程通过sys_exit成功退出后,waitpid的父线程也随之被唤醒进行对应子线程的回收工作。依照顺序执行打印语句"waitpid %d ok."和"exit pass.\n"(由于子线程在exit之后就不会得到CPU了,因此不会打印这些)。
之后执行exit.c的父线程main函数也执行完毕并返回,执行流就到了lab4中提到的/kern/process/entry.S中。在entry.S中,最终也是调用了内核的do_exit函数令当前线程退出。
entry.S:
.text .globl kernel_thread_entry kernel_thread_entry: # void kernel_thread(void) pushl %edx # push arg call *%ebx # call fn pushl %eax # save the return value of fn(arg) call do_exit # call do_exit to terminate current thread
在执行exit.c的父线程也退出后,最初加载exit.c应用程序的initproc作为它的父线程被唤醒并通过do_wait进行了最终的回收工作(init_main函数)。最终打印出了"all user-mode processes have quit."。
至此,lab5中整个实验细节的分析就结束了。
3. 总结
ucore在lab5中实现了运行在用户态的进程/线程机制。用户态的进程通常用于执行权限受到限制的应用程序,避免应用程序的编写者有意或无意的破坏操作系统内核。同时也实现了系统调用机制,为应用程序提供安全可靠的服务的同时也避免受到内核保护的各种资源被破坏。在实现了较为完善的进程/线程机制之后,也为后续的lab6、lab7中的线程CPU调度以及线程并发控制机制打下了基础。
通过lab5的学习,使我学到了很多:
1. 了解了系统调用的实现原理。意识到通过中断实现的系统调用效率是很低的,这也是为什么在应用程序的开发中要尽量避免使用系统调用而陷入内核的主要原因(比如陷入内核阻塞线程的操作系统级的悲观锁以及用户态轮询重试的乐观锁)。
2. 了解了线程是如何去加载并执行一个应用程序的。对动态的进程/线程与静态的程序之间的关系有了更深的理解。
3. 了解了诸如fork、exit、wait等系统调用的大致工作原理。
这篇博客的完整代码注释在我的github上:https://github.com/1399852153/ucore_os_lab (fork自官方仓库)中的lab5_answer。
希望我的博客能帮助到对操作系统、ucore os感兴趣的人。存在许多不足之处,还请多多指教。

