
ucore操作系统学习(三) ucore lab3虚拟内存管理分析
1. ucore lab3介绍
虚拟内存介绍
在目前的硬件体系结构中,程序要想在计算机中运行,必须先加载至物理主存中。在支持多道程序运行的系统上,我们想要让包括操作系统内核在内的各种程序能并发的执行,而物理主存的总量通常是极为有限的,这限制了并发程序的发展。受制于成本问题,拥有足够大容量主存的个人计算机是普通人承受不起的。因此计算机科学家们另辟蹊径,想到了利用局部性原理来解决既要能并发运行大量程序又要使计算机足够低成本这一矛盾问题。
局部性原理告诉我们,大多数程序通常都在执行循环逻辑,访问数据时访问最频繁的也是数组等连续结构。一个程序在某一时刻所执行的代码和所访问的数据通常都聚集在一个很小的范围内。
虚拟内存机制的核心思想是将物理主存扩展到磁盘外存这一容量更大,单位存储成本更低的存储介质上,令主存在某种程度上作为了磁盘的缓存。因为即使程序所需要的内存很大,某一时刻所访问的内存都聚集在一个很小的页面集合中(工作集),操作系统可以将那些暂时不会被访问到的内存页置换到磁盘上,等到需要访问时再从磁盘中读出置换回主存。
操作系统提供的这一层抽象,使得应用程序可以申请使用的内存远大于实际可用物理主存的大小,但内存数据可能并不是都存放在物理主存中,而是在磁盘上,这也是虚拟内存这一名称的由来。由于局部性的存在,通过高效的置换算法进行调度,其访问速度相比完全使用主存而言速度并未受到太大影响。
而ucore在lab3中,将实现虚拟内存机制,结合lab2完成的物理内存管理功能,完整的构建起ucore的内存管理子系统。
lab3相比lab2的改进
lab3在lab2的基础上,主要新增了以下功能:
1. kern_init总控函数中新增了vmm_init、ide_init、swap_init函数入口,分别完成了虚拟内存管理器、ide硬盘交互以及虚拟内存磁盘置换器的初始化。
2. 在trap.c的中断处理分发函数trap_dispatch中新增了对14号中断(页访问异常)的处理逻辑do_pgfault。
2. ucore lab3实验细节分析
lab3是建立在之前实验的基础之上的。在虚拟内存功能的实现中,ucore需要借助lab1中建立的中断机制来处理缺页异常,同时也依赖lab2中实现的物理内存管理功能。所以必须先理解之前的实验内容后才能顺利的理解lab3的内容: ucore lab1学习笔记、ucore lab2学习笔记。
2.1 ucore虚拟内存管理框架介绍
80386是32位的cpu,其支持4GB的寻址范围。而在ucore虚拟内存的功能建立后,应用程序能够拥有最大4GB的虚拟地址空间。但多数程序并不会真的申请完整的4GB虚拟地址空间,而是只需要部分空间,则未申请的虚拟地址空间会被视为非法的虚拟地址空间,在进程对应的页表中将不存在非法虚拟地址的映射关系,访问将会出错。这也是为什么在*常编写的应用程序中,在访问一个野指针时,有时候会得到一个莫名其妙的值,有时候程序会直接奔溃,导致奔溃的一个原因就是因为野指针指向了一个非法的虚拟地址。
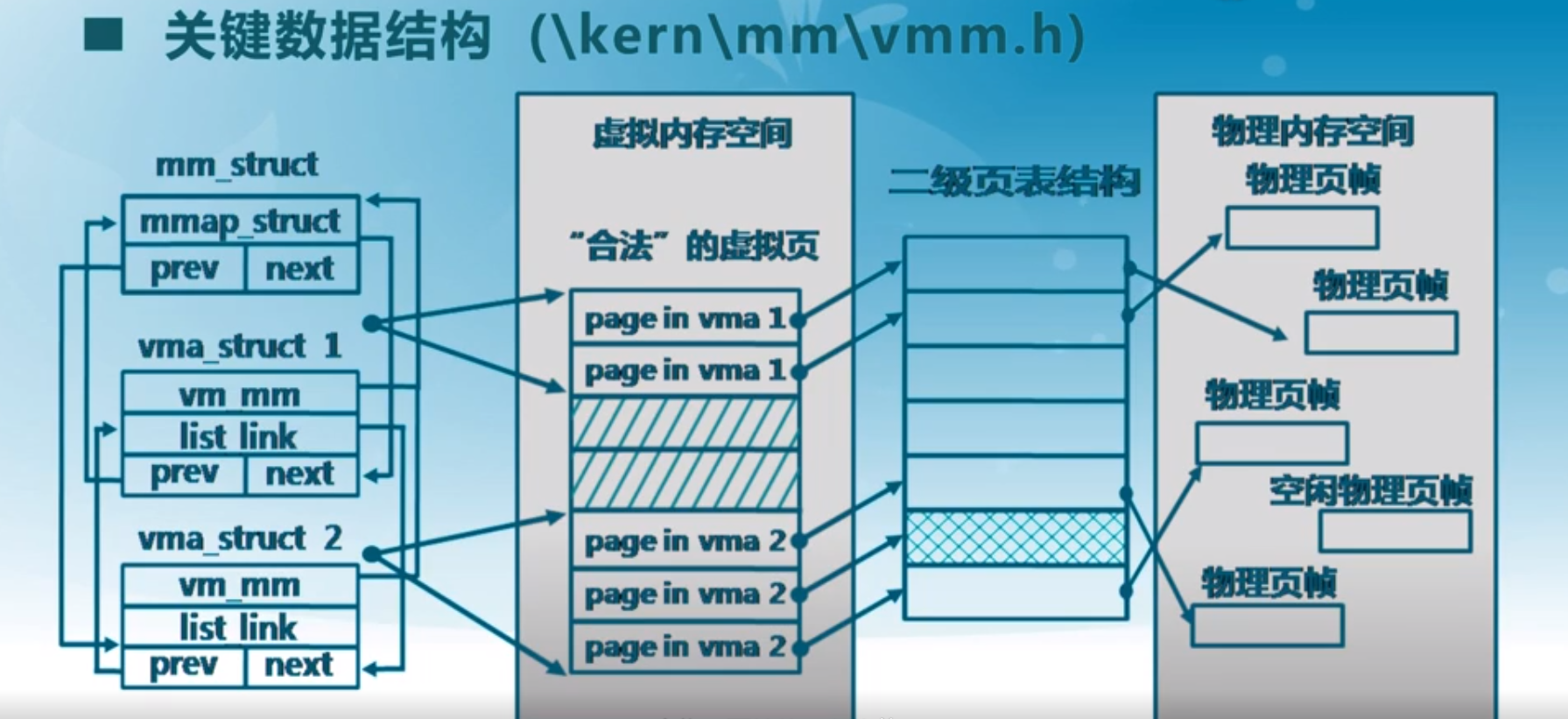
ucore在lab3中新增了vma_struct结构(kern/mm/vmm.h)来描述合法的连续虚拟内存空间块,一个进程合法的虚拟地址空间段将以vma集合的方式表示。
在ucore中,以vma_struct虚地址空间的大小顺序可以组成一个双向循环链表,与lab2类似,vma_struct反向包裹list_link链表节点属性,利用le2vma宏可以使用page_link节点找到所关联的vma_struct。
vma_struct结构:
// the virtual continuous memory area(vma) // 连续虚拟内存区域 struct vma_struct { // 关联的上层内存管理器 struct mm_struct *vm_mm; // the set of vma using the same PDT // 描述的虚拟内存的起始地址 uintptr_t vm_start; // start addr of vma // 描述的虚拟内存的截止地址 uintptr_t vm_end; // end addr of vma // 当前虚拟内存块的属性flags // bit0 VM_READ标识是否可读; bit1 VM_WRITE标识是否可写; bit2 VM_EXEC标识是否可执行 uint32_t vm_flags; // flags of vma // 连续虚拟内存块链表节点 (mm_struct->mmap_list) list_entry_t list_link; // linear list link which sorted by start addr of vma }; #define le2vma(le, member) \ to_struct((le), struct vma_struct, member) #define VM_READ 0x00000001 #define VM_WRITE 0x00000002 #define VM_EXEC 0x00000004
ucore提供了mm_struct结构(kern/mm/vmm.h)作为一个总的内存管理器,统一的管理一个进程的虚拟内存以及物理内存。
其中,mm_struct的mmap_list用来存储上面提到的用于表示进程合法虚拟地址空间集合的vma双向循环链表。
mm_struct结构:
// the control struct for a set of vma using the same PDT struct mm_struct { // 连续虚拟内存块链表 (内部节点虚拟内存块的起始、截止地址必须全局有序,且不能出现重叠) list_entry_t mmap_list; // linear list link which sorted by start addr of vma // 当前访问的mmap_list链表中的vma块(由于局部性原理,之前访问过的vma有更大可能会在后续继续访问,该缓存可以减少从mmap_list中进行遍历查找的次数,提高效率) struct vma_struct *mmap_cache; // current accessed vma, used for speed purpose // 当前mm_struct关联的一级页表的指针 pde_t *pgdir; // the PDT of these vma // 当前mm_struct->mmap_list中vma块的数量 int map_count; // the count of these vma // 用于虚拟内存置换算法的属性,使用void*指针做到通用 (lab中默认的swap_fifo替换算法中,将其做为了一个先进先出链表队列) void *sm_priv; // the private data for swap manager };
关系结构图:
2.2 虚拟内存关联物理页换入换出分析
下面分析ucore lab3中,虚拟内存关联物理页的换入、换出的细节。
什么时候进行换出?
虚拟内存页的换出分为主动与被动两种换出策略,在lab3中,ucore只实现了基于被动的换出策略。在ucore中,当申请分配物理页面时如果发现可用的物理内存不足时,会进行可置换物理页的换出。通过某种置换算法将选中的物理页暂时置换到磁盘的交换分区中,以腾出空闲的物理页以供分配。
分配物理内存的代码位于pmm.c中的alloc_pages函数,alloc_pages是在lab2中已有的,在lab3中为了支持虚拟内存的实现进行了一定的改动。
alloc_pages函数:
//alloc_pages - call pmm->alloc_pages to allocate a continuous n*PAGESIZE memory struct Page * alloc_pages(size_t n) { struct Page *page=NULL; bool intr_flag; while (1) { // 关闭中断,避免分配内存时,物理内存管理器内部的数据结构变动时被中断打断,导致数据错误 local_intr_save(intr_flag); { // 分配n个物理页 page = pmm_manager->alloc_pages(n); } // 恢复中断控制位 local_intr_restore(intr_flag); // 满足下面之中的一个条件,就跳出while循环 // page != null 表示分配成功 // 如果n > 1 说明不是发生缺页异常来申请的(否则n=1) // 如果swap_init_ok == 0 说明没有开启分页模式 if (page != NULL || n > 1 || swap_init_ok == 0) break; extern struct mm_struct *check_mm_struct; //cprintf("page %x, call swap_out in alloc_pages %d\n",page, n); // 尝试着将某一物理页置换到swap磁盘交换扇区中,以腾出一个新的物理页来 // 如果交换成功,则理论上下一次循环,pmm_manager->alloc_pages(1)将有机会分配空闲物理页成功 swap_out(check_mm_struct, n, 0); } //cprintf("n %d,get page %x, No %d in alloc_pages\n",n,page,(page-pages)); return page; }
什么时候进行换入?
当CPU进行内存访问时,发现所得到的线性地址对应的二级页表项的P位为0(不存在),便产生页异常中断(页异常还可能在其它情况下出现),ucore会接受异常并进入页异常中断服务例程。
回顾一下lab1,硬件在一些中断发生时会将错误号压入栈中,ucore建立的中断机制可以通过中断栈帧trap_frame中的tr_err获取到一个32位的错误号。在页异常中断中,这个错误号的不同bit位标识了发生异常时的各种信息,同时80386的cr2页异常地址寄存器中也会保留最后一次页异常发生时所访问的32位线性地址。
捕获页异常逻辑:
static void trap_dispatch(struct trapframe *tf) { char c; int ret; switch (tf->tf_trapno) { case T_PGFLT: //page fault // T_PGFLT 14号中断 页异常处理 if ((ret = pgfault_handler(tf)) != 0) { // 页异常处理失败,打印栈帧 print_trapframe(tf); panic("handle pgfault failed. %e\n", ret); } break; // 不完全。。。。。。 } static int pgfault_handler(struct trapframe *tf) { extern struct mm_struct *check_mm_struct; print_pgfault(tf); if (check_mm_struct != NULL) { // 传入check_mm_struct是为了配合check_pgfault检查函数的 // 在未来的实验中同一进程是共用一个mm_struct内存管理器,而截止lab3只存在一个进程:内核进程 // rcr2页异常发生时,cr2页故障线性地址寄存器,保存最后一次出现页故障的32位线性地址 return do_pgfault(check_mm_struct, tf->tf_err, rcr2()); } panic("unhandled page fault.\n"); }
页访问异常错误码示意图:

真正处理页异常的核心逻辑位于vmm.c中的do_pgfault函数。do_pgfault除了接受前面提到的32位中断错误号和引起错误的线性地址,还接受了当前进程的mm_struct结构,用以访问当前进程的页表。do_pgfault对错误码进行了处理,判断其究竟是否是因为缺页造成的页访问异常;还是因为非法的虚拟地址访问、特权级的越级内存访问等错误引发的页异常,如果是后者就应该报错或者让进程直接奔溃掉。
如果发现访问的是一个合法的虚拟地址,则会进一步找到引起异常的线性地址所对应的二级页表项,判断其是真的不存在(pte中的每一位都是0)还是之前被暂时交换到了磁盘上(仅仅是P位为0)。
如果是真的不存在,则需要立即为其分配一个初始化后全新的物理页,并建立映射虚实关系。
如果是被暂时交换到了磁盘中,则需要将交换扇区中的数据重新读出并覆盖所分配到的物理页。
页异常中断属于异常中断的一种,当中断服务例程返回后,会重新执行引起页异常的那条指令,如果do_pafault实现正确,那么此时将能够正确的访问到虚拟地址对应的物理页,程序能正常的往下继续执行。
do_pgfault函数:
int do_pgfault(struct mm_struct *mm, uint32_t error_code, uintptr_t addr) { int ret = -E_INVAL; //try to find a vma which include addr // 试图从mm关联的vma链表块中查询,是否存在当前addr线性地址匹配的vma块 struct vma_struct *vma = find_vma(mm, addr); // 全局页异常处理数自增1 pgfault_num++; //If the addr is in the range of a mm's vma? if (vma == NULL || vma->vm_start > addr) { // 如果没有匹配到vma cprintf("not valid addr %x, and can not find it in vma\n", addr); goto failed; } //check the error_code // 页访问异常错误码有32位。位0为1 表示对应物理页不存在;位1为1 表示写异常(比如写了只读页);位2为1 表示访问权限异常(比如用户态程序访问内核空间的数据) // 对3求模,主要判断bit0、bit1的值 switch (error_code & 3) { default: /* error code flag : default is 3 ( W/R=1, P=1): write, present */ // bit0,bit1都为1,访问的映射页表项存在,且发生的是写异常 // 说明发生了缺页异常 case 2: /* error code flag : (W/R=1, P=0): write, not present */ // bit0为0,bit1为1,访问的映射页表项不存在、且发生的是写异常 if (!(vma->vm_flags & VM_WRITE)) { // 对应的vma块映射的虚拟内存空间是不可写的,权限校验失败 cprintf("do_pgfault failed: error code flag = write AND not present, but the addr's vma cannot write\n"); // 跳转failed直接返回 goto failed; } // 校验通过,则说明发生了缺页异常 break; case 1: /* error code flag : (W/R=0, P=1): read, present */ // bit0为1,bit1为0,访问的映射页表项存在,且发生的是读异常(可能是访问权限异常) cprintf("do_pgfault failed: error code flag = read AND present\n"); // 跳转failed直接返回 goto failed; case 0: /* error code flag : (W/R=0, P=0): read, not present */ // bit0为0,bit1为0,访问的映射页表项不存在,且发生的是读异常 if (!(vma->vm_flags & (VM_READ | VM_EXEC))) { // 对应的vma映射的虚拟内存空间是不可读且不可执行的 cprintf("do_pgfault failed: error code flag = read AND not present, but the addr's vma cannot read or exec\n"); goto failed; } // 校验通过,则说明发生了缺页异常 } /* IF (write an existed addr ) OR * (write an non_existed addr && addr is writable) OR * (read an non_existed addr && addr is readable) * THEN * continue process */ // 构造需要设置的缺页页表项的perm权限 uint32_t perm = PTE_U; if (vma->vm_flags & VM_WRITE) { perm |= PTE_W; } // 构造需要设置的缺页页表项的线性地址(按照PGSIZE向下取整,进行页面对齐) addr = ROUNDDOWN(addr, PGSIZE); ret = -E_NO_MEM; // 用于映射的页表项指针(page table entry, pte) pte_t *ptep=NULL; // try to find a pte, if pte's PT(Page Table) isn't existed, then create a PT. // (notice the 3th parameter '1') // 获取addr线性地址在mm所关联页表中的页表项 // 第三个参数=1 表示如果对应页表项不存在,则需要新创建这个页表项 if ((ptep = get_pte(mm->pgdir, addr, 1)) == NULL) { cprintf("get_pte in do_pgfault failed\n"); goto failed; } // 如果对应页表项的内容每一位都全为0,说明之前并不存在,需要设置对应的数据,进行线性地址与物理地址的映射 if (*ptep == 0) { // if the phy addr isn't exist, then alloc a page & map the phy addr with logical addr // 令pgdir指向的页表中,la线性地址对应的二级页表项与一个新分配的物理页Page进行虚实地址的映射 if (pgdir_alloc_page(mm->pgdir, addr, perm) == NULL) { cprintf("pgdir_alloc_page in do_pgfault failed\n"); goto failed; } } else { // if this pte is a swap entry, then load data from disk to a page with phy addr // and call page_insert to map the phy addr with logical addr // 如果不是全为0,说明可能是之前被交换到了swap磁盘中 if(swap_init_ok) { // 如果开启了swap磁盘虚拟内存交换机制 struct Page *page=NULL; // 将addr线性地址对应的物理页数据从磁盘交换到物理内存中(令Page指针指向交换成功后的物理页) if ((ret = swap_in(mm, addr, &page)) != 0) { // swap_in返回值不为0,表示换入失败 cprintf("swap_in in do_pgfault failed\n"); goto failed; } // 将交换进来的page页与mm->padir页表中对应addr的二级页表项建立映射关系(perm标识这个二级页表的各个权限位) page_insert(mm->pgdir, page, addr, perm); // 当前page是为可交换的,将其加入全局虚拟内存交换管理器的管理 swap_map_swappable(mm, addr, page, 1); page->pra_vaddr = addr; } else { // 如果没有开启swap磁盘虚拟内存交换机制,但是却执行至此,则出现了问题 cprintf("no swap_init_ok but ptep is %x, failed\n",*ptep); goto failed; } } // 返回0代表缺页异常处理成功 ret = 0; failed: return ret; }
pgdir_alloc_page 建立映射虚实关系 :
// pgdir_alloc_page - call alloc_page & page_insert functions to // - allocate a page size memory & setup an addr map // - pa<->la with linear address la and the PDT pgdir // 令pgdir指向的页表中,la线性地址对应的二级页表项与一个新分配的物理页Page进行虚实地址的映射 struct Page * pgdir_alloc_page(pde_t *pgdir, uintptr_t la, uint32_t perm) { // 分配一个新的物理页用于映射la struct Page *page = alloc_page(); if (page != NULL) { // !=null 分配成功 // 建立la对应二级页表项(位于pgdir页表中)与page物理页基址的映射关系 if (page_insert(pgdir, page, la, perm) != 0) { // 映射失败,释放刚才分配的物理页 free_page(page); return NULL; } // 如果启用了swap交换分区功能 if (swap_init_ok){ // 将新映射的这一个page物理页设置为可交换的,并纳入全局swap交换管理器中管理 swap_map_swappable(check_mm_struct, la, page, 0); // 设置这一物理页关联的虚拟内存 page->pra_vaddr=la; // 校验这个新分配出来的物理页page是否引用次数正好为1 assert(page_ref(page) == 1); //cprintf("get No. %d page: pra_vaddr %x, pra_link.prev %x, pra_link_next %x in pgdir_alloc_page\n", (page-pages), page->pra_vaddr,page->pra_page_link.prev, page->pra_page_link.next); } } return page; }
如何在置换时从swap磁盘分区中找到二级页表项对应的物理页数据?
要想在换入时准确的找到二级页表项所映射物理内存页内容在磁盘交换分区中的位置,需要建立某种映射关系或是映射表。在ucore中,没有单独的另外构建一张新的映射表,而是巧妙地重复利用了二级页表项。
在80386CPU中,内存寻址时线性地址对应二级页表项的Present存在位是至关重要的。当P位为1时,代表所映射的物理页存在,访问正常;而P位为0时,代表不存在,则整个二级页表项的其它位都没有意义了。而ucore则利用了这一特性,在进行物理页虚拟内存的置换后,将P位设置为0的同时,还将二级页表项pte的高24位作为在磁盘交换扇区中的偏移索引,并为此单独定义了swap_entry_t这一32位结构表示处于交换区的虚拟内存映射页的状态。
pte在lab3中有了三种不同的状态:
1. 全为0,代表未建立对应物理页的映射
2. P位为1,代表已建立对应物理页的映射
3. P位为0,但高24位不为0。代表所映射的物理页存在,只是被交换到了磁盘交换区中。
swap_entry_t:
/* * * swap_entry_t * -------------------------------------------- * | offset | reserved | 0 | * -------------------------------------------- * 24 bits 7 bits 1 bit * */ typedef pte_t swap_entry_t; //the pte can also be a swap entry
一个物理页面的大小为4KB,而一个ide磁盘扇区的大小为512Byte,比例为8:1。
在ucore lab3中,由于目前只存在一个页表(内核页表),为了简单起见就直接令swap_entry_t中的高24位偏移 * 8 = 对应存储磁盘交换起始扇区号。
从磁盘换入到主存swap_in:
int swap_in(struct mm_struct *mm, uintptr_t addr, struct Page **ptr_result) { // 分配一个新的物理页 struct Page *result = alloc_page(); assert(result!=NULL); // 获得线性地址addr对应的二级页表项指针 pte_t *ptep = get_pte(mm->pgdir, addr, 0); // cprintf("SWAP: load ptep %x swap entry %d to vaddr 0x%08x, page %x, No %d\n", ptep, (*ptep)>>8, addr, result, (result-pages)); int r; // 将磁盘中读入的一整个物理页数据,写入result(此时的ptep二级页表项中存放的是swap_entry_t结构的数据) if ((r = swapfs_read((*ptep), result)) != 0) { assert(r!=0); } cprintf("swap_in: load disk swap entry %d with swap_page in vadr 0x%x\n", (*ptep)>>8, addr); // 令参数ptr_result指向已被换入内存中的result Page结构 *ptr_result=result; return 0; } int swapfs_read(swap_entry_t entry, struct Page *page) { // swap_offset宏右移8位,截取前24位 = swap_entry_t的offset属性 // swap_entry_t的offset * PAGE_NSECT(物理页与磁盘扇区大小比值) = 要读取的起始扇区号 // 从设备号指定的磁盘中,读取自某一扇区起始的N个连续扇区,并将其写入指定起始地址的内存空间中 // SWAP_DEV_NO参数指定设备号,swap_offset(entry) * PAGE_NSECT指定起始扇区号 // page2kva(page)指定所要写入的目的页面虚地址起始空间,PAGE_NSECT指定了需要顺序连续读取的扇区数量 return ide_read_secs(SWAP_DEV_NO, swap_offset(entry) * PAGE_NSECT, page2kva(page), PAGE_NSECT); }
从主存换出到磁盘swap_out:
/** * 参数mm,指定对应的内存管理器 * 参数n,指定需要换出到swap扇区的物理页个数 * 参数in_tick,可以用于发生时钟中断时,定时进行主动的换出操作,腾出更多的物理空闲页 * */ int swap_out(struct mm_struct *mm, int n, int in_tick) { int i; for (i = 0; i != n; ++ i) { uintptr_t v; //struct Page **ptr_page=NULL; struct Page *page; // cprintf("i %d, SWAP: call swap_out_victim\n",i); // 由swap置换管理器,挑选出需要被牺牲的(被置换到swap磁盘扇区)的page,令page指针变量指向其指针 int r = sm->swap_out_victim(mm, &page, in_tick); if (r != 0) { // 挑选失败 cprintf("i %d, swap_out: call swap_out_victim failed\n",i); break; } // 获得挑选出来的物理页的虚拟地址 v=page->pra_vaddr; // 获得page->pra_vaddr线性地址对应的二级页表项 pte_t *ptep = get_pte(mm->pgdir, v, 0); assert((*ptep & PTE_P) != 0); // 将其写入swap磁盘 // page->pra_vaddr/PGSIZE = 虚拟地址对应的二级页表项索引(前20位); // (page->pra_vaddr/PGSIZE) + 1 (+1为了在页表项中区别 0 和 swap 分区的映射) // ((page->pra_vaddr/PGSIZE) + 1) << 8,为了构成swap_entry_t的高24位 // 举个例子: // 假设page->pra_vaddr = 0x0000100,则page->pra_vaddr/PGSIZE = 0x00000001 // page->pra_vaddr/PGSIZE + 1 = 0x00000002 // 对应的swap_entry_t = 0x00000002 << 8 = 0x00000200,高24位为0x000002 if (swapfs_write( (page->pra_vaddr/PGSIZE+1)<<8, page) != 0) { cprintf("SWAP: failed to save\n"); // 当前物理页写入swap,交换失败。重新令其加入swap管理器中 sm->map_swappable(mm, v, page, 0); continue; } else { // 交换成功 cprintf("swap_out: i %d, store page in vaddr 0x%x to disk swap entry %d\n", i, v, page->pra_vaddr/PGSIZE+1); // 设置ptep二级页表项的值 *ptep = (page->pra_vaddr/PGSIZE+1)<<8; // 释放、归还page物理页 free_page(page); } // 由于对应二级页表项出现了变化,刷新TLB快表 tlb_invalidate(mm->pgdir, v); } return i; } int swapfs_write(swap_entry_t entry, struct Page *page) { // swap_offset宏右移8位,截取前24位 = swap_entry_t的offset属性 // swap_entry_t的offset * PAGE_NSECT(物理页与磁盘扇区大小比值) = 要写入的起始扇区号 // 从设备号指定的磁盘中,从指定起始地址的内存空间开始,将数据写入自某一扇区起始的N个连续扇区内 // SWAP_DEV_NO参数指定设备号,swap_offset(entry) * PAGE_NSECT指定起始扇区号 // page2kva(page)指定所要读入的源数据页面虚地址起始空间,PAGE_NSECT指定了需要顺序连续写入的扇区数量 return ide_write_secs(SWAP_DEV_NO, swap_offset(entry) * PAGE_NSECT, page2kva(page), PAGE_NSECT); }
2.3 swap_manager 虚拟内存页面置换管理框架
虽然虚拟内存机制在逻辑上增大了应用程序可用的内存,但由于磁盘I/O速度相较于主存有巨大的差距,因此一个好的虚拟内存置换算法是至关重要的。为此,计算机科学家不断的提出各种不同的置换算法,以获得更好的虚拟内存访问效率。
和lab2中构建一个管理物理页面的接口集合框架,将调用接口与具体实现解耦一样。在lab3中也抽象出了一个用于管理虚拟内存页面置换的框架swap_manager,并提供了一个默认的实现fifo_swap_manager。从名称上可以知道,fifo_swap_manager采用的是先进先出这一效率不高,但简单易懂的调度算法。
通过构造不同的swap_manager实现,也可以用来完成挑战练习要求的效率更高,但更复杂的时钟页置换算法。
swap_manager:
struct swap_manager { const char *name; /* Global initialization for the swap manager */ // 初始化全局虚拟内存交换管理器 int (*init) (void); /* Initialize the priv data inside mm_struct */ // 初始化设置所关联的全局内存管理器 int (*init_mm) (struct mm_struct *mm); /* Called when tick interrupt occured */ // 当时钟中断时被调用,可用于主动的swap交换策略 int (*tick_event) (struct mm_struct *mm); /* Called when map a swappable page into the mm_struct */ // 当映射一个可交换Page物理页加入mm_struct时被调用 int (*map_swappable) (struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in); /* When a page is marked as shared, this routine is called to * delete the addr entry from the swap manager */ // 当一个页面被标记为共享页面,该函数例程会被调用。 // 用于将addr对应的虚拟页,从swap_manager中移除,阻止其被调度置换到磁盘中 int (*set_unswappable) (struct mm_struct *mm, uintptr_t addr); /* Try to swap out a page, return then victim */ // 当试图换出一个物理页时,返回被选中的页面(被牺牲的页面) int (*swap_out_victim) (struct mm_struct *mm, struct Page **ptr_page, int in_tick); /* check the page relpacement algorithm */ int (*check_swap)(void); };
swap_fifo.c主要逻辑部分:
list_entry_t pra_list_head; /* * (2) _fifo_init_mm: init pra_list_head and let mm->sm_priv point to the addr of pra_list_head. * Now, From the memory control struct mm_struct, we can access FIFO PRA */ static int _fifo_init_mm(struct mm_struct *mm) { // 初始化先进先出链表队列 list_init(&pra_list_head); mm->sm_priv = &pra_list_head; //cprintf(" mm->sm_priv %x in fifo_init_mm\n",mm->sm_priv); return 0; } /* * (3)_fifo_map_swappable: According FIFO PRA, we should link the most recent arrival page at the back of pra_list_head qeueue */ static int _fifo_map_swappable(struct mm_struct *mm, uintptr_t addr, struct Page *page, int swap_in) { // 获取到mm_struct关联的先进先出链表队列 list_entry_t *head=(list_entry_t*) mm->sm_priv; // 获取参数page结构对应的swap链表节点 list_entry_t *entry=&(page->pra_page_link); assert(entry != NULL && head != NULL); //record the page access situlation /*LAB3 EXERCISE 2: YOUR CODE*/ //(1)link the most recent arrival page at the back of the pra_list_head qeueue. // 将其加入队列的头部(先进先出,最新的page页被挂载在最头上) list_add(head, entry); return 0; } /* * (4)_fifo_swap_out_victim: According FIFO PRA, we should unlink the earliest arrival page in front of pra_list_head qeueue, * then assign the value of *ptr_page to the addr of this page. */ static int _fifo_swap_out_victim(struct mm_struct *mm, struct Page ** ptr_page, int in_tick) { // 获取到mm_struct关联的先进先出链表队列 list_entry_t *head=(list_entry_t*) mm->sm_priv; assert(head != NULL); assert(in_tick==0); /* Select the victim */ /*LAB3 EXERCISE 2: YOUR CODE*/ //(1) unlink the earliest arrival page in front of pra_list_head qeueue //(2) assign the value of *ptr_page to the addr of this page /* Select the tail */ // 找到头节点的前一个(双向循环链表 head的前一个节点=队列的最尾部节点) list_entry_t *le = head->prev; assert(head!=le); // 获得尾节点对应的page结构 struct Page *p = le2page(le, pra_page_link); // 将le节点从先进先出链表队列中删除 list_del(le); assert(p !=NULL); // 令ptr_page指向被挑选出来的page *ptr_page = p; return 0; } struct swap_manager swap_manager_fifo = { .name = "fifo swap manager", .init = &_fifo_init, .init_mm = &_fifo_init_mm, .tick_event = &_fifo_tick_event, .map_swappable = &_fifo_map_swappable, .set_unswappable = &_fifo_set_unswappable, .swap_out_victim = &_fifo_swap_out_victim, .check_swap = &_fifo_check_swap, };
3.总结
ucore通过lab2、lab3两个连续的实验,完成了对计算机内存的抽象与管理,为后续的用户级的多进程/线程的实现打下了基础。lab3对于已经理解了lab1、lab2中各种硬件交互以及C中晦涩巧妙的宏实现的人来说难度并不算大,整体的学习曲线变得*缓了。
由于前几个实验都是与操作系统内核紧密相关的,还没有涉及到与用户程序的交互,显得有些单调、枯燥,就连所实现的虚拟内存管理的相关功能都是通过一段精心设计的模拟内存访问过程的代码来校验其正确性的。但很快ucore就会在后续的实验中引入多进程/线程、用户态进程以及进程/线程同步等更加贴**常应用开发时接触到的系统功能,对ucore的学习也会变得更加有趣。
通过对ucore操作系统的学习,使我们得以打开操作系统这个黑盒子一窥究竟,更好的理解上层应用程序运行时背后发生的事情,从能够写出更高效、健壮的应用程序。
这篇博客的完整代码注释在我的github上:https://github.com/1399852153/ucore_os_lab (fork自官方仓库)中的lab3_answer。
希望我的博客能帮助到对操作系统、ucore os感兴趣的人。存在许多不足之处,还请多多指教。

