
8086汇编语言学习(六) 8086处理结构化数据(模拟高级语言结构体、数组)
一、8086汇编定义数据
要处理结构化数据,必须先定义数据。8086汇编作为一门编程语言,定义数据的方式比起复杂的高级语言要简单不少。
汇编语言贴近机器底层,所处理的数据逻辑上都可以视为二进制数据,按照对不同大小内存单元的处理,分为三种:db、dw、dd。
1.db
db 即define byte,定义一个字节变量。例如 db 1h,代表着db指令后的值占用一个字节的内存空间 1h=>01h。
特别的,使用db可以比较简单的定义字符串数据,例如db "ABC",代表着定义A、B、C三个连续的字符。
2.dw
db 即define word,定义一个字变量。例如 dw 1h,代表着dw指令后的值占用一个字/两个字节的内存空间 1h=>0001h。
3.dd
dd 即define doubleword,定义一个双字变量。例如 dd 1h,代表着dw指令后的值占用两个字/四个字节的内存空间 1h=>0000 0001h。
在连续定义数据时,可以通过逗号进行缩写。例如 db 1h,2h,3h等价与db 1h;db 2h;db 3h。
同时上述三种方式都可以与dup关键字(duplicate)使用。例如,定义3个值为1h的字形数据,可以写为dw 3 dup(1h),其等价于dw 1h,1h,1h。在定义复数个相同的数据时,可以简化程序,增强可读性。
db、dw、dd、dup都属于8086汇编的伪指令,由汇编器在编译时进行处理,并没有对应的机器指令。
二、8086汇编处理结构化数据
之前介绍了8086各种不同方式的内存寻址方式,下面介绍8086如何利用这些多样的寻址方式来处理结构化的数据。
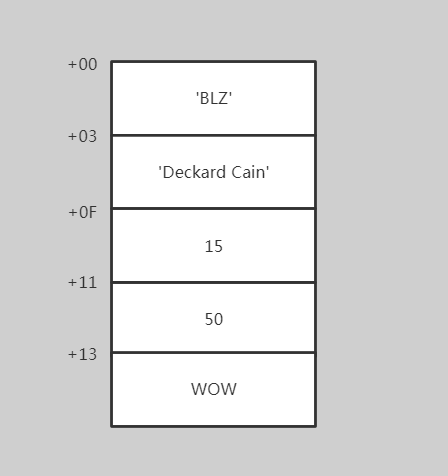
举一个简单的例子,假设存在一个结构化的数据(公司),拥有五个属性。
公司属性:
公司名称: BLZ
总裁名称: Deckard Cain
公司排名: 15
年收入(亿元): 50
产品: WOW
需求是,在内存中定义该数据并且对其中的部分属性进行修改,将公司排名修改为10,年收入修改为80,产品名称修改为OWO。
整理思路后的伪代码:
1. 先按照顺序在内存中存放对应的数据结构
2. 找到公司排名所在的内存地址,将其修改(偏移地址 0Fh)
3. 找到年收入所在的内存地址,将其修改(偏移地址 11h)
4. 找到产品所在的内存地址(14h),并将产品名称字符串中的字符逐一修改
令P=0h
修改13h+P处的字符
P=P+1h
修改13h+P处的字符
P=P+1h
修改13h+P处的字符
根据上述伪代码,写出对应汇编程序:
assume cs:codesg,ds:data data segment db "BLZ","Deckard Cain"; 定义公司名称、总裁名称 dw 15h,50h; 定义排名、年收入 db "WOW"; 定义产品名称 data ends codesg segment start: mov ax,data; mov ds,ax; 设置段基址为data mov bx,0h; 设置数据在段中的起始位置为0h mov word ptr [bx+0Fh],10h; 修改排名所在的字数据为10 mov word ptr [bx+11h],80h; 修改收入所在的子数据为80 mov si,0; 引入si变量,遍历产品名称 mov byte ptr [bx+13h+si],'O'; 第一个字符设置为0 inc si; si自增1,bx+idata+si 指向下一个字符 mov byte ptr [bx+13h+si],'M'; 第二个字符设置为M inc si; si自增1,bx+idata+si 指向下一个字符 mov byte ptr [bx+13h+si],'O'; 第三个字符设置为0 mov ax,4c00H; int 21H; codesg ends end start
如果用C这种较高级的语言来实现,则简单很多。
用C语言的结构体表示为:
struct company{ char cname[3]; char hname[12]; int rank; int income; char product[3]; }
用C语言实现需求:
{ struct company blz={"BLZ","Deckard Cain",15,50,"WOW"} // 定义数据 int i; blz.rank=10; // 修改排名 blz.income=80; // 修改收入 i=0; blz.product[i] = 'O'; // 修改产品名称 i++; blz.product[i] = 'M'; i++; blz.product[i] = 'O'; }
通过对比,可以清楚看到,C语言的实现比起汇编要来的轻松和简洁许多。8086汇编提供了指定偏移地址的语法糖,使得寻址时的程序更像高级语言,可读性更高。
将上述的汇编程序以类似C语言的风格进行部分重构:
assume cs:codesg,ds:data data segment db "BLZ","Deckard Cain"; dw 15h,50h; db "WOW"; data ends codesg segment start: mov ax,data; mov ds,ax; 设置段基址为data mov bx,0h; 设置数据在段中的起始位置为0h mov word ptr [bx].0fh,10h; 修改排名所在的字数据为10 mov word ptr [bx].11h,80h; 修改收入所在的子数据为80 mov si,0; 引入si变量,遍历产品字段 mov byte ptr [bx].13h[si],'O'; 第一个字符设置为0 inc si; si自增1,bx+idata+si 指向下一个字符 mov byte ptr [bx].13h[si],'M'; 第二个字符设置为M inc si; si自增1,bx+idata+si 指向下一个字符 mov byte ptr [bx].13h[si],'O'; 第三个字符设置为0 mov ax,4c00H; int 21H; codesg ends end start
主要是对数据内存寻址的方式进行了重构。这里的ds:[bx]相当于C程序中的变量blz,[bx].0fh相当于blz的属性rank,而[bx].11h则相当于blz的属性income。
[bx].14h相当于blz的属性product,[bx].14h[si]相当于product字符数组中的某一字符项。
使用类似高级语言语法的寻址方式优化过后的汇编程序,比标准化的寻址方式更易理解,减少了程序出错的可能性。

