
java8 Stream的实现原理 (从零开始实现一个stream流)
1.从零开始实现stream流
1.1 java8 stream介绍
java8新增了stream流的特性,能够让用户以函数式的方式、更为简单的操纵集合等数据结构,并实现了用户无感知的并行计算。
1.2 从零开始实现一个stream流
相信很多人在使用过java8的streamAPI接口之后,都会对其实现原理感到好奇,但往往在看到jdk的stream源码后却被其复杂的抽象、封装给弄糊涂了,而无法很好的理解其背后的原理。究其原因,是因为jdk的stream源码是高度工程化的代码,工程化的代码为了效率和满足各式各样的需求,会将代码实现的极其复杂,不易理解。
在这里,我们将抛开jdk的实现思路,从零开始实现一个stream流。
我们的stream流同样拥有惰性求值,函数式编程接口等特性,并兼容jdk的Collection等数据结构(但不支持并行计算 orz)。
相信在亲手实现一个stream流的框架之后,大家能更好的理解流计算的原理。
2.stream的优点
在探讨探究stream的实现原理和动手实现之前,我们先要体会stream流计算的独特之处。
举个例子: 有一个List<Person>列表,我们需要获得年龄为70岁的前10个Person的姓名。
过程式的解决方案:
稍加思考,我们很快就写出了一个过程式的解决方案(伪代码):
List<Person> personList = fromDB(); // 获得List<Person> int limit = 10; // 限制条件 List<String> nameList = new ArrayList(); // 收集的姓名集合 for(Person personItem : personList){ if(personItem.age == 70){ // 满足条件 nameList.add(personItem.name); // 加入姓名集合 if(nameList.size() >= 10){ // 判断是否超过限制 break; } } } return nameList;
函数式stream解决方案:
下面我们给出一种基于stream流的解决方案(伪代码):
List<Person> personList = fromDB(); // 获得List<Person> List<String> nameList = personList.stream() .filter(item->item.age == 70) // 过滤条件 .limit(10) // limit限制条件 .map(item->item.name) // 获得姓名 .collect(Collectors.toList()); // 转化为list return nameList;
两种方案的不同之处:
从函数式的角度上看,过程式的代码实现将收集元素、循环迭代、各种逻辑判断耦合在一起,暴露了太多细节。当未来需求变动和变得更加复杂的情况下,过程式的代码将变得难以理解和维护(需要控制台打印出 年龄为70岁的前10个Person中,姓王的Person的名称)。
函数式的解决方案解开了代码细节和业务逻辑的耦合,类似于sql语句,表达的是"要做什么"而不是"如何去做",使程序员可以更加专注于业务逻辑,写出易于理解和维护的代码。
List<Person> personList = fromDB(); // 获得List<Person> personList.stream() .filter(item->item.age == 70) // 过滤条件 .limit(10) // limit限制条件 .filter(item->item.name.startWith("王")) // 过滤条件 .map(item->item.name) // 获得姓名 .forEach(System.out::println);
3.stream API接口介绍
stream API的接口是函数式的,尽管java 8也引入了lambda表达式,但java实质上依然是由接口-匿名内部类来实现函数传参的,所以需要事先定义一系列的函数式接口。
Function: 类似于 y = F(x)
@FunctionalInterface public interface Function<R,T> { /** * 函数式接口 * 类似于 y = F(x) * */ R apply(T t); }
BiFunction: 类似于 z = F(x,y)
@FunctionalInterface public interface BiFunction<R, T, U> { /** * 函数式接口 * 类似于 z = F(x,y) * */ R apply(T t, U u); }
ForEach: 遍历处理
@FunctionalInterface public interface ForEach <T>{ /** * 迭代器遍历 * @param item 被迭代的每一项 * */ void apply(T item); }
Comparator: 比较器
@FunctionalInterface public interface Comparator<T> { /** * 比较方法逻辑 * @param o1 参数1 * @param o2 参数2 * @return 返回值大于0 ---> (o1 > o2) * 返回值等于0 ---> (o1 = o2) * 返回值小于0 ---> (o1 < o2) */ int compare(T o1, T o2); }
Predicate: 条件判断
@FunctionalInterface public interface Predicate <T>{ /** * 函数式接口 * @param item 迭代的每一项 * @return true 满足条件 * false 不满足条件 * */ boolean satisfy(T item); }
Supplier:提供初始值
@FunctionalInterface public interface Supplier<T> { /** * 提供初始值 * @return 初始化的值 * */ T get(); }
EvalFunction:stream求值函数
@FunctionalInterface public interface EvalFunction<T> { /** * stream流的强制求值方法 * @return 求值返回一个新的stream * */ MyStream<T> apply(); }
stream API接口:
/** * stream流的API接口 */ public interface Stream<T> { /** * 映射 lazy 惰性求值 * @param mapper 转换逻辑 T->R * @return 一个新的流 * */ <R> MyStream<R> map(Function<R,T> mapper); /** * 扁平化 映射 lazy 惰性求值 * @param mapper 转换逻辑 T->MyStream<R> * @return 一个新的流(扁平化之后) * */ <R> MyStream<R> flatMap(Function<? extends MyStream<R>, T> mapper); /** * 过滤 lazy 惰性求值 * @param predicate 谓词判断 * @return 一个新的流,其中元素是满足predicate条件的 * */ MyStream<T> filter(Predicate<T> predicate); /** * 截断 lazy 惰性求值 * @param n 截断流,只获取部分 * @return 一个新的流,其中的元素不超过 n * */ MyStream<T> limit(int n); /** * 去重操作 lazy 惰性求值 * @return 一个新的流,其中的元素不重复(!equals) * */ MyStream<T> distinct(); /** * 窥视 lazy 惰性求值 * @return 同一个流,peek不改变流的任何行为 * */ MyStream<T> peek(ForEach<T> consumer); /** * 遍历 eval 强制求值 * @param consumer 遍历逻辑 * */ void forEach(ForEach<T> consumer); /** * 浓缩 eval 强制求值 * @param initVal 浓缩时的初始值 * @param accumulator 浓缩时的 累加逻辑 * @return 浓缩之后的结果 * */ <R> R reduce(R initVal, BiFunction<R, R, T> accumulator); /** * 收集 eval 强制求值 * @param collector 传入所需的函数组合子,生成高阶函数 * @return 收集之后的结果 * */ <R, A> R collect(Collector<T,A,R> collector); /** * 最大值 eval 强制求值 * @param comparator 大小比较逻辑 * @return 流中的最大值 * */ T max(Comparator<T> comparator); /** * 最小值 eval 强制求值 * @param comparator 大小比较逻辑 * @return 流中的最小值 * */ T min(Comparator<T> comparator); /** * 计数 eval 强制求值 * @return 当前流的个数 * */ int count(); /** * 流中是否存在满足predicate的项 * @return true 存在 匹配项 * false 不存在 匹配项 * */ boolean anyMatch(Predicate<? super T> predicate); /** * 流中的元素是否全部满足predicate * @return true 全部满足 * false 不全部满足 * */ boolean allMatch(Predicate<? super T> predicate); /** * 返回空的 stream * @return 空stream * */ static <T> MyStream<T> makeEmptyStream(){ // isEnd = true return new MyStream.Builder<T>().isEnd(true).build(); } }
4.MyStream 实现细节
简单介绍了API接口定义之后,我们开始深入探讨流的内部实现。
流由两个重要的部分所组成,"当前数据项(head)"和"下一数据项的求值函数(nextItemEvalProcess)"。
其中,nextItemEvalProcess是流能够实现"惰性求值"的关键。
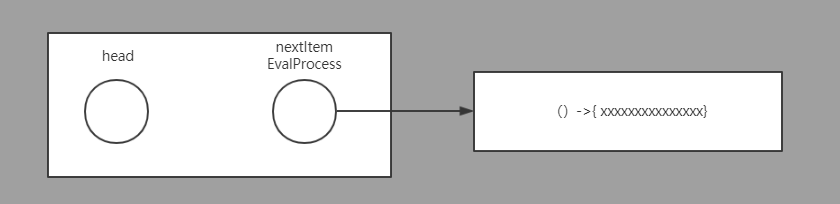
流的基本属性:
public class MyStream<T> implements Stream<T> { /** * 流的头部 * */ private T head; /** * 流的下一项求值函数 * */ private NextItemEvalProcess nextItemEvalProcess; /** * 是否是流的结尾 * */ private boolean isEnd; public static class Builder<T>{ private MyStream<T> target; public Builder() { this.target = new MyStream<>(); } public Builder<T> head(T head){ target.head = head; return this; } Builder<T> isEnd(boolean isEnd){ target.isEnd = isEnd; return this; } public Builder<T> nextItemEvalProcess(NextItemEvalProcess nextItemEvalProcess){ target.nextItemEvalProcess = nextItemEvalProcess; return this; } public MyStream<T> build(){ return target; } } /** * 当前流强制求值 * @return 求值之后返回一个新的流 * */ private MyStream<T> eval(){ return this.nextItemEvalProcess.eval(); } /** * 当前流 为空 * */ private boolean isEmptyStream(){ return this.isEnd; } }
/** * 下一个元素求值过程 */ public class NextItemEvalProcess { /** * 求值方法 * */ private EvalFunction evalFunction; public NextItemEvalProcess(EvalFunction evalFunction) { this.evalFunction = evalFunction; } MyStream eval(){ return evalFunction.apply(); } }
4.1 stream流在使用过程中的三个阶段
1. 生成并构造一个流 (List.stream() 等方法)
2. 在流的处理过程中添加、绑定惰性求值流程 (map、filter、limit 等方法)
3. 对流使用强制求值函数,生成最终结果 (max、collect、forEach等方法)
4.2 生成并构造一个流
流在生成时是"纯净"的,其最初的NextItemEvalProcess求值之后就是指向自己的下一个元素。
我们以一个Integer整数流的生成为例。IntegerStreamGenerator.getIntegerStream(1,10) 会返回一个流结构,其逻辑上等价于一个从1到10的整数流。但实质是一个惰性求值的stream对象,这里称其为IntStream,其NextItemEvalProcess是一个闭包,方法体是一个递归结构的求值函数,其中下界参数low = low + 1。
当IntStream第一次被求值时,流开始初始化,isStart = false。当初始化完成之后,每一次求值,都会生成一个新的流对象,其中head(low) = low + 1。当low > high时,流被终止,返回空的流对象。
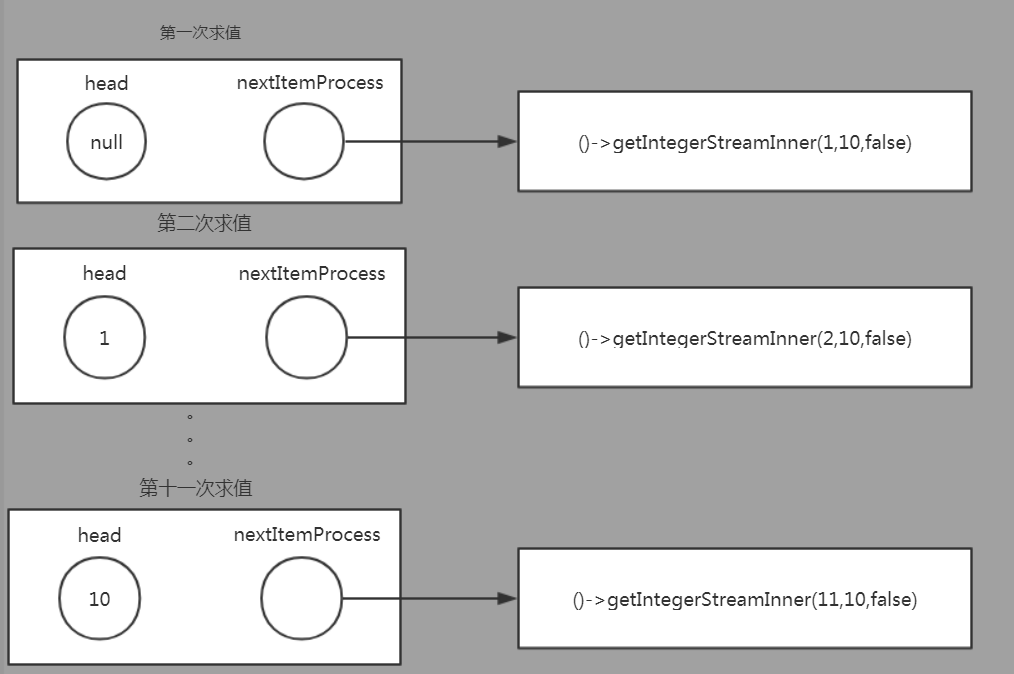
/** * 整数流生成器 */ public class IntegerStreamGenerator { /** * 获得一个有限的整数流 介于[low-high]之间 * @param low 下界 * @param high 上界 * */ public static MyStream<Integer> getIntegerStream(int low, int high){ return getIntegerStreamInner(low,high,true); } /** * 递归函数。配合getIntegerStream(int low,int high) * */ private static MyStream<Integer> getIntegerStreamInner(int low, int high, boolean isStart){ if(low > high){ // 到达边界条件,返回空的流 return Stream.makeEmptyStream(); }
if(isStart){ return new MyStream.Builder<Integer>() .process(new NextItemEvalProcess(()->getIntegerStreamInner(low,high,false))) .build(); }else{ return new MyStream.Builder<Integer>() // 当前元素 low .head(low) // 下一个元素 low+1 .process(new NextItemEvalProcess(()->getIntegerStreamInner(low+1,high,false))) .build(); } } }
可以看到,生成一个流的关键在于确定如何求值下一项元素。对于整数流来说,low = low + 1就是其下一项的求值过程。
那么对于我们非常关心的jdk集合容器,又该如何生成对应的流呢?
答案是Iterator迭代器,jdk的集合容器都实现了Iterator迭代器接口,通过迭代器我们可以轻易的取得容器的下一项元素,而不用关心容器内部实现细节。换句话说,只要实现过迭代器接口,就可以自然的转化为stream流,从而获得流计算的所有能力。
/** * 集合流生成器 */ public class CollectionStreamGenerator { /** * 将一个List转化为stream流 * */ public static <T> MyStream<T> getListStream(List<T> list){ return getListStream(list.iterator(),true); } /** * 递归函数 * @param iterator list 集合的迭代器 * @param isStart 是否是第一次迭代 * */ private static <T> MyStream<T> getListStream(Iterator<T> iterator, boolean isStart){ if(!iterator.hasNext()){ // 不存在迭代的下一个元素,返回空的流 return Stream.makeEmptyStream(); } if(isStart){ // 初始化,只需要设置 求值过程 return new MyStream.Builder<T>() .nextItemEvalProcess(new NextItemEvalProcess(()-> getListStream(iterator,false))) .build(); }else{ // 非初始化,设置head和接下来的求值过程 return new MyStream.Builder<T>() .head(iterator.next()) .nextItemEvalProcess(new NextItemEvalProcess(()-> getListStream(iterator,false))) .build(); } } }
思考一个小问题,如何生成一个无穷的整数流?
4.3 在流的处理过程中添加、绑定惰性求值流程
我们以map接口举例说明。API的map接口是一个惰性求值接口,在流执行了map方法后(stream.map()),不会进行任何的求值运算。map在执行时,会生成一个新的求值过程NextItemEvalProcess,新的过程将之前流的求值过程给"包裹"起来了,仅仅是在"流的生成"到"流的最终求值"之间增加了一道处理工序,最终返回了一个新的stream流对象。
API.map所依赖的内部静态map方法是一个惰性求值方法,其每次调用"只会"将当前流的head部分进行map映射操作,并且生成一个新的流。新生成流的NextItemEvalProcess和之前逻辑基本保持一致(递归),唯一的区别是,第二个参数传入的stream在调用方法之前会被强制求值(eval)后再传入。
@Override public <R> MyStream<R> map(Function<R, T> mapper) { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()->{ MyStream myStream = lastNextItemEvalProcess.eval(); return map(mapper, myStream); } ); // 求值链条 加入一个新的process map return new MyStream.Builder<R>() .nextItemEvalProcess(this.nextItemEvalProcess) .build(); } /** * 递归函数 配合API.map * */ private static <R,T> MyStream<R> map(Function<R, T> mapper, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return Stream.makeEmptyStream(); } R head = mapper.apply(myStream.head); return new MyStream.Builder<R>() .head(head) .nextItemEvalProcess(new NextItemEvalProcess(()->map(mapper, myStream.eval()))) .build(); }
惰性求值接口的实现大同小异,大家需要体会一下闭包、递归、惰性求值等概念,限于篇幅就不一一展开啦。
flatMap:


@Override public <R> MyStream<R> flatMap(Function<? extends MyStream<R>,T> mapper) { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()->{ MyStream myStream = lastNextItemEvalProcess.eval(); return flatMap(mapper, Stream.makeEmptyStream(), myStream); } ); // 求值链条 加入一个新的process map return new MyStream.Builder<R>() .nextItemEvalProcess(this.nextItemEvalProcess) .build(); } /** * 递归函数 配合API.flatMap * */ private static <R,T> MyStream<R> flatMap(Function<? extends MyStream<R>,T> mapper, MyStream<R> headMyStream, MyStream<T> myStream){ if(headMyStream.isEmptyStream()){ if(myStream.isEmptyStream()){ return Stream.makeEmptyStream(); }else{ T outerHead = myStream.head; MyStream<R> newHeadMyStream = mapper.apply(outerHead); return flatMap(mapper, newHeadMyStream.eval(), myStream.eval()); } }else{ return new MyStream.Builder<R>() .head(headMyStream.head) .nextItemEvalProcess(new NextItemEvalProcess(()-> flatMap(mapper, headMyStream.eval(), myStream))) .build(); } }
filter:
@Override public MyStream<T> filter(Predicate<T> predicate) { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()-> { MyStream myStream = lastNextItemEvalProcess.eval(); return filter(predicate, myStream); } ); // 求值链条 加入一个新的process filter return this; } /** * 递归函数 配合API.filter * */ private static <T> MyStream<T> filter(Predicate<T> predicate, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return Stream.makeEmptyStream(); } if(predicate.satisfy(myStream.head)){ return new Builder<T>() .head(myStream.head) .nextItemEvalProcess(new NextItemEvalProcess(()->filter(predicate, myStream.eval()))) .build(); }else{ return filter(predicate, myStream.eval()); } }
limit:
@Override public MyStream<T> limit(int n) { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()-> { MyStream myStream = lastNextItemEvalProcess.eval(); return limit(n, myStream); } ); // 求值链条 加入一个新的process limit return this; } /** * 递归函数 配合API.limit * */ private static <T> MyStream<T> limit(int num, MyStream<T> myStream){ if(num == 0 || myStream.isEmptyStream()){ return Stream.makeEmptyStream(); } return new MyStream.Builder<T>() .head(myStream.head) .nextItemEvalProcess(new NextItemEvalProcess(()->limit(num-1, myStream.eval()))) .build(); }
distinct:
@Override public MyStream<T> distinct() { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()-> { MyStream myStream = lastNextItemEvalProcess.eval(); return distinct(new HashSet<>(), myStream); } ); // 求值链条 加入一个新的process limit return this; } /** * 递归函数 配合API.distinct * */ private static <T> MyStream<T> distinct(Set<T> distinctSet,MyStream<T> myStream){ if(myStream.isEmptyStream()){ return Stream.makeEmptyStream(); } if(!distinctSet.contains(myStream.head)){ // 加入集合 distinctSet.add(myStream.head); return new Builder<T>() .head(myStream.head) .nextItemEvalProcess(new NextItemEvalProcess(()->distinct(distinctSet, myStream.eval()))) .build(); }else{ return distinct(distinctSet, myStream.eval()); } }
peek:
@Override public MyStream<T> peek(ForEach<T> consumer) { NextItemEvalProcess lastNextItemEvalProcess = this.nextItemEvalProcess; this.nextItemEvalProcess = new NextItemEvalProcess( ()-> { MyStream myStream = lastNextItemEvalProcess.eval(); return peek(consumer,myStream); } ); // 求值链条 加入一个新的process peek return this; } /** * 递归函数 配合API.peek * */ private static <T> MyStream<T> peek(ForEach<T> consumer,MyStream<T> myStream){ if(myStream.isEmptyStream()){ return Stream.makeEmptyStream(); } consumer.apply(myStream.head); return new MyStream.Builder<T>() .head(myStream.head) .nextItemEvalProcess(new NextItemEvalProcess(()->peek(consumer, myStream.eval()))) .build(); }
4.4 对流使用强制求值函数,生成最终结果
我们以forEach方法举例说明。强制求值方法forEach会不断的对当前stream进行求值并让consumer接收处理,直到当前流成为空流。
有两种可能的情况会导致递归传入的流参数成为空流(empty-stream):
1. 最初生成流的求值过程返回了空流(整数流,low > high 时,返回空流 )
2. limit之类的短路操作,会提前终止流的求值返回空流(n == 0 时,返回空流)
@Override public void forEach(ForEach<T> consumer) { // 终结操作 直接开始求值 forEach(consumer,this.eval()); } /** * 递归函数 配合API.forEach * */ private static <T> void forEach(ForEach<T> consumer, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return; } consumer.apply(myStream.head); forEach(consumer, myStream.eval()); }
强制求值的接口的实现也都大同小异,限于篇幅就不一一展开啦。
reduce:
/** * 递归函数 配合API.reduce * */ private static <R,T> R reduce(R initVal, BiFunction<R,R,T> accumulator, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return initVal; } T head = myStream.head; R result = reduce(initVal,accumulator, myStream.eval()); return accumulator.apply(result,head); } /** * 递归函数 配合API.reduce * */ private static <R,T> R reduce(R initVal, BiFunction<R,R,T> accumulator, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return initVal; } T head = myStream.head; R result = reduce(initVal,accumulator, myStream.eval()); return accumulator.apply(result,head); }
max:
@Override public T max(Comparator<T> comparator) { // 终结操作 直接开始求值 MyStream<T> eval = this.eval(); if(eval.isEmptyStream()){ return null; }else{ return max(comparator,eval,eval.head); } } /** * 递归函数 配合API.max * */ private static <T> T max(Comparator<T> comparator, MyStream<T> myStream, T max){ if(myStream.isEnd){ return max; } T head = myStream.head; // head 和 max 进行比较 if(comparator.compare(head,max) > 0){ // head 较大 作为新的max传入 return max(comparator, myStream.eval(),head); }else{ // max 较大 不变 return max(comparator, myStream.eval(),max); } }
min:
@Override public T min(Comparator<T> comparator) { // 终结操作 直接开始求值 MyStream<T> eval = this.eval(); if(eval.isEmptyStream()){ return null; }else{ return min(comparator,eval,eval.head); } } /** * 递归函数 配合API.min * */ private static <T> T min(Comparator<T> comparator, MyStream<T> myStream, T min){ if(myStream.isEnd){ return min; } T head = myStream.head; // head 和 min 进行比较 if(comparator.compare(head,min) < 0){ // head 较小 作为新的min传入 return min(comparator, myStream.eval(),head); }else{ // min 较小 不变 return min(comparator, myStream.eval(),min); } }
count:
@Override public int count() { // 终结操作 直接开始求值 return count(this.eval(),0); } /** * 递归函数 配合API.count * */ private static <T> int count(MyStream<T> myStream, int count){ if(myStream.isEmptyStream()){ return count; } // count+1 进行递归 return count(myStream.eval(),count+1); }
anyMatch:
@Override public boolean anyMatch(Predicate<? super T> predicate) { // 终结操作 直接开始求值 return anyMatch(predicate,this.eval()); } /** * 递归函数 配合API.anyMatch * */ private static <T> boolean anyMatch(Predicate<? super T> predicate,MyStream<T> myStream){ if(myStream.isEmptyStream()){ // 截止末尾,不存在任何匹配项 return false; } // 谓词判断 if(predicate.satisfy(myStream.head)){ // 匹配 存在匹配项 返回true return true; }else{ // 不匹配,继续检查,直到存在匹配项 return anyMatch(predicate,myStream.eval()); } }
allMatch:
@Override public boolean allMatch(Predicate<? super T> predicate) { // 终结操作 直接开始求值 return allMatch(predicate,this.eval()); } /** * 递归函数 配合API.anyMatch * */ private static <T> boolean allMatch(Predicate<? super T> predicate,MyStream<T> myStream){ if(myStream.isEmptyStream()){ // 全部匹配 return true; } // 谓词判断 if(predicate.satisfy(myStream.head)){ // 当前项匹配,继续检查 return allMatch(predicate,myStream.eval()); }else{ // 存在不匹配的项,返回false return false; } }
4.5 collect方法
collect方法是强制求值方法中,最复杂也最强大的接口,其作用是将流中的元素收集(collect)起来,并转化成特定的数据结构。
从函数式编程的角度来看,collect方法是一个高阶函数,其接受三个函数作为参数(supplier,accumulator,finisher),最终生成一个更加强大的函数。在java中,三个函数参数以Collector实现对象的形式呈现。
supplier 方法:用于提供收集collect的初始值。
accumulator 方法:用于指定收集过程中,初始值和流中个体元素聚合的逻辑。
finnisher 方法:用于指定在收集完成之后的收尾转化操作(例如:StringBuilder.toString() ---> String)。
collect接口实现:
@Override public <R, A> R collect(Collector<T, A, R> collector) { // 终结操作 直接开始求值 A result = collect(collector,this.eval()); // 通过finish方法进行收尾 return collector.finisher().apply(result); } /** * 递归函数 配合API.collect * */ private static <R, A, T> A collect(Collector<T, A, R> collector, MyStream<T> myStream){ if(myStream.isEmptyStream()){ return collector.supplier().get(); } T head = myStream.head; A tail = collect(collector, myStream.eval()); return collector.accumulator().apply(tail,head); }
collector接口:
/** * collect接口 收集器 * 通过传入组合子,生成高阶过程 */ public interface Collector<T, A, R> { /** * 收集时,提供初始化的值 * */ Supplier<A> supplier(); /** * A = A + T * 累加器,收集时的累加过程 * */ BiFunction<A, A, T> accumulator(); /** * 收集完成之后的收尾操作 * */ Function<A, R> finisher(); }
了解jdk源码的读者可能会注意到,jdk的stream实现中collector接口多了一个combiner接口,combiner接口用于指定并行计算之后的结果集合并的逻辑,由于我们的实现不支持并行计算,因此也不需要添加combiner接口了。
同时,jdk还提供了一个Collectors工具类,很好的满足了平时常见的需求(Collector.toList()、Collctor.groupingBy())等等。但特殊时刻还是需要用户自己指定collect传入的参数,精细的控制处理逻辑的,因此还是有必要了解一下collect方法内部原理的。
stream.collect()参数常用工具类:
/** * stream.collect() 参数常用工具类 */ public class CollectUtils { /** * stream 转换为 List * */ public static <T> Collector<T, List<T>, List<T>> toList(){ return new Collector<T, List<T>, List<T>>() { @Override public Supplier<List<T>> supplier() { return ArrayList::new; }
@Override public BiFunction<List<T>, List<T>, T> accumulator() { return (list, item) -> { list.add(item); return list; }; }
@Override public Function<List<T>, List<T>> finisher() { return list -> list; } }; } /** * stream 转换为 Set * */ public static <T> Collector<T, Set<T>, Set<T>> toSet(){ return new Collector<T, Set<T>, Set<T>>() { @Override public Supplier<Set<T>> supplier() { return HashSet::new; }
@Override public BiFunction<Set<T>, Set<T>, T> accumulator() { return (set, item) -> { set.add(item); return set; }; }
@Override public Function<Set<T>, Set<T>> finisher() { return set -> set; } }; } }
4.6 举例分析
我们选择一个简单而又不失一般性的例子,串联起这些内容。通过完整的描述一个流求值的全过程,加深大家对流的理解。
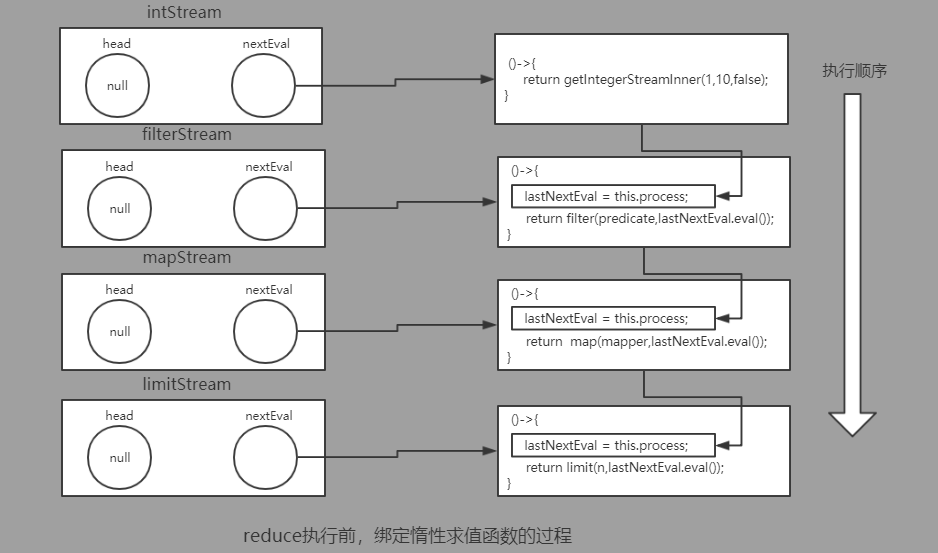
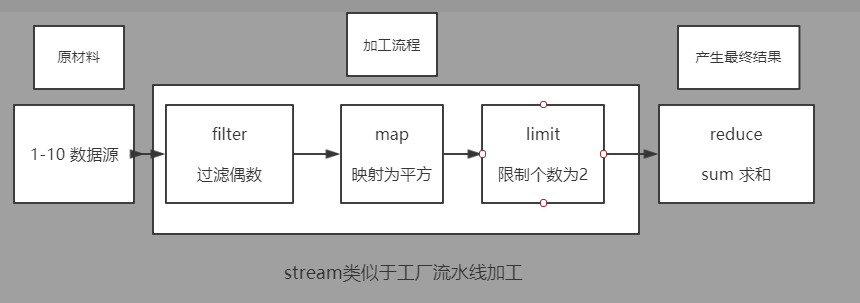
public static void main(String[] args){ Integer sum = IntegerStreamGenerator.getIntegerStream(1,10) .filter(item-> item%2 == 0) // 过滤出偶数 .map(item-> item * item) // 映射为平方 .limit(2) // 截取前两个 .reduce(0,(i1,i2)-> i1+i2); // 最终结果累加求和(初始值为0) System.out.println(sum); // 20 }
由于我们的stream实现采用的是链式编程的方式,不太好理解,将其展开为逻辑等价的形式。
public static void main(String[] args){
// 生成整数流 1-10 Stream<Integer> intStream = IntegerStreamGenerator.getIntegerStream(1,10);
// intStream基础上过滤出偶数 Stream<Integer> filterStream = intStream.filter(item-> item%2 == 0);
// filterStream基础上映射为平方 Stream<Integer> mapStream = filterStream.map(item-> item * item);
// mapStream基础上截取前两个 Stream<Integer> limitStream = mapStream.limit(2);
// 最终结果累加求和(初始值为0) Integer sum = limitStream.reduce(0,(i1,i2)-> i1+i2); System.out.println(sum); // 20 }
reduce强制求值操作之前的执行过程图:
reduce强制求值过程中的执行过程图 :
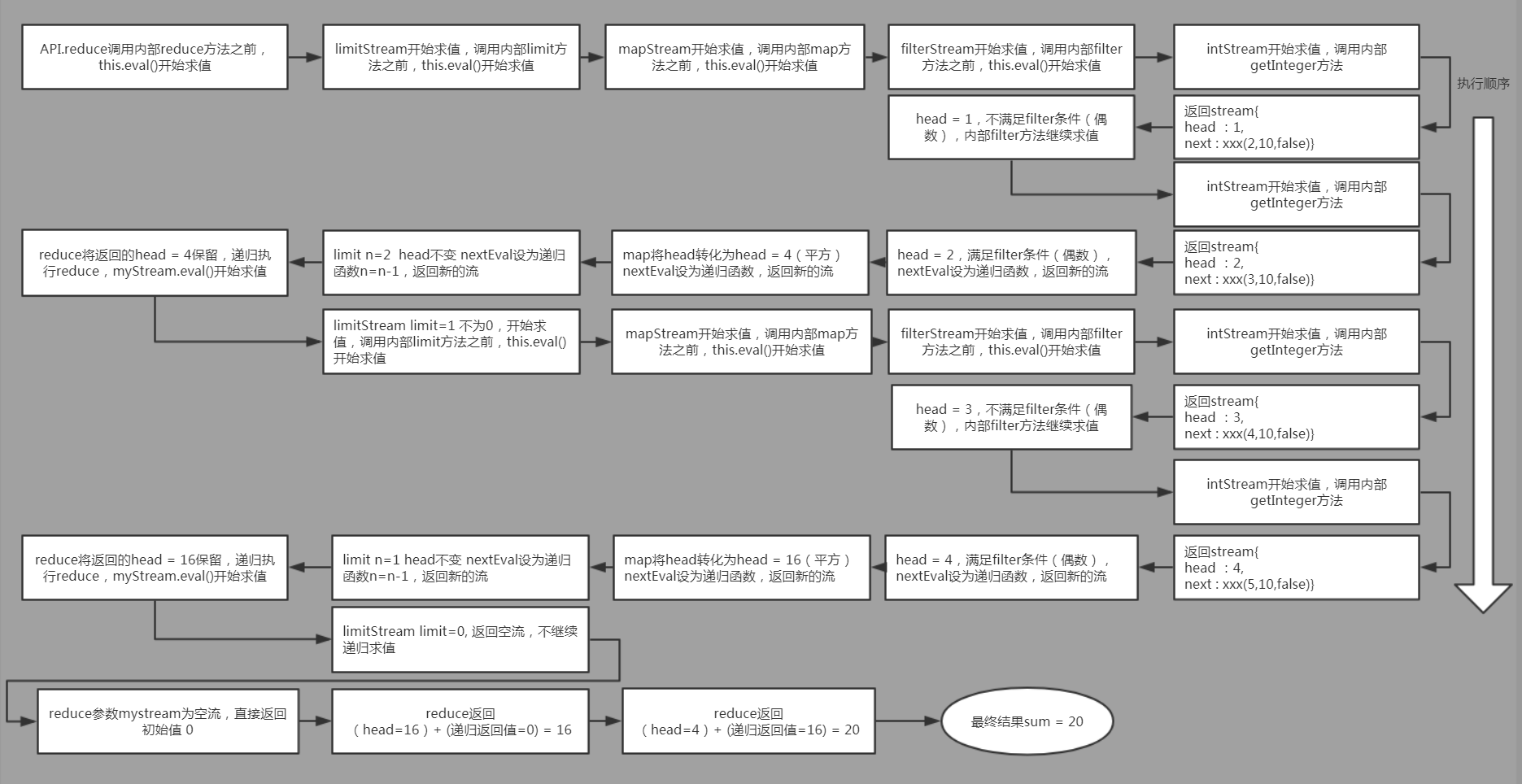
可以看到,stream的求值过程并不会一口气将初始的流全部求值,而是按需的、一个一个的进行求值。
stream的一次求值过程至多只会遍历流中元素一次;如果存在短路操作(limit、anyMatch等),实际迭代的次数会更少。
因此不必担心多层的map、filter处理逻辑的嵌套会让流进行多次迭代,导致效率急剧下降。
5.stream 总结
5.1 当前版本缺陷
1. 递归调用效率较低
为了代码的简洁性和更加的函数式,当前实现中很多地方都用递归代替了循环迭代。
虽然逻辑上递归和迭代是等价的,但在目前的计算机硬件上,每一层的递归调用都会使得函数调用栈增大,而即使是明显的尾递归调用,java目前也没有能力进行优化。当流需要处理的数据量很大时,将会出现栈溢出,栈空间不足之类的系统错误。
将递归优化为迭代能够显著提高当前版本流的执行效率。
2. API接口较少
限于篇幅,我们只提供了一些较为常用的API接口。在jdk中,Collector工具类提供了很多方便易用的接口;对于同一API接口也提供了多种重载函数给用户使用。
以目前已有的功能为基础,提供一些更加方便的接口并不困难。
3. 不支持并行计算
由于流在求值计算时生成的是对象的副本,是无副作用的,很适合通过数据分片执行并行计算。限于个人水平,在设计之初并没有考虑将并行计算这一特性加入进来。
5.2 函数式编程
仔细分析整个流的执行过程,与其说流是一个对象,不如说流是一个高阶函数(higher-order function)。每当map、filter绑定了一个流,新生成的流其实是一个更加复杂的函数;每一层封装,都会使新生成的流这一高阶函数比起原基础变得更加强大和复杂。map、filter就像一个个的基础算子,在接收对应的过程后(filter(过滤出偶数)、map(平方映射)),可以不断的叠加,完成许许多多非常复杂的操作。
这也是函数式编程的中心思想之一:将计算过程转化为一系列嵌套函数的调用。
5.3 总结
最初是在学习《计算机程序的构造和解释》(SICP)中stream流计算时突发奇想的,想着能不能用java来实现一个和书上类似的流计算框架,能和jdk的stream流功能大致相同,最终,通过反复地思考和尝试才将心中所想以java代码的形式呈现出来。
SICP是一本小众但别具一格的计算机书籍,许多人认为它不太实用。我个人认为,虽然计算机技术发展日新月异,但是计算机技术的基础理论却往往变化缓慢,如果能够抓住技术发展背后那不变的元知识,就不容易在技术的浪潮中失去方向。SICP就是这样一本教授计算机科学元知识的书籍,虽然一开始有点枯燥,却能慢慢品味出其美妙之处。
希望大家在阅读完这篇博客之后,能更好的理解流计算,更好的理解函数式编程。
SICP公开课视频(中英字幕):https://www.bilibili.com/video/av8515129。
这篇博客的完整代码在我的github上:https://github.com/1399852153/Streamjava,存在许多不足之处,请多多指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号