Node.js制作爬取简书内容的爬虫
用了Nodejs制作了简单的爬虫,爬取了简书的文章内容,代码中contentIds有几个,就爬取了几个网页的内容。
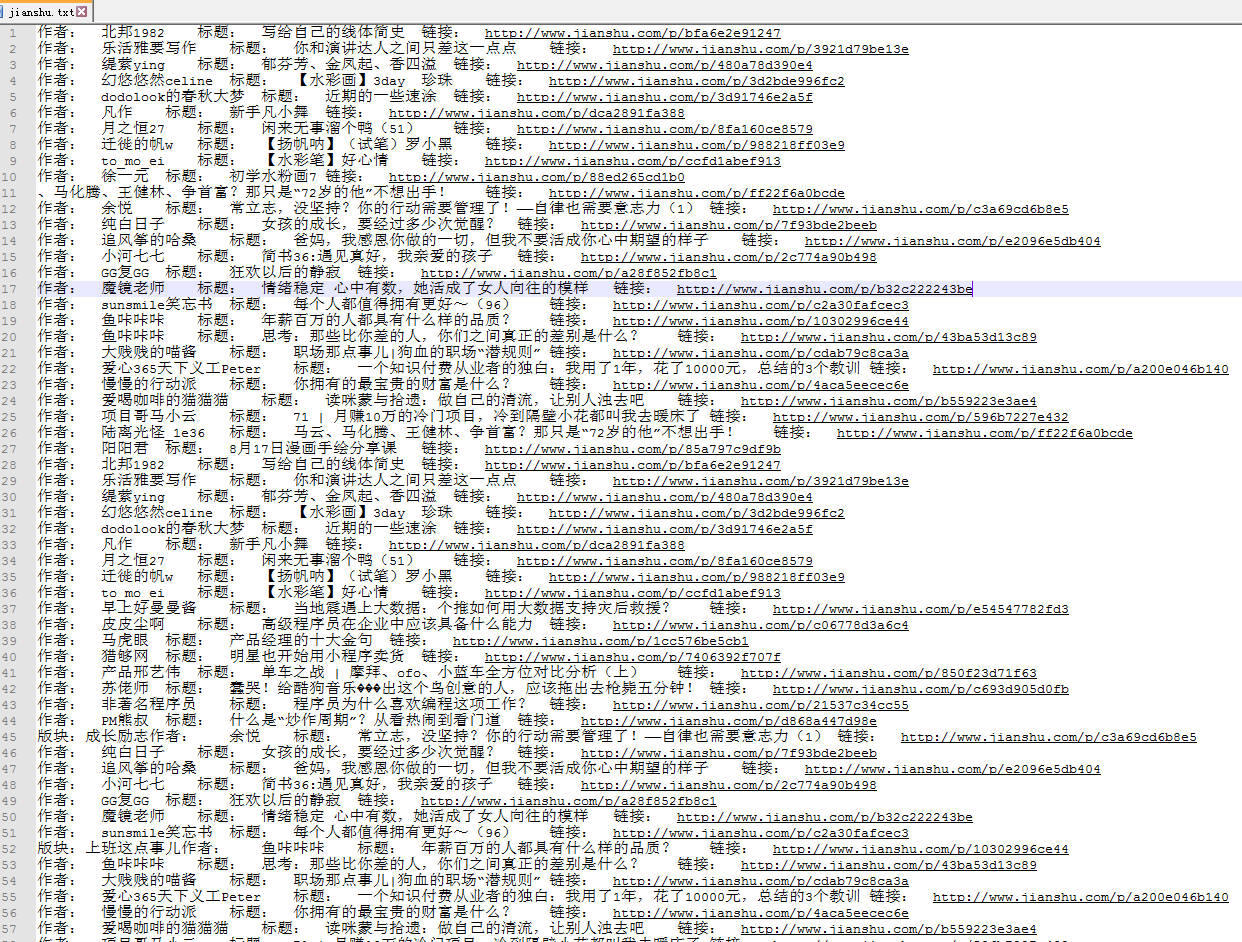
可以直接看结尾截图的结果。
下面两张截图,是说明怎么用cheerio获取自己想要的内容。
下面截图,是代码中:第46行,利用cheerio模块,获取版块标题内容
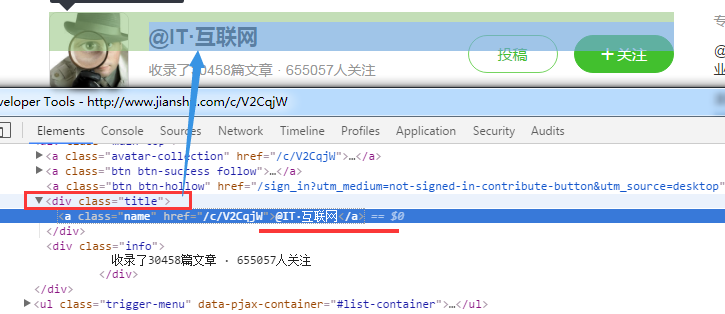
下面截图:代码第50行,利用cheerio获取作者

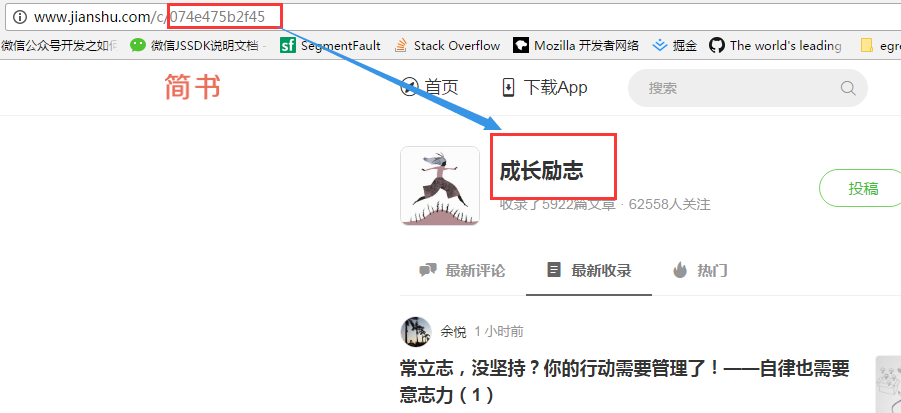
代码中:var contentIds = ["074e475b2f45","Jgq3Wc","8c92f845cd4d","V2CqjW"],从下图来。引入要爬取多个网页,所以就得拼接url.然后利用Promise的回调特性,最后将内容都打印出来。
1 // nodejs官方文档:http://nodejs.cn/ 2 // 引入http模块 3 var http = require('http') 4 5 // bluebird模块如果引用,必须下载 npm install bluebird 6 // nodejs本身有Promise,不引入也可以。 7 // 引入bluebird也是为了引入Promise,callback效率可能必nodejs本身的快。可能!! 8 // bluebird学习链接:http://ricostacruz.com/cheatsheets/bluebird.html 9 var Promise = require('bluebird') 10 11 // 引入cheerio,类似jquery库,必须下载,npm install cheerio 12 // cheerio文档:https://www.npmjs.com/package/cheerio 13 // 中文文档:https://cnodejs.org/topic/5203a71844e76d216a727d2e 14 // 用法跟jquery类似 15 var cheerio = require('cheerio') 16 17 // 路径模块 18 var path = require('path') 19 20 // 文件系统模块 21 var fs = require('fs') 22 23 // 简书的通用的url 24 var url = 'http://www.jianshu.com/c/' 25 26 // 简书每个页面url不同的部分 27 // 版块内容: 28 // 074e475b2f45:成长励志 29 // Jgq3Wc:上班这点事儿 30 // 8c92f845cd4d:漫画·手绘 31 // V2CqjW:@IT·互联网 32 var contentIds = ["074e475b2f45","Jgq3Wc","8c92f845cd4d","V2CqjW"] 33 34 // 过滤自己想要的数据,放到对象里面 35 function filterData(html) { 36 var $ = cheerio.load(html) 37 var lis = $('.have-img') 38 // 每个版块的内容 39 var board = { 40 // 版块标题 41 title:'', 42 // 版块文章,里面是作者信息和文章标题,和链接 43 articles:[] 44 } 45 // 获取版块标题 46 board.title = $('div.title').children('a').text() 47 lis.each(function (item,value) { 48 var lis = $(this) 49 // 获取作者 50 var author = lis.find('.name').children('a').text() 51 // 获取文章标题 52 var title = lis.find('.content').children('a').text() 53 // 获取文章链接 54 var link = lis.find('.content').children('a').attr('href') 55 board.articles.push({author:author, title:title, link:"http://www.jianshu.com"+link}) 56 57 }) 58 return board 59 } 60 // 打印内容到控制面板 61 function printData(board) { 62 console.log(board.title + "\n") 63 board.articles.forEach(function (value) { 64 console.log("作者:"+"\t"+value.author +"\t"+ "标题:"+"\t"+value.title +"\t"+"链接:"+"\t"+value.link ) 65 }) 66 console.log("\n") 67 } 68 // 将数据写入文件 69 function writeToFile(board) { 70 // 拼接数据内容 71 var html = '\n ' + '版块:' + board.title + '\n' 72 board.articles.forEach(function (value) { 73 html += "作者:"+"\t"+value.author +"\t"+ "标题:"+"\t"+value.title +"\t"+"链接:"+"\t"+value.link +"\n" 74 }) 75 // 将数据写入到文件,文件路径为当前路径,文件名是jianshu.txt 76 fs.appendFileSync(path.join(__dirname,'jianshu.txt'),html) 77 } 78 // 获取简书内容 79 function getJianShuContent(url) { 80 // 通过Promise获取简书内容,并且返回 81 return new Promise(function (resolve,reject) { 82 http.get(url,(res)=>{ 83 var html = '' 84 res.on('data',(data)=>{ 85 // 获取到的数据拼接到HTML中 86 html += data 87 }) 88 res.on('end',function () { 89 // 结束后将数据放到resolve 90 resolve(html) 91 }) 92 }).on('error',function (e) { 93 reject(e) 94 console.log('获取数据错误!!!!!!!!') 95 }) 96 }) 97 } 98 var jianShuContent = [] 99 100 contentIds.forEach(function (id) { 101 // 将获取到的放到数组中,利用Promise的特性 102 jianShuContent.push(getJianShuContent(url + id)) 103 }) 104 // 迭代数组,然后遍历,打印内容,写入内容 105 Promise.all(jianShuContent).then(function (pages) { 106 pages.forEach(function (value) { 107 var board = filterData(value) 108 printData(board) 109 writeToFile(board) 110 }) 111 })
控制面板输出结果:
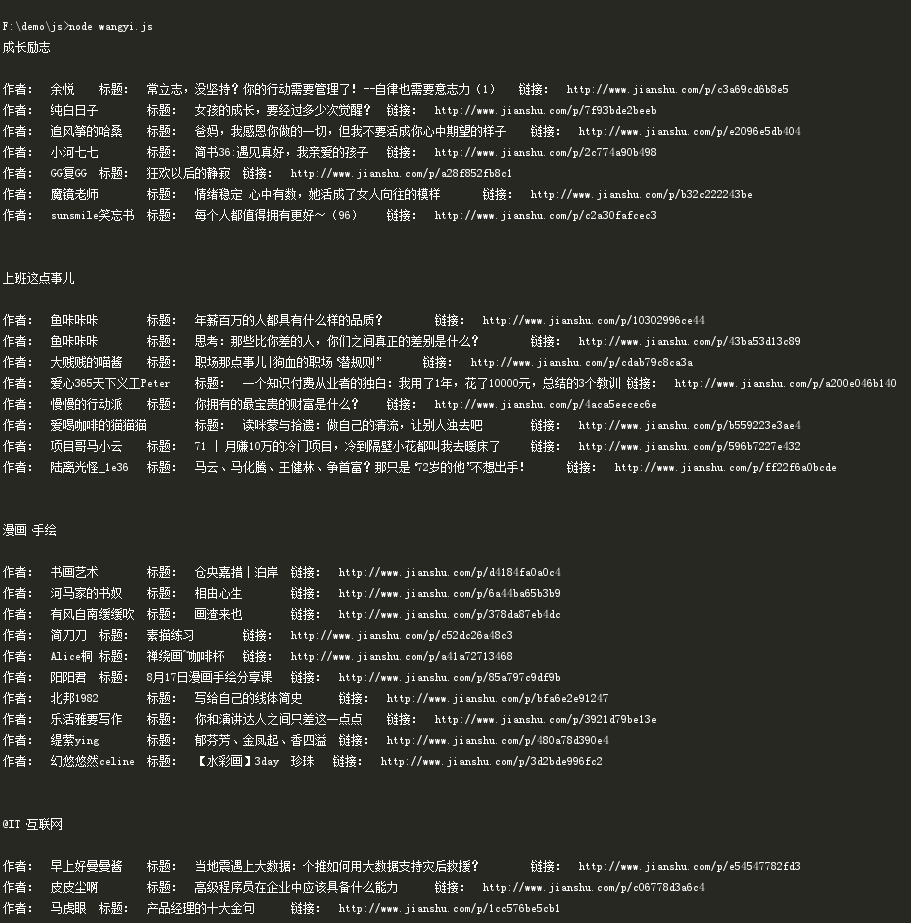
写入文件结果: