分布式锁
分布式锁主要用于在分布式环境中保护跨进程、跨主机、跨网络的共享资源实现互斥访问,以达到保证数据的一致性。前几天看到有个技术群里的同行在问分布式锁的问题,说是被面试官各种刁难。疫情影响下,各行各业都挺卷,面试官的意思很明确,你有造火箭的经验吗,有的话去他们公司造自行车,如果没有,今天的面试就到这里了。
▎设计分布式锁
-
分布式系统环境下,一个方法在同一时间只能被一台机器的一个线程执行
-
高性能、高可用的获取锁与释放锁
-
可重入
-
具备锁失效机制,防止死锁
-
阻塞特性
▎基于数据库的实现
核心思想:在数据库中创建一个表,表中包含资源名等字段,并在资源名字段上创建唯一索引,想要获取某个资源,就使用资源名向表中插入数据,成功插入则获取锁,执行完成后删除对应行的数据释放锁。
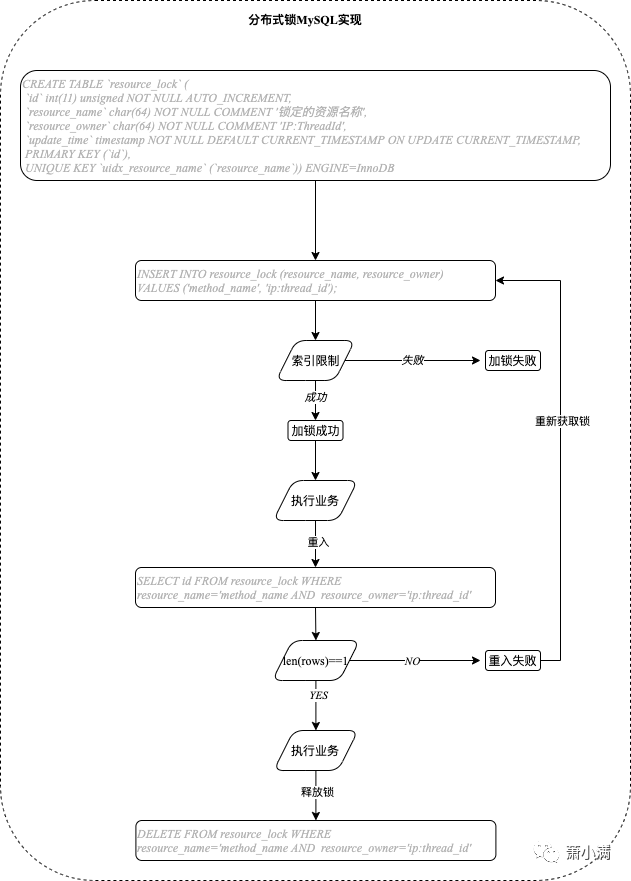
-
基于数据库实现的,数据库的可用性和性能将直接影响分布式锁的可用性及性能,所以数据库需要双机部署、数据同步、主备切换。适用于对锁的性能要求不高的场景
-
锁失效机制,有可能出现成功插入数据后,服务器宕机,对应的数据没有被删除,当服务恢复后一直获取不到锁。可以在表中新增一列,用于记录失效时间,并需要开启定时任务清除失效的数据
▎基于Redis的实现
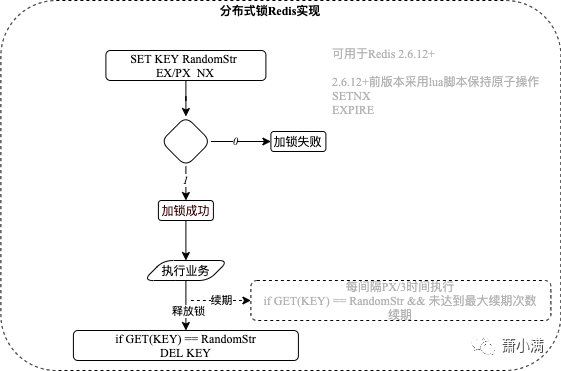
-
产生随机字符串RandomStr,执行SET PX NX,返回1,则获得锁
-
Redis2.6.12以前版本可使用lua脚本打包SETNX,EXPIRE保持原子操作
-
开启守护线程,在最大续期次数内,间隔时间进行锁续期
-
完成业务后,释放RandomStr对应的锁
▎基于Zookeeper的实现
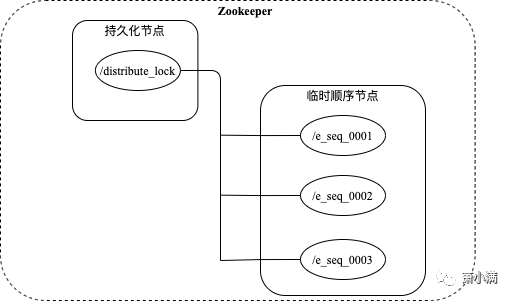

-
线程A在/distribute_lock下创建临时顺序节点
-
线程A获取/distribute_lock下的全部节点并排序,如果线程A创建的节点是最小节点,则获得锁;如果不是,则监听比自己次小的节点
-
比自己次小的节点发生变更(删除),重复执行第二步
-
业务执行完毕,删除节点,释放锁
-
为什么没使用单节点创建互斥来实现:避免引发羊群效应,带来瞬时并发问题。比如1000个节点需要同步,当节点释放锁时,其余999个节点会同时收到通知并尝试创建节点,可能引起性能问题
相比Redis,Zookeeper实现不需要担心锁超时时长的设置和续期问题,但需要频繁的创建和删除节点,性能上不如Redis,可根据具体场景选择适合的实现方式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号