
聊聊InnoDB
InnoDB是MySQL的数据库引擎之一,现为MySQL的默认存储引擎。
「存储单元」
既然是存储引擎,就要从InnoDB索引数据结构、数据组织方式说起。
-
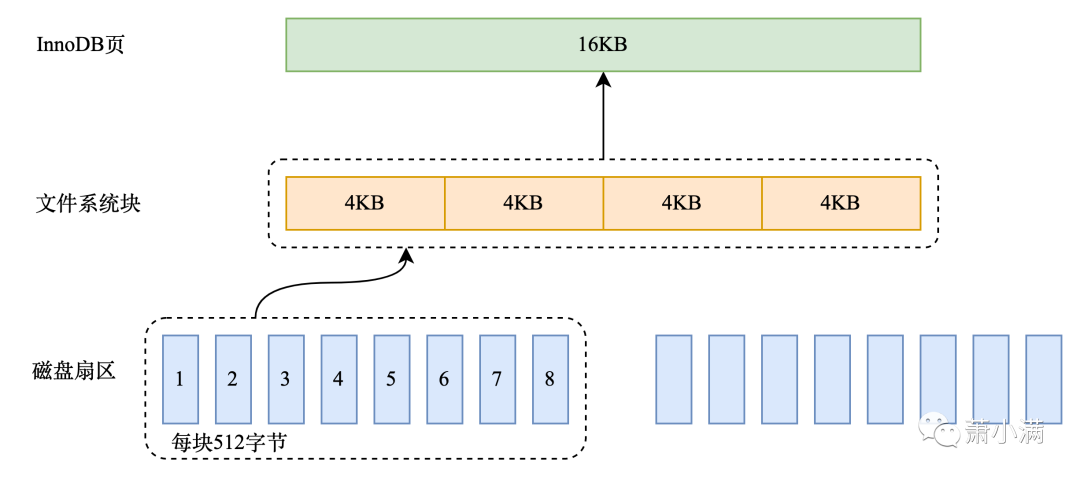
数据持久化存储磁盘里,磁盘的最小单元是扇区,一个扇区的大小是512字节
-
文件系统的最小单元是块,一个块的大小是4KB
-
InnoDB存储引擎的最小单元称之为页,一个页的大小是16KB
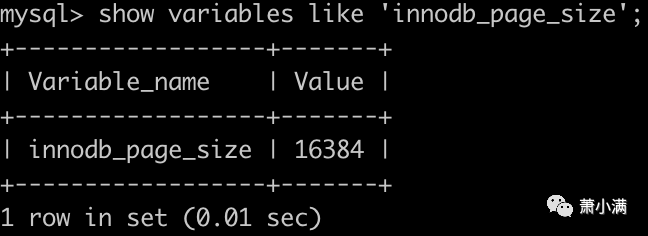
查看InnoDB页的大小
mysql> show variables like 'innodb_page_size';
MySQL数据库中,表的记录存储在页中,那么一页可以存多少行数据?假如一行数据的大小为512字节,那么计算出一页大约能存放32条数据。
「B树与B+树」
MySQL的最小存储单元是页,每次页的访问就意味着一次IO。为了提升查找速度、减少IO,我们引入了B+树,先来看下B树和B+树的存储结构。
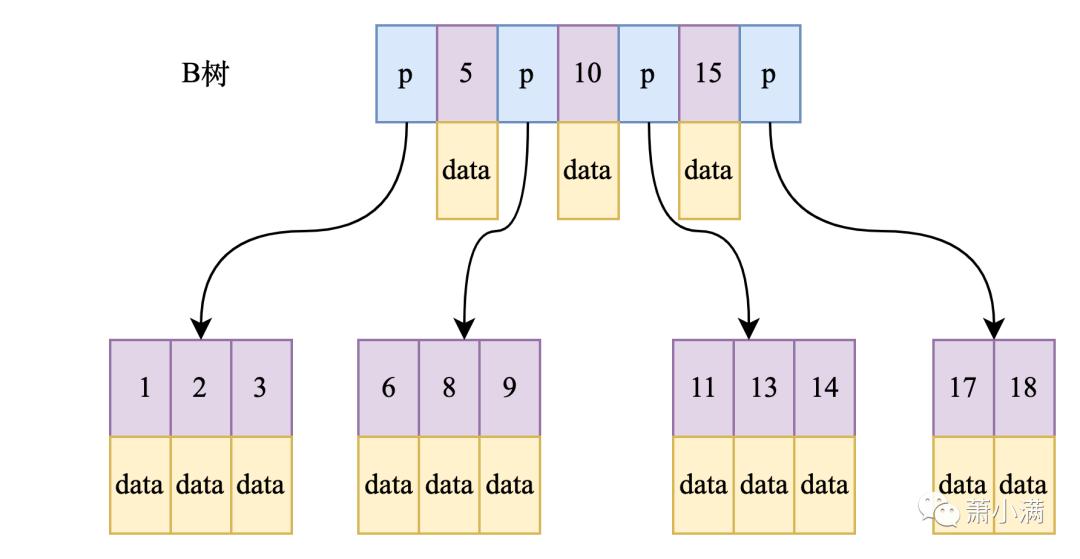
B树的特点
-
每个节点都存储数据,包括中间节点
-
节点之间没有指针相连
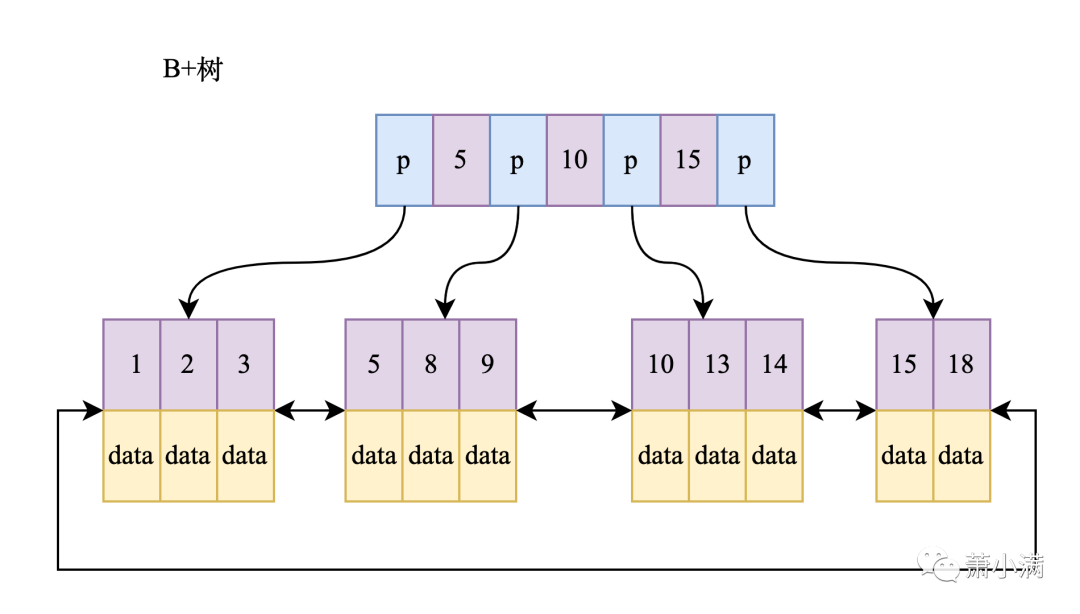
B+树的特点
-
只有叶节点存储数据
-
节点之间有双向指针相连
为什么是B+树
-
InnoDB中页是基本存储单位,一个树节点就是一个InnoDB页。B树节点要存储数据,然而页的大小有限,每个节点存储KEY就相对少;存储同样规模的KEY,树的高度就会增加,每增加一层高度,就多一次IO,影响查询效率。B+树中间节点不存储数据,每页可以存储更多的KEY,降低树的高度。
-
B+树每一层节点之间有指针相连,遍历时只需要对叶节点进行遍历即可,这个特性使得B+树非常适合做范围查找。
「聚簇与非聚簇索引」
聚簇索引也称为聚类索引,聚簇索引确定表中数据的物理顺序。表中数据的物理顺序只有一种,因此对应的聚簇索引只能有一个,InnoDB中数据行按照主键进行聚集,所以有且仅有一个主键。
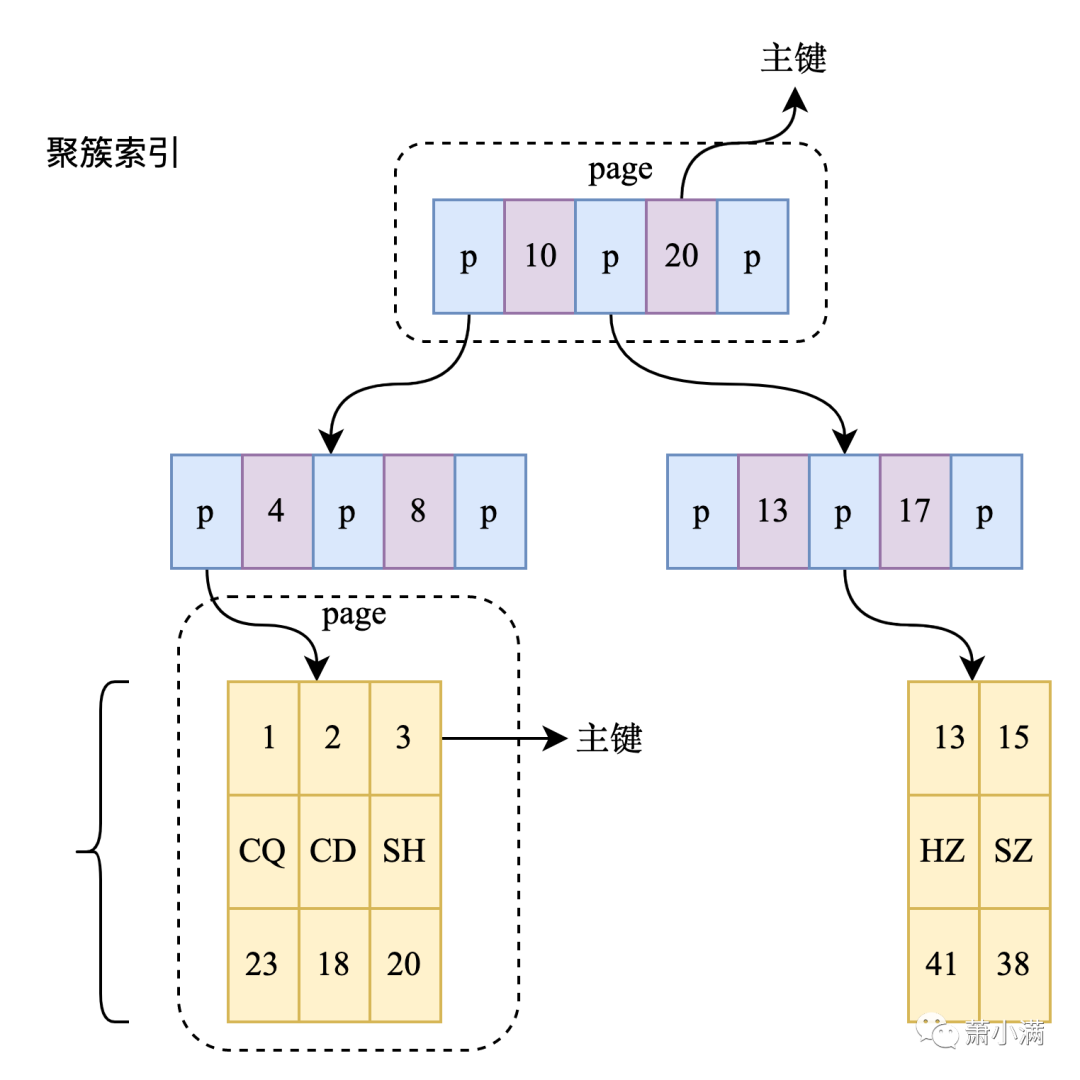
检索过程(PK=3)
-
找到根节点,加载到内存(IO)
-
在内存查找PK=3所在区间(0,10),找到对应指针(内存查找)
-
根据指针找到第二层页地址并载入内存(IO)
-
在内存查找PK=3所在的区间(0,4),找到对应指针(内存查找)
-
根据指针找到第三层页地址并载入内存(IO)
-
在内存中查找PK=3的记录(内存查找)
整个查询需要3次磁盘I/O操作和3次内存查找操作,磁盘I/O相对于内存查找耗时高得多,因此在数据库查询中,「减少磁盘访问是数据库的性能优化的主要手段」
为什么主键不是uuid
如果主键是uuid,频繁的插入InnoDB会频繁地移动磁盘块,非常影响写入性能。如果主键是自增INT,那么对应的数据是相邻地存放在磁盘上,写入性能比较高。
非聚簇索引与聚簇索引的区别在于:非聚簇索引的子叶节点存储的是主键值,而非记录的物理地址。
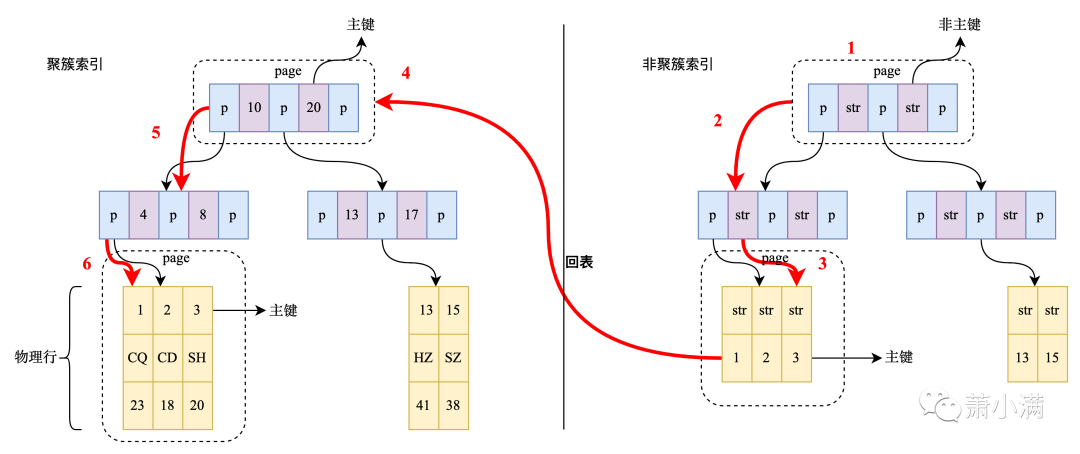
检索过程
-
从非聚簇索引查找到对应的主键
-
根据主键查找相应的记录(回表)
-
1、2步检索过程同聚簇索引检索过程
如果树的高度为3层,那么非聚簇索引的检索需要6次IO和6次内存查找。通过索引可以提高查询效率,但多一个索引就会多生成一棵非聚簇索引树。因此,索引不能随意增加。进行写库操作的时候,有多少索引,就需要维护多少棵索引树的变化。
回表或者二次查询:使用聚簇索引查询可以直接定位到记录,而非聚簇索引通常需要扫描两遍索引树,即先通过非聚簇索引定位到主键值,再通过聚簇索引定位到行记录,这就是所谓的回表查询,它的性能比只扫描一遍索引树低很多,下次的内容聊聊如何避免回表的问题。

