

spark面试必知必会
哈哈哈,没想到脑海里复现的是这么熟悉的话,必知必会,三天入门。
1:SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。
session = session.SparkSession \
.builder \
.appName(job_name) \
.enableHiveSupport() \
.getOrCreate()
如把Spark集群当作服务端,那Spark Driver就是客户端,SparkContext则是客户端的核心;如注释所说 SparkContext用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables),所以说SparkContext为Spark程序的根本都不为过,可以理解为main函数。
2:Spark支持的三种典型集群部署方式,即standalone、Spark on Mesos和Spark on YARN
3:
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
- Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
- Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
- Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
- Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
- DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法
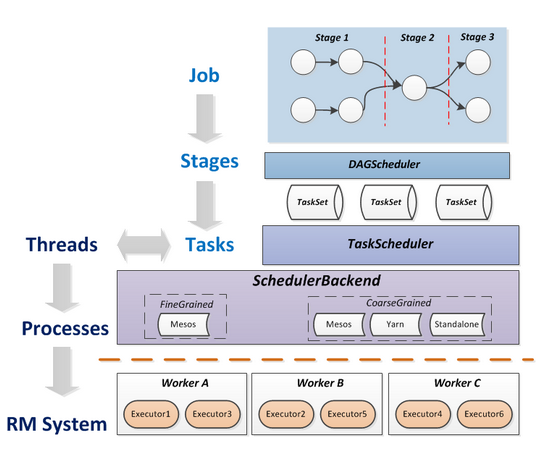
- Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
# ref:
https://www.cnblogs.com/xia520pi/p/8609602.html
https://www.cnblogs.com/cxxjohnson/p/8909578.html
