

MSE损失函数和交叉熵损失函数的对比
为什么要用交叉熵来做损失函数:
在逻辑回归问题中,常常使用MSE(Mean Squared Error)作为loss函数,此时:
这里的 就表示期望输出,
表示原始的实际输出(就是还没有加softmax)。这里的m表示有m个样本,loss为m个样本的loss均值。MSE在逻辑回归问题中比较好用,那么在分类问题中还是如此么?我们来看看Loss曲线。
将原始的实际输出节点都经过softmax后拿出一个样例来看,使用MSE的loss为的loss函数为:
其中 和
为常数,那么loss就可以简化为
取c1=1,c2=2,绘制图像:
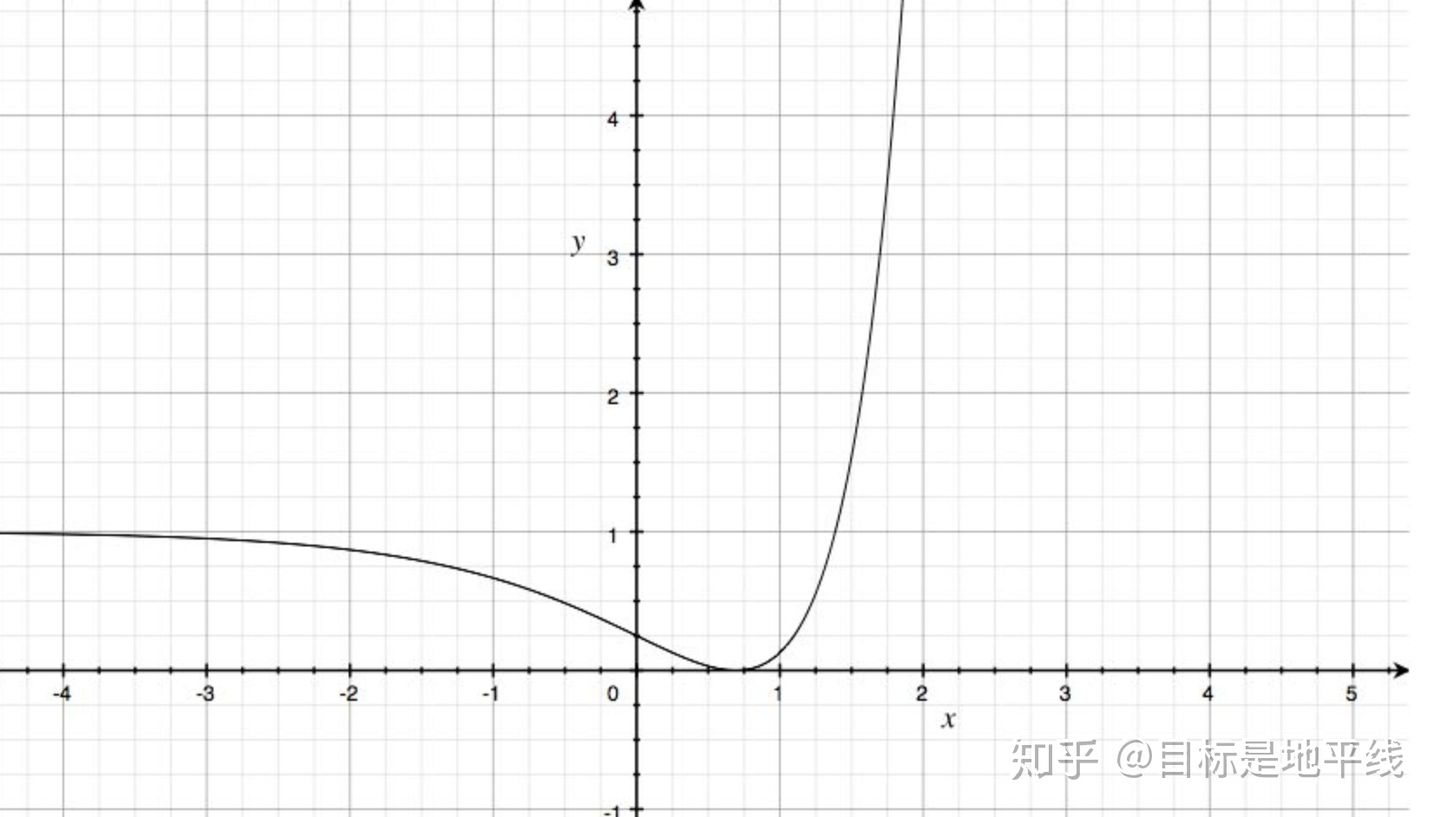
这是一个非凸函数,只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。所以MSE在分类问题中,并不是一个好的loss函数。
如果利用交叉熵作为损失函数的话,那么:
还是一样, 就表示期望输出,
表示原始的实际输出(就是还没有加softmax),由于one-hot标签的特殊性,一个1,剩下全是0,loss可以简化为:
加入(softmax)得:
取C1=1,C2=2绘制曲线如下 :
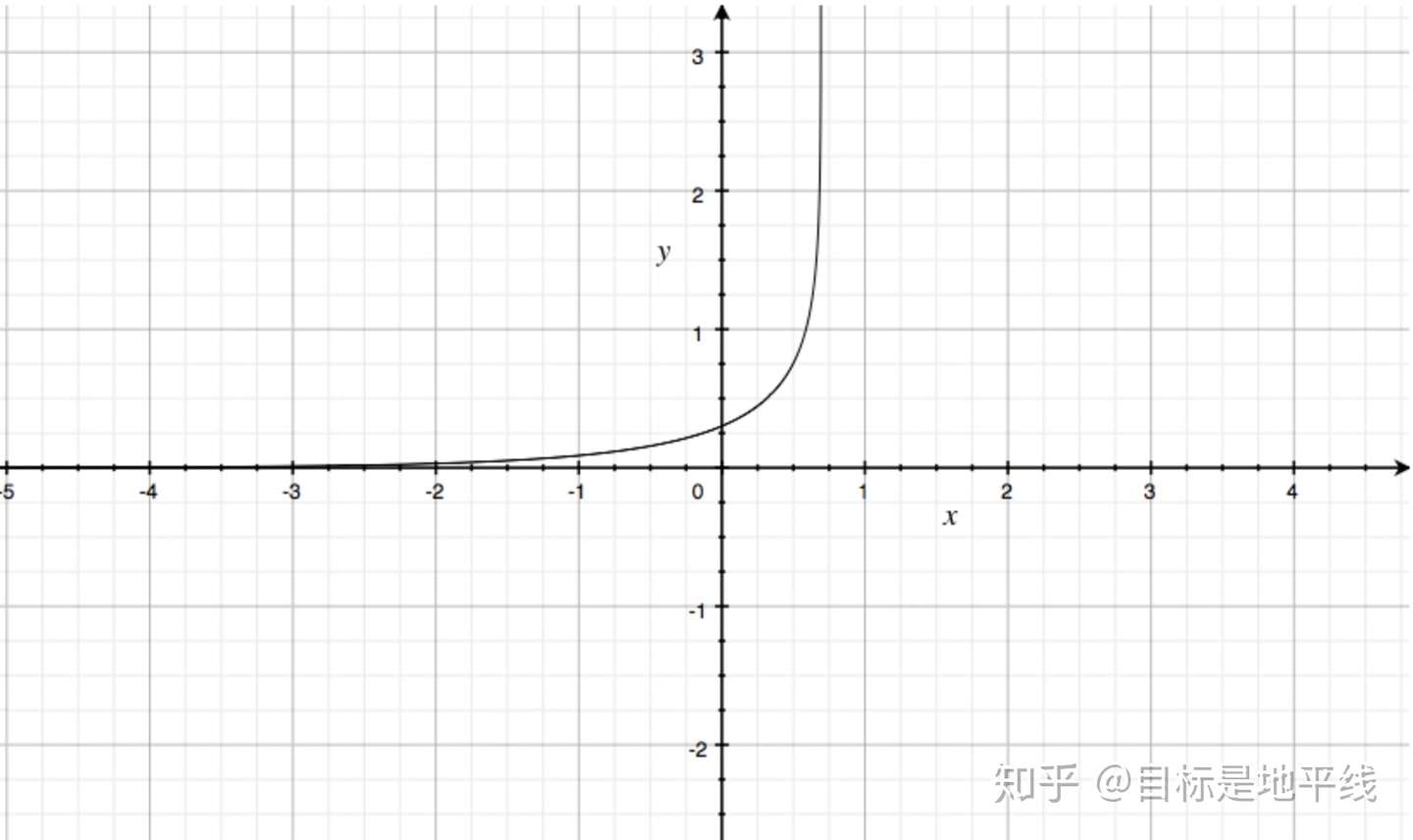
相对MSE而言,曲线整体呈单调性,loss越大,梯度越大。便于梯度下降反向传播,利于优化。所以一般针对分类问题采用交叉熵作为loss函数。
Pytorch中的CrossEntropyLoss()函数,计算公式如下:
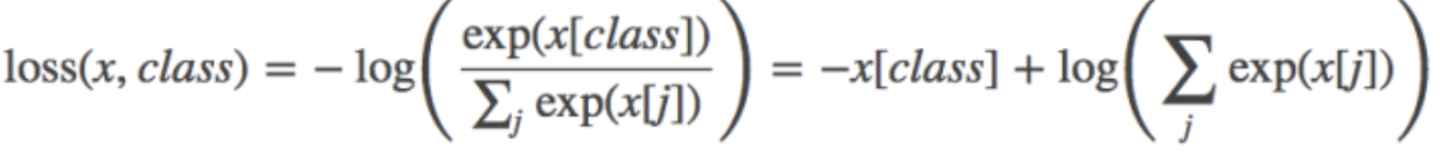
ref:https://zhuanlan.zhihu.com/p/145533813
交叉熵损失函数相对MSE避免了梯度消失的一些推导:

ref:https://www.cnblogs.com/wanghui-garcia/p/10862733.html
