

Hierarchical Softmax
1:霍夫曼树原理
输入:权值为w1,w2,...wn的n个节点
输出:对应的霍夫曼树
1)将w1,w2,...wn看做是有n棵树的森林,每个树仅有一个节点。
2)在森林中选择根节点权值最小的两棵树进行合并,得到一个新的树,这两颗树分布作为新树的左右子树。新树的根节点权重为左右子树的根节点权重之和。
3) 将之前的根节点权值最小的两棵树从森林删除,并把新树加入森林。
4)重复步骤2)和3)直到森林里只有一棵树为止。
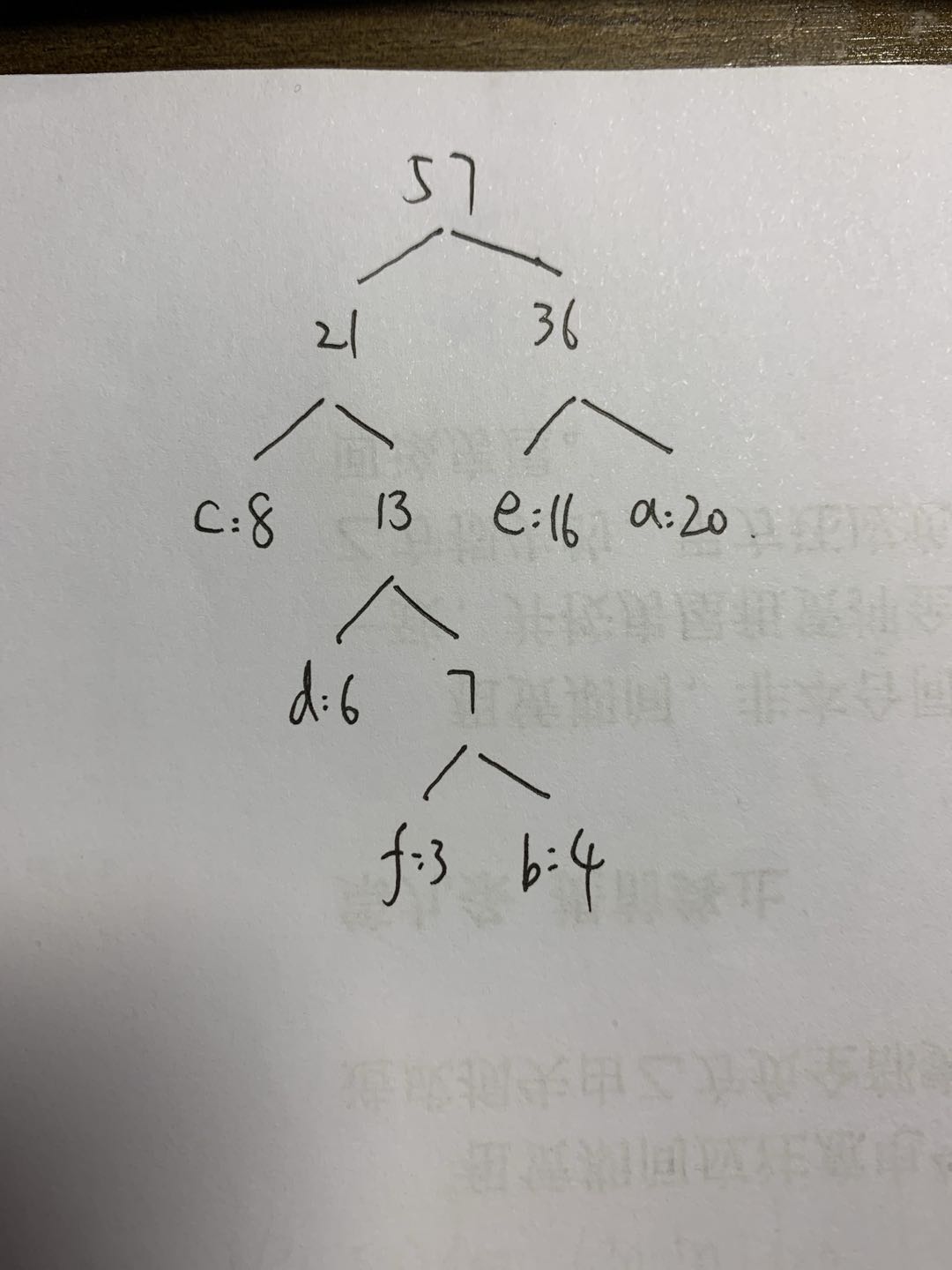
下面我们用一个具体的例子来说明霍夫曼树建立的过程,我们有(a,b,c,d,e,f)共6个节点,节点的权值分布是(20,4,8,6,16,3)。
首先是最小的b和f合并,得到的新树根节点权重是7.此时森林里5棵树,根节点权重分别是20,8,6,16,7。此时根节点权重最小的6,7合并,得到新子树,依次类推,(需要注意的是,如果新生成的字数根节点比其余节点值大,则并列生长)最终得到下面的霍夫曼树。
2:Hierarchical Softmax
word2vec中,从输入层到隐藏层的映射,采用简单的对所有输入词向量求和并取平均的方法,而从隐藏层到输出的softmax层,为了避免计算所有词的softmax概率,使用霍夫曼树来代替从隐藏层到输出softmax层的映射,霍夫曼树的所有内部节点类似于神经网络隐藏层的神经元,其中,根节点的词向量对应投影后的词向量,而叶子节点类似于之前神经网络softmax输出层的神经元,且叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
word2vec中,采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,则,被划分为右子树而成为正类的概率为p(+),被划分为左子树而成为负类的概率是p(-)=1-p(+)。在某一个内部节点,要判断是沿左子树还是右子树走的标准就是看P(−),P(+)谁的概率值大。而控制P(−),P(+)谁的概率值大的因素一个是当前节点的词向量,另一个是当前节点的模型参数θ。

3:优缺点
优点:使用霍夫曼树来代替传统的神经网络,可以提高模型训练的效率。
缺点:如果我们的训练样本里的中心词ww是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了。
不同词汇(类别)作为输出时,所需要的判断次数实际上是不同的。越频繁出现的词汇,离根结点越近,所需要的判断次数也越少。从而使最终整体的判断效率更高。
