
遍历文件总结
1.遍历主要用到os模块的walk和listdir两个模块。查看os源码不难发现,使用os.walk将返回遍历目录的路径,文件夹名,与文件名。listdir方法以list的数据结构返回文件名
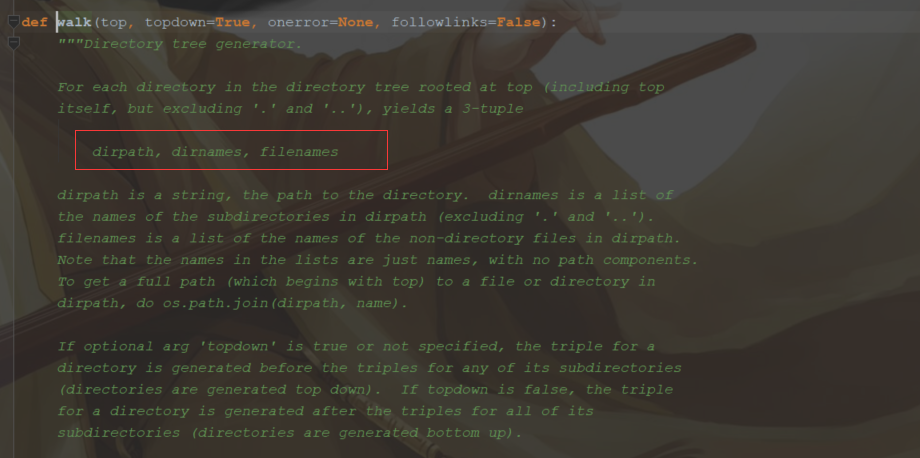
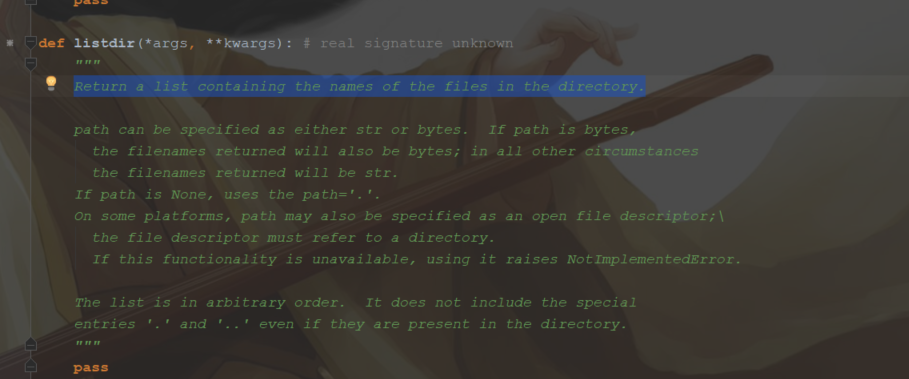
2.源码分享,主要形式为三种.
import collections import subprocess import platform import os # 获取指定目录下,指定格式的文件, Usage:get_all_files('/Case', '.yaml') def get_all_files(root: str, pattern: str)-> dict: extension_file = collections.OrderedDict() for root, dirs, files in os.walk(root): for filename in files: if filename.endswith(pattern): path = os.path.join(root, filename).replace('\\', '/') extension_file[filename] = path return extension_file # TODO:递归遍历指定目录,只获取文件名,待优化 def iter_files(path): filename = [] def iterate_files(path): path_rest = path if not isinstance(path, bytes) else path.decode() abspath = os.path.abspath(path_rest) try: all_files = os.listdir(abspath) for items in all_files: files = os.path.join(path, items) if os.path.isfile(files): filename.append(files) else: iterate_files(files) except (FileNotFoundError, AttributeError, BytesWarning, IOError, FileExistsError): pass iterate_files(path) return filename # 调用subprocess.Popen创建进程,通过subprocess.PIPE与之交互 # 目录结构过于复杂,会造成通信阻塞 def files_progress(pattern): system, files = platform.system(), [] if system is 'Windows': view_file_command = 'dir' else: view_file_command = "find {0}".format(pattern) p = subprocess.Popen(view_file_command, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) for line in p.stdout.readlines(): if not isinstance(line, str): format_line = str(line.decode('gbk')) if system is 'Windows': if format_line.strip().endswith(pattern): files.append([content for content in format_line.split() if content.endswith(pattern)][0]) else: files.append(line) return files if p.wait() == 0 else None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号