

一、shell 变量
1、自定义局部变量
#等号两端不能有空格 var_name=liming #打印变量值 echo $var_name #使用花括号可以用于字符串拼接 echo ${var_name}123 #删除变量 unset $var_name
2、自定义常量
var_name=liming #设置为只读 readonly var_name

3、自定义全局变量
局部变量只能在一个文件中使用,全局变量在当前脚本文件和子shell脚本文件中都可以使用。
export var_name=jenny #删除 unset var_name
4、特殊符号变量
$n
#获取文件名 ${0} #获取第一个输入参数 ${1} ... #获取第十个输入参数 ${10}
$#:获取输入参数的个数;
$*和$@:获取所有输入参数;区别:在有双引号时,“$*”将列表参数组成一个字符串,“$@”一个参数是一个字符串。可以使用for循环验证。
for var in "$@" do echo ${var} done
$?:获取上一个shell命令的退出状态码或者是退出值。每一个shell命令都有一个返回值,用来表示命名是否执行成功,一般“0”表示成功。
$$:获取shell进程号。
5、自定义系统环境变量
当前用户进入shell环境初始化时会加载全局配置文件/etc/profile里面的环境变量,供给所有shell程序使用。只要是所有shell程序都可能使用的变量都可以放在/etc/profile文件中。
创建环境变量步骤:vim打开/etc/profile文件,添加export VAR_NAME=value,保存退出,使用source /etc/profile重新加载。
shell工作环境分类
1)交互式shell环境:需要用户参与互动的shell环境;
2)非交互式shell环境:只执行命令。
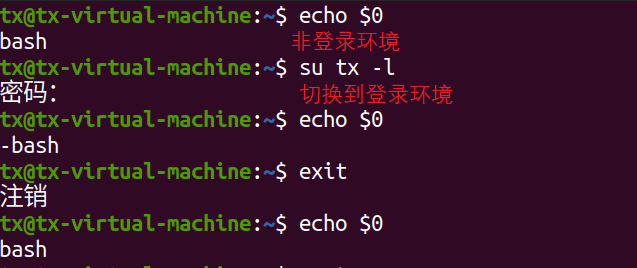
3)登录shell环境:需要输入用户名和密码登录到系统,会首先执行/etc/profile/配置文件加载环境变量,使用命令echo $0可以查看是否是登录环境,如果输出-bash,说明是登录环境,如果输出bash说明是非登录环境。命令"su 用户名 "可切换至非登录环境。
4)非登录shell环境:不使用用户名和密码进入Linux系统,会首先执行~/.bashrc。命令"su 用户名 -l"可切换至登录环境。
6、字符串截取
VAR1=Jenny #${变量名:start:len} #从0开始截取两个,输出Je echo ${VAR1:0:2} #${变量名:start}输出nny echo ${VAR1:2} #${变量名:0-start:len} 表示从右侧的第start各元素开始,向右截取len个 #输出 ny echo ${VAR1:0-2:2} #${变量名#*char},从左侧开始截取第一次出现char字符的右侧所有字符串 #nny echo ${VAR1#*e} #${变量名##*char},从左侧开始截取最后一次出现char字符的右侧所有字符串 #y echo ${VAR1##*n} #${变量名%*char},从右侧开始截取第一次出现char字符的右侧所有字符串 #${变量名%%*char}。从右侧开始截取最后一次出现char字符的右侧所有字符串
二、shell内置命令
shell的命令分为内置命令和外部脚本执行文件。内置命令属于shell内部,执行速度块。外部脚本文件需要磁盘I/O操作并fork一个新进程,执行速度相对慢。
1、alias给命令起别名
alias 别名=命令 #取消别名 unalias 别名
2、echo输出字符串
#输出不换行 echo -n "hello" #输出换行 echo "hello" #解析转义字符 echo -e "hello\n"
3、read从标准输入中获取数据并赋值给变量。默认从终端控制台中读入,可以使用重定向从文件中读取。
1)read -p 提示 变量
#-p表示显示提示信息 read -p "please input name age hobby" name age hobby echo "name=${name}" echo "age=${age}" echo "hobby= ${hobby}"
2)read -n num 变量 指定该读取num个字符到变量中
3) read -t 秒数 变量 设置超时时间
4)read -s 静默模式,不会在屏幕上显示
#在15秒内输入 read -t 15 -sp "please input pwd :" pwd1 echo read -t 15 -sp "please input pwd again : " pwd2 echo if [ $pwd1 == $pwd2 ] then echo "ok" else echo "no" fi
4、exit
退出当前shell进程,并返回状态码。
5、declare
declare -a 数组名=( 元素1 元素2 元素3) -a参数指定创建普通索引数组
declare -A 数组名=(["key1"]=value1 ["key2"]=value2 ["key3"]=value3) -A参数指定创建关联式数组
echo "创建索引数组" declare -a arry1=( 101 "liming" 20 ) echo "获取arry1中第一个元素:" ${arry1[0]} echo "获取arry1中所有元素:" ${arry1[*]} echo echo "创建关联数组" declare -A arry2=(["id"]=101 ["name"]="liming" ["age"]=20) echo "获取arry2中key为id对应的value:" ${arry1["id"]} echo "获取arry2中所有元素:" ${arry1[@]}
declare设置变量属性:declare [+/- aArixf] 变量名=变量值
三、shell运算符
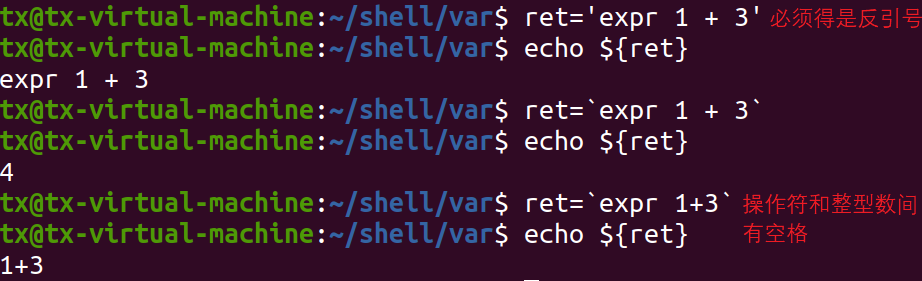
1、expr求值表达式
result=`expr 1+5`
read -p "please input first num:" a read -p "please input second num:" b echo "first num is:${a}" echo "second num is:${b}" echo "a+b=`expr $a + $b`" echo "a-b=`expr $a - $b`" echo "a*b=`expr $a \* $b`" echo "a/b=`expr $a / $b`" echo "a%b=`expr $a % $b`"
2、比较运算符
整数比较,假设a=1;b=2
| 运算符 | 说明 | 举例 |
| -eq | 判断两边的数是否相等,相等返回0,不等返回1 | [ $a -eq $b ] 返回1 |
| -ne | 判断两边的数是否不相等,不相等返回0,相等返回1 | [ $a -ne $b ] 返回0 |
| -gt | 判断左边是否大于右边 | [ $a -gt $b ] 返回1 |
| -lt | 判断左边是否小于右边 | [ $a -lt $b ] 返回0 |
| -ge | 判断左边是否大于等于右边 | [ $a -ge $b ] 返回1 |
| -le | 判断左边是否小于等于右边 | [ $a -le $b ] 返回0 |
字符串比较,a="abc";b="ab"
| 运算符 | 说明 | 举例 |
| ==/= | 判断两个字符串是否相等 |
[[ $a == $b]] [ $a == $b ] |
| > | 判断左边边是否大于右边 |
[[ $a > $b ]] [ $a \> $b ] |
| < | 判断左边是否小于右边 |
[[ $a < $b ]] [ $a \< $b ] |
| != | 判断两个字符串是否不相等 |
[[ $a != $b ]] [ $a != $b ] |
| -z | 字符串长度是否为0 | [ -z $a ] |
| -n | 字符串长度是否不为0 | [ -n $a ] |
3、布尔运算符
| 符号 | 说明 | 举例 |
| ! | 非运算。取反 | [ ! 表达式 ] |
| -o | 或运算,一方为真,则为真 | [ 表达式1 -o 表达式2 ] |
| -a | 与运算 | [ 表达式1 -a 表达式2 ] |
4、逻辑运算符
| 符号 | 说明 | 举例 |
| && | 逻辑AND | [[ 1>2 && 1 == 1 ]] 返回1 |
| || | 逻辑 OR | [[ 1>2 || 1 == 1 ]] 返回0 |
| ! | 逻辑非 | [[ ! 1>2 ]] 返回0 |
5、文件检测运算符
| 符号 | 说明 | 举例 |
| -d file | 检测文件是否是目录,返回true或者fasle | [ -d $file ] |
| -f file | 检测文件是否是普通文件,返回值同上 | [ -f $file ] |
| -r file | 检测文件是否可读,返回值同上 | [ -r $file ] |
| -w file | 检测文件是否可写 | [ -w $file ] |
| -x file | 检测文件是否可执行 | [ -x $file ] |
| -e file | 检测文件是否存在 | [ -e $file ] |
| -s file | 文件是否为空,如果文件大小不为空(size>0)返回true | [ -s $file ] |
四、shell计算命令
1、expr表达式求值
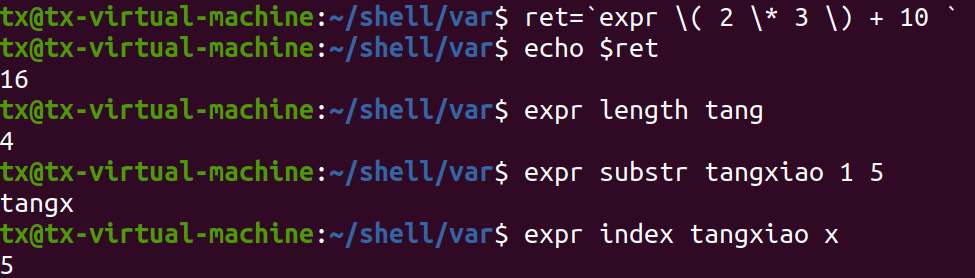
1)expr length 字符串;求字符串的长度;
2)expr substr 字符串 start end ;截取字符串
#返回 hello expr substr hellokitty 1 5
3)获取第一个字符在字符串中的出现位置:expr index 字符串 字符
#输出5 expr index hellokitty o
2、(())
1)括号内赋值:((a=1+2))
2)括号外赋值:b=$((a+2))
3)多表达式赋值:((c=a+b,d=1+3,e=c+2))
4)与if条件配合使用:if ((a==b || a==c))
3、let用于赋值操作
let a=1+2
let b = 1+2 c= 1+3
4、$[]与(())、let类似,只能进行整数运算。$[]只能对单个表达式的计算求值和输出
a=$[1+1]
b=$[a+1]
echo "$[a+b]"
五、控制语句
1、if...else语句
if [ 条件1 ]
then
命令1
elif [ 条件2 ]
then
命令2
else
命令3
fi
2、case
case 值 in 匹配模式1) 命令 ... ;; 匹配模式2) 命令 ... ;; *) 命令 ... ;; esac
3、while
while 条件 do 命令1 命令2 ... continue; #结束本次循环,进入下一次循环 break; #跳出循环 done
4、until
#条件为false才进入循环 until 条件 do ... done
5、for
#var是循环变量,item是循环的范围 for var in item1 item2 ... itemN do ... done
另外一种for循环
for((i=0;i<10;i++)) do echo "hello${i}" done
无限循环
for((;;));do 命令...;done
6、select
select var in menu1 menu2 ... do 命令 done
select 是无线循环,输入空或者输入无效值都不能结束循环,知道遇到break才结束循环。
终端输入#?表示可以输入选择的菜单编号。
一个demo
1 #! /bin/bash 2 echo "please input your hobby" 3 select hobby in "shell coding" "reading" "basketball" "delicious food" 4 do 5 case $hobby in 6 "shell coding") 7 echo "good boy" 8 break 9 ;; 10 "reading") 11 echo "Excellent people" 12 break 13 ;; 14 "basketball") 15 echo "good for health" 16 break 17 ;; 18 *) 19 echo "???" 20 esac 21 done
六、系统函数
1、basename系统函数,根据给出的文件路径获取文件名。
basename ~/ex/shell/select.sh
输出 select.sh
basename ~/ex/shell/select.sh .sh
输出select
2、dirname系统函数,根据给出的文件路径取除文件名,取出路径。
dirname ~/ex/shell/var/demo.sh
输出/home/tx/shell/var
3、自定义函数
函数名() { 函数体 } #函数调用 函数名 参数1 参数2 参数3.....
f1(){ #$0获取文件名 echo $0 #$1获取函数第一个参数 echo $1 #$2获取函数第二个参数 echo $2 return 1; } #$0获取文件名 echo $0 #$1获取文件的第一个输入参数 echo $1 #$2获取文件的第二个输入参数 echo $2 #给函数传参 f1 aa bb
函数与shell程序的区别:shell 程序运行时会开启一个子进程,函数是在当前shell进程中运行,不会开启子进程。
七、文件重定向
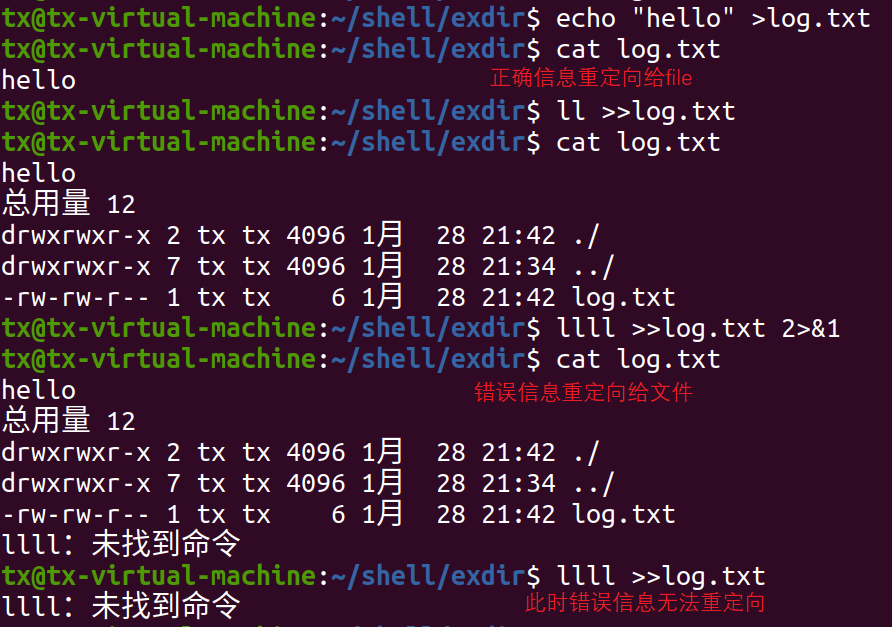
| 命令 | 说明 |
| cmd>file | 将正确的输出重定向到file中,会覆盖原有数据 |
| cmd>>file | 将正确的输出重定向到file中,以追加方式 |
| cmd >>file 2>&1 | 正确输出和错误输出都重定向到file中 |
| cmd <file | 从file中读取数据 例如:wc-l log.txt |
八、shell好用的工具
1、cut切割提取指定列/字符/字节的数据。
语法
cut [options] filename
options参数说明
| 选项参数 | 功能 |
| -f 提取范围 | 列号,获取第几列 |
| -d 自定义分隔符 | 自定义分隔符 |
| -c 提取范围 | 以字符为单位进行分割 |
| -b 提取范围 | 以字节为单位进行分割,与-n连用 |
| -n | 与-b连用,不分割多字节字符 |
提取范围说明
| 提取范围 | 说明 |
| n- | 提取指定第n列/字节/字符后面所有的数据 |
| n-m | 提取指定第n列/字符/字符到第m列/字符/字符中间的所有数据 |
| -m | 提取指定第m列/字节/字符之前的所有数据 |
demo1
原始数据
10001 liming 陕西
10002 jenny 湖南
10003 denny 西雅图
获取第一列数据:cut filename -d " " -f 1
获取第二列数据:cut filename -d " " -f 3
获取第一列数据:cut filename -d " " -f 5
获取前两个字符:cut filename -c 1-2
切割出“jenny” :cat filename | grep "jenny" | cut -d " " -f 3
2、sed
stream editor (流编辑器)是非交互式流式文本编辑器,可以对文本文件的每一行数据匹配查询之后进行增、删、改、查等操作。
sed数据处理工作原理
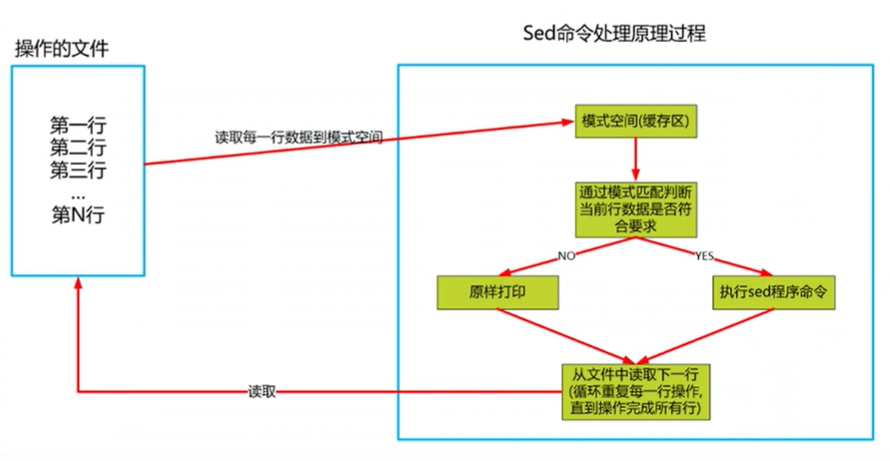
语法
#只有符合模式匹配的数据才执行sed命令 sed [options] [模式匹配/sed程序命令] [文件名]
sed命令
| 命令 | 功能描述 |
| a | 向匹配行后面添加数据 |
| i | 向匹配行前面插入数据 |
| d | 删除匹配行的数据 |
| c | 更改匹配行的内容 |
| s | 替换匹配行内容 |
| p | 打印出匹配的内容,与选项-n连用 |
| n | 读取下一行,遇到n会自动跳入下一行 |
| = | 打印被匹配行的行号 |
实战:
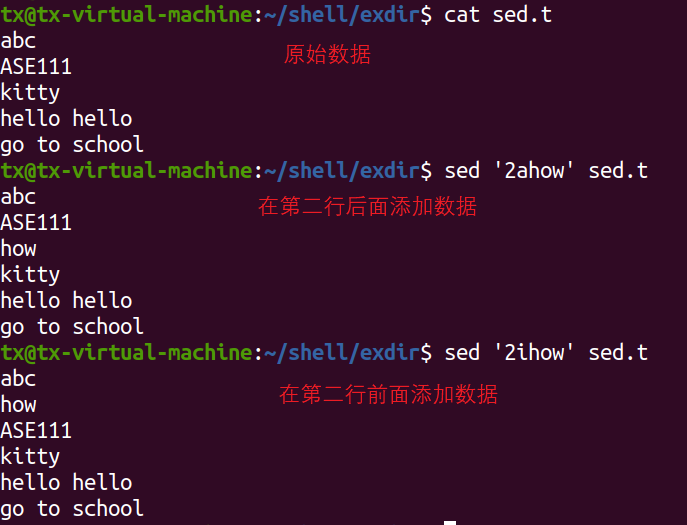
1)向文件中添加数据
向指定行号的前或者后添加数据
sed '2ahow' sed.txt sed '2ihow' sed.txt
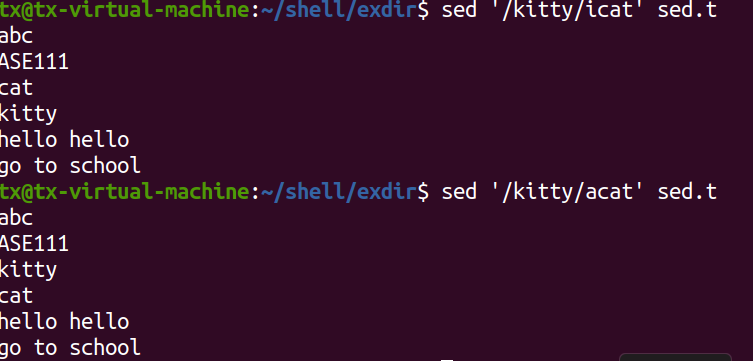
向指定内容前或者后添加数据
sed '/kitty/acat' sed.txt sed '/kitty/icat' sed.txt
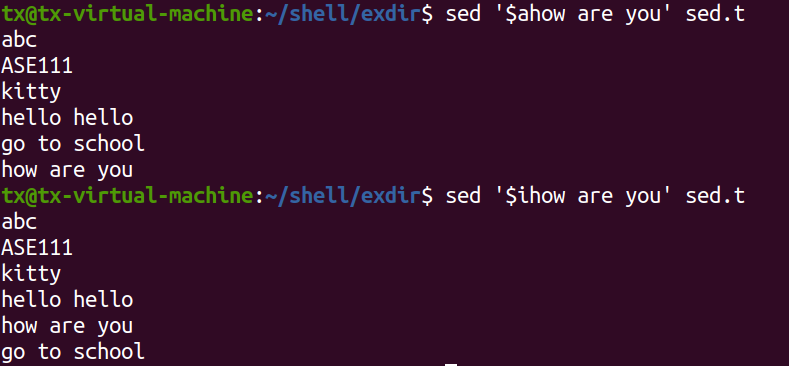
在最后一行前或者后添加数据
sed '$ahow are you' sed.txt sed '$ihow are you' sed.txt
2)删除文件中的数据
#删除第二行 sed '2d' sed.txt #删除奇数行。从第一行开始,每隔两行 sed '1~2d' sed.txt #删除从第一行到第三行数据 sed '1,3d' sed.txt #删除最后一行 sed '$d' sed.txt #删除匹配“hello”的行 sed '/hello/d' sed.txt #删除匹配行到最后一行 sed '/hello/,$d' sed.txt #删除匹配行及后面一行 sed '/hello/,+1d' sed.txt #删除不匹配的行,除kitty ,hello之外全部删除 sed '/kitty\|hello/d' sed.txt
3)更改文件中的数据
#文件中的第一行改为“ABC" sed '1cABC' sed.txt #将包含hello的行改为world sed ‘/hello/cworld’ sed.txt #将最后一行改为GO TO SCHOOL sed '$cTO GO SCHOOL' sed.txt #将hello替换为HELLO,默认只替换每一行的第一个 sed 's/hello/HELLO' sed.txt #将所有hello替换为HELLO sed 's/hello/HELLO/g' sed.txt #替换每一行的第2个hello sed 's/hello/HELLO/2' sed.txt #将替换后的内容写入文件 sed 's/hello/HELLO/2w sed2.txt' sed.txt #只打印修改的行 sed -n 's/hello/HELLO/2p' sed.txt #每行末尾拼接一个test sed 's/$/& test/' sed.txt #每行行首添加一个”#“ sed 's/^/$#/' sed.txt
4)查询
#查询含有kitty的行数据 sed -n '/kitty/p' sed.txt #查询所有bash进程 ps aux | grep bash ps aux | sed -n '/bash/p' #执行多个命令,删除第一行数据并替换hello sed -e '1d' -e 's/hello/HELLO/g' sed.txt #另外一种执行多命令 sed '1d;s/hello/HELLO/g' sed.txt
5)缓冲区数据的交换
sed处理数据是逐行处理,即读取一行处理一行输出一行。sed从文件中读出的一行存放的空间叫模式空间,此外sed还有另外一个缓冲区叫暂存空间,暂存空间刚开始里面只有一个空行。sed可通过命令从模式空间往暂存空间放入内容,或者从暂存空间中取内容放到模式空间。
| 命令 | 含义 |
| h | 将模式空间的内容放入暂存空间,以覆盖方式 |
| H | 将模式空间的内容放入暂存空间,以追加方式 |
| g | 将暂存空间的内容放入模式空间,以覆盖方式 |
| G | 将暂存空间的内容放入模式空间,以追加方式 |
| x | 交换两个空间的内容 |
例题1,将第一行数据粘贴到最后一行
思路:将模式空间中的第一行数据放入暂存空间,一覆盖方式,再从暂存空间把数据放入模式空间,以追加方式。
sed '1h;$G' sed.txt
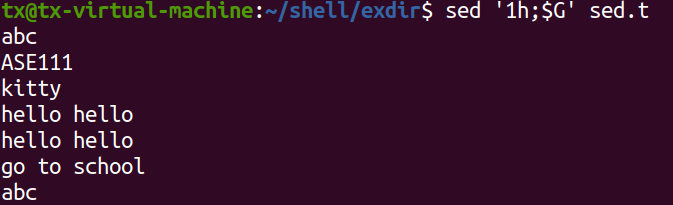
例题2,将第一行数据复制粘贴到其他行
思路:将模式空间中的第一行数据放入暂存空间,以覆盖方式,然后再从暂存空间把数据放入模式空间中替换其他行的数据,以覆盖方式
sed '1h;2,$g' sed.txt
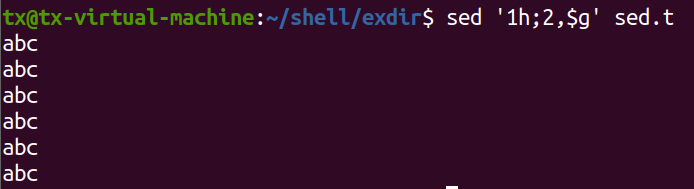
例题3,将前三行数据复制粘贴到最后一行。
sed '1,3H;$G' sed.txt
例题4,给每一行添加空行
#-i表示反应到文件本身 sed -i 'G' sed.txt
例题5,删除空行
sed -i '/^$/d' sed.txt
3、awk
一种文本分析工具,awk把文件逐行读入,以空格为默认分隔符将每行切片,切出的部分可以进行各种分析处理。
语法:awk options '匹配模式{命令}' filename
参数说明:
| 选项参数 | 功能 |
| -F | 自定义分隔符 |
| -v | 赋值一个用户定义变量 |
awk内置变量
| 内置变量 | 含义 |
| ARGC | 命令行参数个数 |
| ARGV | 命令行参数排列 |
| FILENAME | awk浏览的文件名 |
| NF | 根据分隔符分割后的列数 |
| NR | 行号 |
| $n | $0指整行记录,$1当前行的一列,$2指当前行的第二列..... |
| $NF | 最后一列信息 |
#打印/etc/passwd第二行数据 awk -F: 'NR==2{printf("文件名:%s,行号:%s,内容:%s\n",FILENAME,NR,$0)}' passwd_copy #查找以a开头的数据 ls -a| awk '/^a/' #打印第一列 awk -F: '{print $1}' passwd_copy #打印最后一列 awk -F: '{print $NF}' passwd_copy #打印倒数第二列 awk -F: '{print $(NF-1)}' passwd_copy #打印10到15行的第1列 awk -F: '{if(NR>=10&&NR<=15){print $1}}' passwd_copy #多分割符 acho "123:asd/lli"| awk -F '[:/]' '{print $1}'
#在文件头尾添加内容 echo -e "abc\nabc" | awk 'BEGIN{print "----开始----"}{print$0}END{print "---结束---"}' #使用循环拼接分割后的字符串 echo "liming jenny denny" | awk -v str="" '{for(n=1;n<=NF;++n){str=str$n} END{print str}}' #进行运算 echo "2.2" | awk '{print $0+1}' #获取ip #inet 192.168.31.119 netmask 255.255.255.0 broadcast 192.168.31.255 #方式1: ifconfig | awk '/broadcast/{print $0}'| awk '{print $2}' #方式2,先指定第二行 ifconfig | awk 'NR==2{print $0}'| awk '{print $2}'
4、sort
将文件进行排序,并将排序结果标准输出或者重定向输出到指定文件。
语法:sort options file
| 选项 | 说明 |
| -n | 安装数值大小排序 |
| -r | 以相反顺序排序 |
| -t 分割字符 | 指定排序时所用的分隔符 |
| -k | 指定需要排序的列 |
| -o | 将排序后的结果存入指定文件 |
sort对字符串升序或者降序
sort -kstart,end file
sort -kstartr,end file
sort对数字升序或者降序
sort -kstartn,end file
sort -kstartnr,end file

