STL源码分析(二)
各个容器的iterator的iterator_category
vector迭代器的iterator_category是random_access_iterator_tag,支持随机访问,deque和vector一样;
list迭代器的iterator_category是bidirectional_iterator_tag,支持双向移动,set、map也一样;
unordered_set和unordered_map底层是hash table,iterator_category是farward_iterator_tag,支持单向移动。
算法需要知道各个容器的iterator的iterator_category,以便算法选择一条最优的方法。
acculate算法分析
acculate算法使用:
class myfunc1{ public: int operator()(int a,int b){ return a +2* b; } }; int myfunc2(int a, int b) { return a + 3 * b; } void test02() { vector<int>v; for (size_t i = 0; i < 10; i++) { v.push_back(i); } cout << accumulate(v.begin(), v.end(), 100, myfunc2) << endl; //235 cout << accumulate(v.begin(), v.end(), 100, myfunc1()) << endl; //190 cout << accumulate(v.begin(), v.end(), 100) << endl;//145 }
accumulate源码,有两个版本,根据传进来的参数决定走哪个版本
//参数4为空,默认做累加操作 template<class InputIterator,class T> T accumulate(InputIterator first,InputIterator last,T init) { for(;first!=last;++first) init=init+*first; return init; } //参数4传入自定义函数或者仿函数 template<class InputIterator,class T,class BinaryOperation> T accumulate(InputIterator first,InputIterator last,T init,BinaryOperation binary_op) { for(;first!=last;++first) init=binary_op(init+*first); return init; }
for_each算法

C++11还有一种遍历容器的简单方式
vector<int>v; v.push_back(2); v.push_back(3); v.push_back(7); //for_each(v.begin(), v.end(), func()); for (int i: v) { cout << i << " "; }
replace和replace_if算法
算法使用
class Greater20{ //谓词 public: bool operator()(int val){ return val >=20; } }; vector<int >v; v.push_back(20); v.push_back(30); v.push_back(10); v.push_back(20); v.push_back(50); cout << "替换前" << endl; for_each(v.begin(), v.end(), myprint); cout << endl; cout << "替换后" << endl; replace(v.begin(), v.end(), 20, 100); //把容器中所有值为20的替换为100; replace_if(v.begin(), v.end(), Greater20(),2000); //把容器中大于20的替换为2000
算法源码,很简单
template<class ForwardIterator,class T> void replace(ForwardIterator first,ForwardIterator last,const T&old_value,const T&new_value) { for(;first!=last;++first) if(*first==old_value) *first=new_value; } template<class ForwardIterator,class Predicate,class T> void replace_if(ForwardIterator first,ForwardIterator last,Predicate pred,const T&new_value) { for(;first!=last;++first) if(pred(*frist)) *first=new_value; }
binary_search用于查找某个元素是否存在,前提是有序序列
仿函数
为算法服务。当用户要求算法有一些独特的准则的时候,比如说排序,算法默认是从小到大,如果我们想要从大到小排序,则需要提供仿函数。算法一般有两个版本,默认版本(没有仿函数),第二版本(有仿函数),编译器会选择正确的版本。仿函数是六大部件中最简单的,也是可以自己写这样的函数融入到标准库中的去的。
标准库有三大类仿函数,一共24个,以下列举了几个
算术类
template<class T> struct plus:public binary_function<T,T,T> { T operator()(const T&x,const T&y)const {return x+y;} }; template<class T> struct minus:public binary_function<T,T,T> { T operator()(const T&x,const T&y)const {return x-y;} };
相对关系类
template<class T> struct equal_to:public binary_function<T,T,bool> { bool operator()(const T&x,const T&y)const {return x==y;} }; template<class T> struct less:public binary_function<T,T,bool> { bool operator()(const T&x,const T&y)const {return x<y;} };
逻辑类
template<class T> struct logical_and:public binary_function<T,T,bool> { bool operator()(const T&x,const T&y)const {return x&&y;} };
这些标准库中所提供的仿函数,都有继承关系,继承于(binary_function)
template<class Arg1,class Arg2,class Result> struct binary_function { typedef Arg1 first_argument_type; typedef Arg2 second_argument_type; typedef Result result_type; };
由此可见,他们继承父类一堆typedef。而自定义仿函数往往没有这个继承关系,如果没有继承关系,就表明没有真正融入STL中,自定义的仿函数就没有办法被适配,解决办法就是继承相应的父类。这些仿函数被适配器来改造的时候会被问到typedef定义的东西,类似于算法去问迭代器中的五大特性。
适配器
根据适配器要去改造的对象命名为相应的迭代器,对容器改造就称为容器迭代器,对仿函数改造就称为仿函数迭代器。继承
一切适配器都有一个共性:当A去改造B,A就代表了B,A所做的事情都有B代劳,A是用户和B之间的桥梁,适配方式有两种:一种是A继承B,另外一种也是最常见的,A内含有B,比如stack和queue,并没重新定义这个两个类,而是他们中内含有deque,通过关闭deque的某些功能改造成了stack和queue。容器迭代器就说明内含有一个容器,仿函数迭代器内存有一个仿函数。
函数适配器,count_if举例

迭代器适配器
1、逆向迭代器,以连续空间容器的迭代器为例
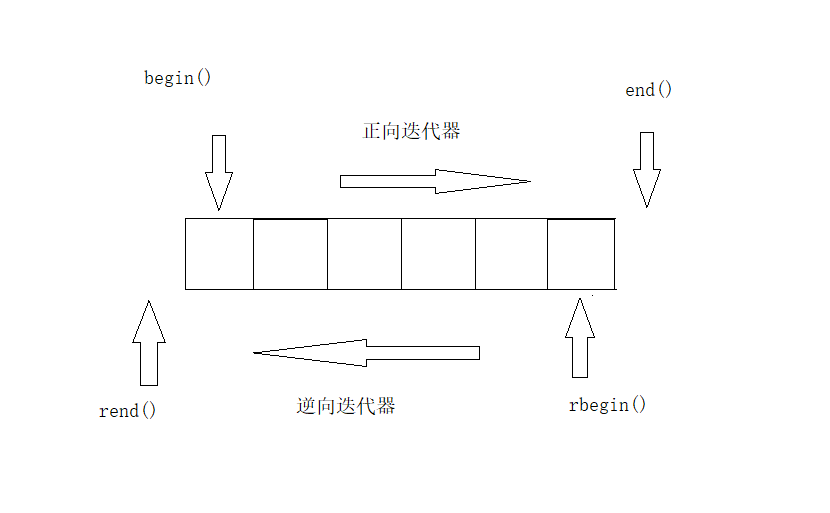
以下是用户使用的逆向迭代器
void test02() { vector<int>v; v.push_back(1); v.push_back(2); v.push_back(3); v.push_back(4); v.push_back(5); vector<int>::reverse_iterator it = v.rbegin(); //逆向迭代器it指向5 it++;//it指向4 cout << *(it.base()) << endl;//取出对应的正向迭代器,指向5 cout << *(it + 3) << endl;//it指向1 }
源码
//结合上面例子 reverse_iterator rbegin() { return reverse_iterator(end()); } template <class Iterator> class reverse_iterator { protected: Iterator current; //正向迭代器 public: typedef typename iterator_traits<Iterator>::iterator_category iterator_category; ... //五种特性 typedef Iterator iterator_type; //正向迭代器类型 typedef reverse_iterator<Iterator> self //逆向迭代器类型 public: //构造函数 explicit reverse_iterator(iterator_type x):current(x){} reverse_iterator(const self &x):current(x.current){} iterator_type base() const { return current;} reference operator*() const {Iterator tmp = current; return *--tmp;}//传进来的end()指向5后面的元素 pointer operator->() const { retrun &(operator*());} self &operator++() {--current; return *this;} //逆向迭代器++,相当于正向迭代器--(此时指向5),返回值再重载*运算符(指向4) self &operator--() {++current;return *this;} self operator+(difference_type n) const { return self(current - n);} self operator-(difference_type n) const { return slef(current +n);} }
2、inserter
在l2中的所有元素拷贝到l1的指定位置
void test03() { list<int>l1; list<int>l2; for (size_t i = 1; i < 6; i++) { l1.push_back(i); l2.push_back(i + 10); } list<int>::iterator it = l1.begin(); advance(it, 3); //it向前移动3位,不能直接+3 copy(l2.begin(), l2.end(), inserter(l1, it));//1 2 3 11 12 13 14 15 4 5 }
copy源码

ostream_iterator
void test05() { vector<int>v; for (size_t i = 1; i < 6; i++) { v.push_back(i); } ostream_iterator<int> out_it(cout, ","); copy(v.begin(), v.end(), out_it); } //屏幕输出 1,2,3,4,5,
hashfunction
hashfunction是把元素转换成hashcode,得到的hashcode值越乱越好。当元素是基本数据类型时,编译器中有现成的hashfunction,除了字符型元素,其他类型元素,hashcode就是他本身。如果元素是个自定义数据类型,编译器不知道怎么计算hashcode,这时候需要用户设计一个hashfunction。

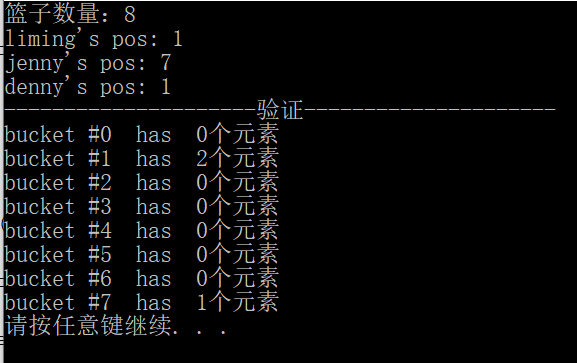
#include<iostream> #include<functional> #include<unordered_set> using namespace std; class PersonHash; class Person { friend PersonHash; public: Person(int num, string name, int age) : m_Num(num), m_Name(name), m_age(age){} int m_Num; string m_Name; int m_age; }; template<typename T> //当拆分到最后一个元素 inline void hash_val(size_t&seed, const T&val) { hash_combine(seed, val); } template<typename T> inline void hash_combine(size_t &seed, const T&val) { //改进版的hashfunction seed = seed^hash<T>()(val)+0x9e3779b9 + (seed << 6) + (seed >> 2); } //2、 接受seed和其他三个参数 template<typename T, typename ...Types> //分出的第一个参数和其他两个参数 inline void hash_val(size_t &seed, const T &val, const Types &...args) { hash_combine(seed, val);//种子和num 得到一个code hash_val(seed, args...);//种子和其他两个参数,递归 } //1、接受所有参数 template <typename ...Types> inline size_t hash_val(const Types &...args) { size_t seed = 0; hash_val(seed, args...); return seed; } class PersonHash { public: std::size_t operator()(const Person& p) const { return hash_val(p.m_Num, p.m_Name, p.m_age); } }; //需要指定比较规则 struct eqstr { bool operator()(Person p1, Person p2) const { return (p1.m_Num == p2.m_Num); } }; int main() { Person p1(1001, "liming", 15); Person p2(1002, "jenny", 16); Person p3(1003, "denny", 18); unordered_set<Person, PersonHash,eqstr> set; set.insert(p1); set.insert(p2); set.insert(p3); cout << "篮子数量:" << set.bucket_count() << endl; PersonHash hh; cout << "liming's pos: " << hh(p1) % 8 << endl; cout << "jenny's pos: " << hh(p2) % 8 << endl; cout << "denny's pos: " << hh(p3) % 8 << endl; cout << "---------------------验证---------------------" << endl; for (size_t i = 0; i < set.bucket_count(); i++) { cout << "bucket #" << i << " has " << set.bucket_size(i) <<"个元素"<< endl; } system("pause"); }
打印结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号