
day01先睹为快(中)
根据day01先睹为快(上)的个格式化文本结构,是可以解决人员管理的问题,但是存在以下局限性:
- 获取一条数据,也需要重新从文件中读取整数据库
- 每次更新一个数据,也需要从整个文件中读取,然后重新写入文件,当数据量多的时候,局大大制约了程序的效率
- 写入文件是和加载过程中如果存在分隔符“==>”就会使得程序崩溃
于是引入pickle模块,将内存中的python对象转换成序列化的字节流,可以写入任何类似文件对象的字节串;也可以根据序列化的自救刘重新构成内存中的对象。
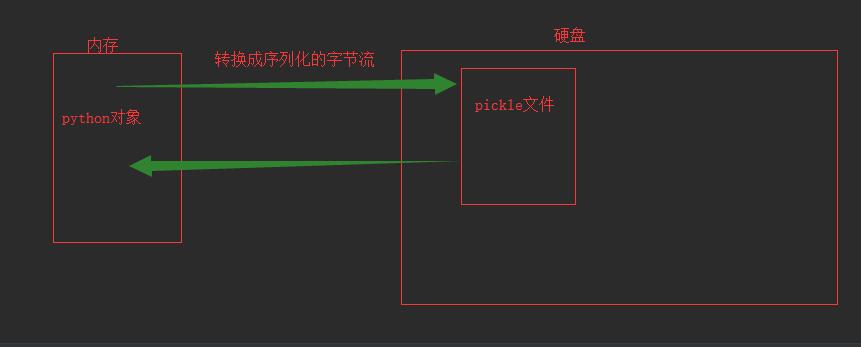
1、创建make_db_pickle.py文件,将字典对象转换成序列化的字节流信息保存到文件
1 from initdata import db 2 import pickle 3 4 dbfile=open("people_pickle","wb") #创建一个文件对象 以字节流的形式写入文件 5 pickle.dump(db,dbfile) #将对象转换成序列化的字节流 保存在people_pickle文件当中 6 7 dbfile.close()
运行make_db_pickle.py文件后在指定的路径下创建一个people_pickle文件,将字典对象转换成字节流存储
2、创建dump_db_pickle.py文件,将字节流信息加载到字典对象
1 import pickle 2 3 dbfile=open("people_pickle","rb") #打开文件 4 db=pickle.load(dbfile) #加载字节流 将字节流转换成字典对象 5 6 for key in db: 7 print(key,"==>",db[key]) 8 9 print(db["yw"]["name"])
3、创建update_db_pickle.py 更新数据
1 import pickle 2 3 # 从文件中加载数据 4 dbfile=open("pickle_people","rb") 5 db=pickle.load(dbfile) 6 dbfile.close() 7 8 """ 9 对字典进行修改 10 """ 11 db["yw"]["name"]="甄子丹" 12 db["yw"]["age"]=56 13 14 # 将数据重新写入到pickle文件当中 15 dbfile=open("pickle_people","wb") 16 pickle.dump(db,dbfile) 17 dbfile.close()
以上也可以实现相应的功能,但是也存在一个缺陷,处理文件叫大的时候,数据库变的很慢,因为每当更新一条数据就需要读出和写入整个数据库
改进办法 对数据库中每一条记录都写到一个普通文件当中 为每一条记录使用一个pickle文件
1)创建一个make_db_pickle_recs.py 将的每条记录写入到文件当中
1 from initdata import db 2 import pickle 3 4 for key,value in db.items(): # 获得数据库中字典及其数据 5 refile=open("dbfile/"+key+".pkl","wb") 6 pickle.dump(value,refile) 7 refile.close()
模块介绍 glob模块中的glob("*.pkl") 根据文件的扩展名,获取文件家中指定文件扩展名中的所有文件
2)加载对应的文件 获得字典 创建一个dump_db_pickle_recs.py
1 import pickle,glob 2 3 for filename in glob.glob("dbfile/*.pkl"): 4 recfile=open(filename,"rb") 5 record=pickle.load(recfile) 6 print(filename,record) 7 recfile.close() 8 9 bobfile=open("dbfile/bob.pkl","rb") #根据的文件 加载相应的字典 10 bob=pickle.load(bobfile) 11 print(bob) 12 bobfile.close()
