



sql之透视
1、透视原理:就是将查询结果进行转置
下面就举例来说明:
执行下面语句:检查是否含有表 dbo.Orders,如果有就将表删除:
1 if OBJECT_ID('dbo.Orders','U') is not null 2 drop table dbo.Orders
然后创建表dbo.Orders:
1 create table dbo.Orders 2 ( 3 orderid int not null primary key, 4 empid int not null, 5 custid int not null, 6 orderdate datetime, 7 qty int 8 )
批量插入数据:
1 insert into dbo.Orders (orderid,orderdate,empid,custid,qty) values 2 (30001,'20070802',3,1,10), 3 (10001,'20071224',2,1,12), 4 (10005,'20071224',1,2,20), 5 (40001,'20080109',2,3,40), 6 (20001,'20080212',2,2,12), 7 (10006,'20080118',1,3,14), 8 (40005,'20090212',3,1,10), 9 (20002,'20090216',1,3,20), 10 (30003,'20090418',2,2,15), 11 (30004,'20070418',3,3,22), 12 (30007,'20090907',3,4,30)
业务逻辑:查询出 每个 员工 处理的 每个客户的 订单总数
普通的查询方式:
select empid,custid,SUM(qty) as sumqty from Orders group by empid,custid order by empid
查询结果:
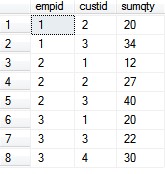
但是现在想要的结果是:
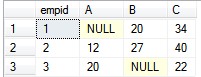
其中的A、B、C分别代表三个 客户Id,需要将原来的结果进行转置。
实现上面的结果就是sql里面的透视:
三个步骤:
1、将结果数据进行分组
2、将结果数据进行扩展
3、将结果数据进行聚合
第一种是实现方式:复杂、简单易懂的方式:使用相关子查询:
1 select 2 empid, 3 --下面是相关子查询,不是表的连接 4 ( 5 select 6 SUM(qty) 7 from Orders as innerO 8 where innerO.empid=outerO.empid and custid=1 9 group by innerO.empid 10 ) as A , 11 ( 12 select 13 SUM(qty) 14 from Orders as innerO 15 where innerO.empid=outerO.empid and custid=2 16 group by innerO.empid 17 ) as B , 18 ( 19 select 20 SUM(qty) 21 from Orders as innerO 22 where innerO.empid=outerO.empid and custid=3 23 group by innerO.empid 24 ) as C 25 from Orders as outerO 26 group by empid
第二种实现方式:使用组函数的特殊用法:
1 --简单方式 :使用sum()函数的特殊用法:在方法里面,添加 case语句 2 select 3 empid, 4 SUM(case when custid=1 then qty end) as A,--这样 将已经对empid 进行了限制 5 SUM(case when custid=2 then qty end) as B, 6 SUM(case when custid=3 then qty end) as C, 7 SUM(qty) as sumqty 8 from Orders 9 group by empid
第三种方式:使用pivot,是 sql server 特有的,在oracle里面没有:
1 select 2 empid,[1],[2],[3] 3 from 4 ( 5 --仅仅查询出 在 透视 里面需要用到的数据 6 select 7 empid,custid,qty 8 from Orders 9 ) as t --在这里已经对数据 进行了分组 10 pivot 11 ( 12 sum(qty) --聚合函数 (对那个列 执行 组函数) 13 for custid in ([1],[2],[3])-- (对那些数据进行了聚合运算) 这里的数字一定要 加[]因为 14 ) as p
这种 使用 sql server 里面内置的 pivot 的方法,肯定是比上面两种自己写的方法的效率高。

