Python基础第十天——yield的表达式形式的应用、面向过程编程、内置函数
鸡汤:
首先,我一定要怀着一颗感恩的心,感谢这个世界上与我接触的人,不管你们对我是关心、是帮助、是冷漠、甚至是厌恶,我都感谢你们。
因为关心和帮助让我感受到了对爱的希望,
因为冷漠和厌恶让我感悟到了人生的残酷,
让恨的力量与爱的力量化作一股源源不断的的动力,驱使我在这条未知的漫漫人生道路上写下胜利的凯歌!
——奔跑吧小白
一、yield的表达式形式的应用
1、yield的表达式形式应用的定义:
在一个生成器函数内,将yield赋值给一个变量,这就是yield的表达式形式。也叫生成器的表达式形式。
2、send方法的定义:
(1)定义:
yield的表达式形式下面有一个send方法,它的作用与next方法是一样的,都是在触发函数继续往下走。除了具有next的功能外,还具有传值的效果。send传值的的方式是先把要传的值交给yield,再由yield赋值给事先定义的变量名,最后才触发next效果。
(2)补充:
send(None):把None传给yield,相当于不传值,只有next效果。等同于“next(生成器变量)”,一般用于生成器表达形式的初始化操作。
3、yield表达式形式的初始化
定义:
生成器一定要走到一个暂停的位置,然后才能send传值,因为send的特性是基于一个已经暂停的yield进行传值然后再接着往下走。
如果对生成器表达式形式不进行初始化操作而直接进行传值则会报以下错误:
TypeError: can't send non-None value to a just-started generator(不能将非None值发送到刚启动的生成器)
解决方法:所以必须先send一个None给生成器表达式形式或next(g)
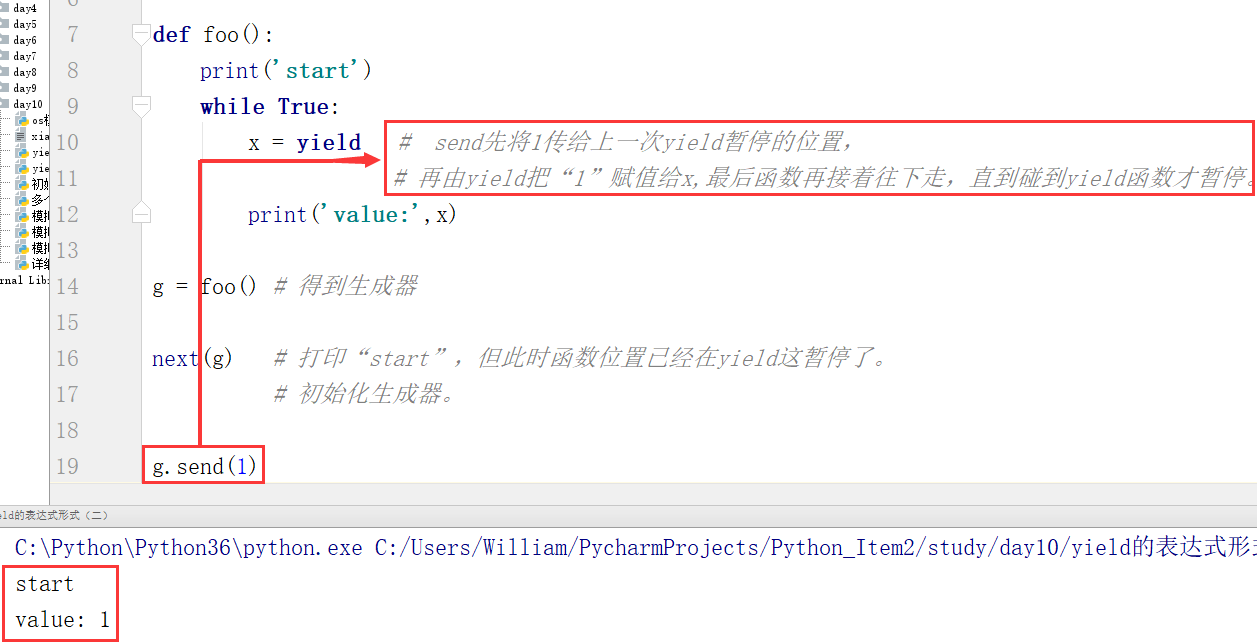
例1:
注意:先传一个None给生成器,否则直接报错
def foo():
print('start')
while True:
x = yield
print('value:',x)
g = foo() # 得到生成器
print(g.send(None)) # g.send(None)一般用于初始化生成器。
# 它传了一个空值给函数,相当于直接执行了next(g)
# 如果不初始化则会报以下错误:
# TypeError: can't send non-None value to a just-started generator
print('---------------------------')
print(g.send(1)) # 先将数字1传给yield,,再执行next(g),所以打印函数返回值的结果还是None。
print('---------------------------')
print(g.send(2)) # 先将数字2传给yield,,再执行next(g),所以打印函数返回值的结果还是None。
print('---------------------------')
print(next(g))
输出结果:


start None --------------------------- value: 1 None --------------------------- value: 2 None --------------------------- value: None None
例2:
要求:用装饰器写一个实现初始化生成器的功能
这样得的生成器是经过初始化后的生成器。
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
@init
def foo():
print('start')
while True:
x = yield
print('value:',x)
g = foo() # 得到生成器,此时的g生成器则是经过初始化生成器后的g。
print('---------------------------')
print(g.send(1)) # 先将数字1传给yield,,再执行next(g),所以打印函数返回值的结果还是None。
print('---------------------------')
print(g.send(2)) # 先将数字2传给yield,,再执行next(g),所以打印函数返回值的结果还是None。
print('---------------------------')
print(next(g))
例3:
用代码模拟吃货来说明生成器表达形式的作用。
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
@init
def eater(name):
'''定义一个吃货'''
print('%s is ready to eat'%name)
while True:
food = yield # (此时的yield后面没有跟任何值,所以是返回的None)可以通过外面给yield传值,再把传进来的值赋值给变量food
print('%s began to eat %s'%(name,food))
e = eater('xiaobai') # 得到生成器。传一个吃货小白进去
# 开始给吃货传食物
e.send('包子')
e.send('面条')
e.send('饺子')
e.send('馒头')
e.send('烧饼')
e.send('蛋炒饭')
e.send('花卷')
print('吃这么多,妈的快撑死我了......')
输出结果:
xiaobai is ready to eat xiaobai began to eat 包子 xiaobai began to eat 面条 xiaobai began to eat 饺子 xiaobai began to eat 馒头 xiaobai began to eat 烧饼 xiaobai began to eat 蛋炒饭 xiaobai began to eat 花卷 吃这么多,妈的快撑死我了......
要求:将以上代码进行修改。每次去饭馆吃饭时候都有一个菜单,所以我们在这里用代码模拟出菜单功能。
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
@init
def eater(name):
'''定义一个吃货'''
print('%s is ready to eat'%name)
food_list = [] # 菜单
while True:
food = yield food_list # 返回这个菜单的列表
food_list.append(food) # 每次send传值过来添加到food_list列表里。
print('%s began to eat %s'%(name,food))
e = eater('xiaobai') # 得到生成器。传一个吃货小白进去
# 开始给吃货传食物
print(e.send('包子')) # 加上print查看返回值——得到菜单
print(e.send('面条'))
print(e.send('饺子'))
print(e.send('馒头'))
print(e.send('烧饼'))
print(e.send('蛋炒饭'))
print(e.send('花卷'))
print('吃这么多,妈的快撑死我了......')
输出结果:
xiaobai is ready to eat xiaobai began to eat 包子 ['包子'] xiaobai began to eat 面条 ['包子', '面条'] xiaobai began to eat 饺子 ['包子', '面条', '饺子'] xiaobai began to eat 馒头 ['包子', '面条', '饺子', '馒头'] xiaobai began to eat 烧饼 ['包子', '面条', '饺子', '馒头', '烧饼'] xiaobai began to eat 蛋炒饭 ['包子', '面条', '饺子', '馒头', '烧饼', '蛋炒饭'] xiaobai began to eat 花卷 ['包子', '面条', '饺子', '馒头', '烧饼', '蛋炒饭', '花卷'] 吃这么多,妈的快撑死我了.....
例4: 重点★★★★★
为了实现多个函数之间的协同工作,将例3的代码改成一个生产食物,另一个处理食物,代码如下:
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
# 吃货
@init
def eater(name):
'''定义一个吃货'''
print('%s is ready to eat'%name)
food_list = [] # 菜单
while True:
food = yield food_list # 返回这个菜单的列表
food_list.append(food) # 每次send传值过来添加到food_list列表里。
print('%s began to eat %s'%(name,food))
# 生产包子
def bun(people,n):
for i in range(n):
print(people.send('包子%s'%i)) # 此时的people就是eater生成器,加上打印功能就可以看到send的返回值,也就是菜单
# 通过send进行传值。
e = eater('xiaobai') # 得到生成器。传一个吃货小白进去
bun(e,10) # 调用时将生成器eater当作实参传到bun函数里
输出结果:
xiaobai is ready to eat xiaobai began to eat 包子0 ['包子0'] xiaobai began to eat 包子1 ['包子0', '包子1'] xiaobai began to eat 包子2 ['包子0', '包子1', '包子2'] xiaobai began to eat 包子3 ['包子0', '包子1', '包子2', '包子3'] xiaobai began to eat 包子4 ['包子0', '包子1', '包子2', '包子3', '包子4'] xiaobai began to eat 包子5 ['包子0', '包子1', '包子2', '包子3', '包子4', '包子5'] xiaobai began to eat 包子6 ['包子0', '包子1', '包子2', '包子3', '包子4', '包子5', '包子6'] xiaobai began to eat 包子7 ['包子0', '包子1', '包子2', '包子3', '包子4', '包子5', '包子6', '包子7'] xiaobai began to eat 包子8 ['包子0', '包子1', '包子2', '包子3', '包子4', '包子5', '包子6', '包子7', '包子8'] xiaobai began to eat 包子9 ['包子0', '包子1', '包子2', '包子3', '包子4', '包子5', '包子6', '包子7', '包子8', '包子9']
补充:
os模块walk方法的作用:得到一个生成器,配合__next__()递归查找文件与目录
import os
g = os.walk(r'C:\Users\William\PycharmProjects\Python_Item2\study')
# print(g) # 得到一个生成器,取值则用next()
# 第一次next
# print(next(g))
# 得到三个值,分别是当前目录,当前目录下的子目录,当前目录下的文件
# 输出结果:
'''
('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study',
['day1', 'day10', 'day2', 'day3', 'day4', 'day5', 'day6', 'day7', 'day8', 'day9'],
[],)
'''
# 如果用for循环遍历,它则会递归地查找,查找的顺序是:
# 本例在第一次next(g)后,当前目录下的所有子目录则生成了一个列表,按照列表的排序查找。
for i in g:
print(i)
输出结果:
('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study', ['day1', 'day10', 'day2', 'day3', 'day4', 'day5', 'day6', 'day7', 'day8', 'day9'], []) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day1', [], []) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day10', [], ['os模块walk方法的作用.py', 'xiaobai', 'yield的表达式形式.py', '初始化装饰器.py', '多个函数的协同工作.py', '模拟grep -rl命令.py', '模拟吃货.py', '模拟吃货(二).py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day2', [], ['for 语句的简单示例3.py', 'while循环的简单实例.py', '三次登陆.py', '九九乘法表.py', '使用while循环输出1、2、3、4、5、6、8、9、10.py', '切片.py', '查看成绩.py', '求1-100的所有数的和.py', '求1-2+3-4+5-6...99的所有数的和.py', '猜年龄.py', '用户登陆.py', '简单的用户输入命令的程序.py', '输出1-100内的所有的偶数.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day3', [], ['列表.py', '列表的循环.py', '字典的get用法.py', '用户认证.py', '链式赋值.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day4', [], ['a.copy.jpg', 'a.jpg', 'a.txt', 'b.txt', 'break的应用.py', 'c.txt', '不打乱顺序并去重.py', '文件写操作.py', '文件的修改.py', '文件追加操作.py', '用户输入命令为空的情况下让其继续输入命令.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day5', [], ['函数1.py', '函数2.py', '比较三个值中的最大值.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day6', [], ['a.txt', 'args和kwargs在一起时的作用.py', 'args和kwargs的连用2.py', 'globals的定义.py', 'test1.py', '三种名称空间的关系.py', '三种名称空间的关系2.py', '位置参数.py', '位置实参与关键字实参.py', '位置实参与关键字实参的混用.py', '全局作用域.py', '关键字参数.py', '函数对象.py', '函数常见的错误.py', '函数是第一类对象.py', '函数有return的情况.py', '函数没有return的情况.py', '函数的定义阶段.py', '函数的嵌套定义.py', '函数的嵌套调用.py', '判断用户输入的字符长度.py', '命名关键字参数.py', '命名关键字参数2.py', '命名关键字参数3.py', '增删改查功能.py', '局部作用域.py', '局部名称空间.py', '形参和实参.py', '按位置定义的实参的可变长参数args.py', '按关键字定义的实参的可变长参数kwargs.py', '默认参数.py', '默认参数2.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day7', [], ['global例子.py', 'nonlocal例子.py', '函数的作用域关系与定义有关,与调用无关.py', '多个装饰器.py', '多层闭包函数.py', '拾遗.py', '有参装饰器.py', '爬虫的雏形.py', '被装饰对象有多个且包含有参和无参函数.py', '装饰器.py', '装饰器修定版.py', '装饰器语法.py', '闭包函数.py', '闭包函数中加上nonlocal关键字.py', '非闭包函数.py', '验证闭包函数__closure__.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day8', ['cache'], ['cache.txt', 'hash值.py', 'userinfo.txt', '__iter__方法.py', '函数.py', '函数1.py', '函数注释信息的修改.py', '去重.py', '字典的特性.py', '引用全局变量.py', '有参装饰器.py', '有参装饰器(二).py', '查看函数的注释信息.py', '练习一.py', '练习三.py', '练习二.py', '练习五.py', '练习六.py', '练习六(一).py', '练习六(三).py', '练习六(二).py', '练习六(四).py', '练习四(一).py', '练习四(二).py', '迭代器.py', '闭包.py']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day8\\cache', [], ['baidu.com.txt', 'python.org.txt']) ('C:\\Users\\William\\PycharmProjects\\Python_Item2\\study\\day9', [], ['a.txt', 'for循环原理.py', 'return返回值.py', 'yield与return的区别.py', '三元表达式.py', '列表解析.py', '判断是迭代对象还是迭代器对象.py', '找出大于100的值.py', '模拟linux命令——动态查看文件并过滤文件内的功能(二).py', '模拟linux命令——动态查看文件并过虑文件内容的功能.py', '模拟tail -f命令的执行效果.py', '比较4个值中的最大值.py', '生成器.py', '生成器可以被for循环遍历.py', '生成器的取值.py', '生成器表达式.py', '用while循取不按索引的数据类型.py', '计数.py', '迭代.py', '迭代器.py', '迭代器对象.py', '迭代器执行__iter__方法得到的是自己.py', '迭代对象.py'])
例5: 重点★★★★★
模拟linux命令:grep -rl(表示递归地过滤出包含指定内容的文件名)
要求:用grep -rl命令过滤出/etc目录下包含“root”内容的文件名。(grep -rl 'root' /etc )
分析:
步骤一:递归地找文件的绝对路径,把路径发给步骤二。
步骤二:收到文件路径,打开文件获取文件对象,把文件对象发给步骤三。
步骤三:收到文件对象,再用for循环来读取文件的每一行内容。把每一行的内容发给步骤四。
步骤四:收到每一行内容。判断“root”字符串是否在每一行中。如果存在则把包含“root”的文件名发给步骤五
步骤五:收到文件名,打印结果。
代码如下:
# 要求:模拟Linux命令:grep -rl
# 准备事项:
# 由于windows系统中使用的其它字符编码,为了能更好地演示效果,现在自己创建a、b、c三个目录
# 每个目录下都创建了若干文件,但是包含字符串“root”内容的文件只有a.txt、b2.txt、c.txt这三个文件。
# 所以,如果代码正确,就会打印出以上三个文件。
import os
# 装饰器:初始化生成器功能
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
# 步骤一:递归地找文件的绝对路径,把路径发给步骤二。
# 查找绝对路径函数
def search(target,start_path): # target是opener函数的生成器,start_path则是要传入的路径
'''search file adspath'''
g = os.walk(start_path)
for par_dir,_,files in g: # 字符串的拼接操作,不需要的内容用下划线即可
# print(par_dir,files) # 得到父级目录和父级目录下的文件。
for file in files:
file_path = r'%s\%s'%(par_dir,file) # 拼接绝对路径
# print(file_path) # 打印得到绝对路径
target.send(file_path) # 拿到opener函数的生成器,再不停地对opener函数send传值
# 步骤二:收到文件路径,打开文件获取文件对象,把文件对象发给步骤三。
# 获取文件对象
@init
def opener(target): # target是cat函数的生成器
'''get file obj: f = open(filepath)'''
while True: # search函数不停地发,所以要用while True不停地收
file_path = yield # 接收search函数中send过来的值
with open(file_path,'r',encoding='utf-8') as f: # 收到步骤一send过来的值后找开文件,得到文件对象
target.send((file_path,f)) # 拿到cat函数的生成器后,再不停地向cat函数send这个路径和文件对象
# 步骤三:收到文件对象,再用for循环来读取文件的每一行内容。把每一行的内容发给步骤四。
# 读取文件内容
@init
def cat(target): # targer是grep函数的生成器
'read file'
while True: # opener函数不停地发,所以要用while True不停地收
filepath,f = yield # 接收opener函数中send过来的值:文件路径和文件
for line in f: # 把每一行内容取出来
target.send((filepath,line))# 拿到grep函数的生成器后,再不停地向grep函数send值
# 以元组的形式把文件路径和这一行内容发送给grep函数
# 步骤四:收到每一行内容。判断“root”字符串是否在每一行中。如果存在则把包含“root”的文件名发给步骤五
# 过滤功能
@init
def grep(target,pattern): # target是printer函数的生成器,
# pattern表示传进来的参数,表示用户要过滤的值,不能写死,本例要过滤的值是"root"
'''grep'''
while True: # cat函数不停地发,所以要用while True不停地收
filepath,line = yield # 接收cat函数中send过来的值,同时收到文件名和行,line(行)属于filepath(这个文件)
if pattern in line: # 判断"root"字符串是否在每一行里
target.send(filepath)# 如果是,则把收到的文件名filepath传给printer函数处理
# 步骤五:收到文件名,打印结果。
# 打印
@init
def printer():
'''print'''
while True:
filename = yield
print(filename)
start_path = r'C:\Users\William\PycharmProjects\Python_Item2\study\a'
search(opener(cat(grep(printer(),'root'))),start_path)
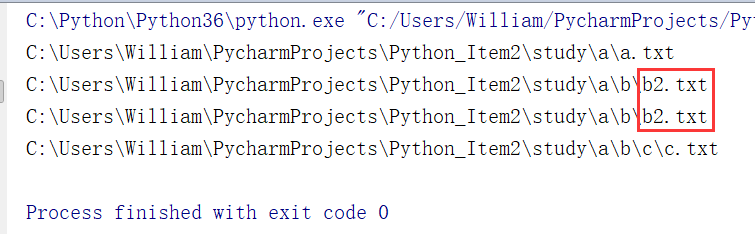
输出结果:
C:\Users\William\PycharmProjects\Python_Item2\study\a\a.txt
C:\Users\William\PycharmProjects\Python_Item2\study\a\b\b2.txt
C:\Users\William\PycharmProjects\Python_Item2\study\a\b\c\c.txt
但是以上代码还是存在BUG,假如,要查找的文件中多行包含有“root”关键字。则会出现以下情况:
例:
b2.txt文件中的两行都包含“root”关键字
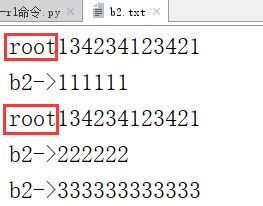
此时运行例5的代码则会出现打印两次b2.txt的文件,这就违背了题目的要求,我们的目的是只要找到包含“root”关键字的文件就打印这个文件,不管这个文件中包含多少个“root”,都只打印一次文件名。
解决思路:
一个文件,在遍历其每一行内容后进行判断,不管该文件的内容中有多少个“root”关键字,只要判断该文件内容里包含了一个"root"关键字,就立刻停止遍历并打印出这个文件名。
首先,在程序中有哪一块代码有判断找到了“root”关键字,则就从那一块代码着手。
在例5中,在步骤四——grep函数这里判断成功了,所以先从grep函数这里着手。在"if pattern in line"这里判断成功后,则不让其再遍历这个文件剩下的内容了。但是在grep函数这不能控制这个问题,是因为循环读文件的内容是由步骤三——cat函数做的事情。此时grep函数应该做的事是告诉cat函数只要找到“root”关键字,就马上停止循环。
解决方法:
# 要求:模拟Linux命令:grep -rl
# 准备事项:
# 由于windows系统中使用的其它字符编码,为了能更好地演示效果,现在自己创建a、b、c三个目录
# 每个目录下都创建了若干文件,但是包含字符串“root”内容的文件只有a.txt、b2.txt、c.txt这三个文件。
# 所以,如果代码正确,就会打印出以上三个文件。
import os
# 装饰器:初始化生成器功能
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
# 步骤一:递归地找文件的绝对路径,把路径发给步骤二。
# 查找绝对路径函数
def search(target,start_path): # target是opener函数的生成器,start_path则是要传入的路径
'''search file adspath'''
g = os.walk(start_path)
for par_dir,_,files in g: # 字符串的拼接操作,不需要的内容用下划线即可
# print(par_dir,files) # 得到父级目录和父级目录下的文件。
for file in files:
file_path = r'%s\%s'%(par_dir,file) # 拼接绝对路径
# print(file_path) # 打印得到绝对路径
target.send(file_path) # 拿到opener函数的生成器,再不停地对opener函数send传值
# 步骤二:收到文件路径,打开文件获取文件对象,把文件对象发给步骤三。
# 获取文件对象
@init
def opener(target): # target是cat函数的生成器
'''get file obj: f = open(filepath)'''
while True: # search函数不停地发,所以要用while True不停地收
file_path = yield # 接收search函数中send过来的值
with open(file_path,'r',encoding='utf-8') as f: # 收到步骤一send过来的值后找开文件,得到文件对象
target.send((file_path,f)) # 拿到cat函数的生成器后,再不停地向cat函数send这个路径和文件对象
# 步骤三:收到文件对象,再用for循环来读取文件的每一行内容。把每一行的内容发给步骤四。
# 读取文件内容
@init
def cat(target): # targer是grep函数的生成器
'read file'
while True: # opener函数不停地发,所以要用while True不停地收
filepath,f = yield # 接收opener函数中send过来的值:文件路径和文件
for line in f: # 把每一行内容取出来
res = target.send((filepath,line))# 拿到grep函数的生成器后,再不停地向grep函数send值
# 以元组的形式把文件路径和这一行内容发送给grep函数
if res:
break
# 步骤四:收到每一行内容。判断“root”字符串是否在每一行中。如果存在则把包含“root”的文件名发给步骤五
# 过滤功能
@init
def grep(target,pattern): # target是printer函数的生成器,
# pattern表示传进来的参数,表示用户要过滤的值,不能写死,本例要过滤的值是"root"
'''grep'''
tag = False
while True: # cat函数不停地发,所以要用while True不停地收
filepath,line = yield tag # 接收cat函数中send过来的值,同时收到文件名和行,line(行)属于filepath(这个文件)
tag = False
if pattern in line: # 判断"root"字符串是否在每一行里
target.send(filepath)# 如果是,则把收到的文件名filepath传给printer函数处理
tag = True
# 补充:
# 步骤五:收到文件名,打印结果。
# 打印
@init
def printer():
'''print'''
while True:
filename = yield
print(filename)
start_path = r'C:\Users\William\PycharmProjects\Python_Item2\study\a'
search(opener(cat(grep(printer(),'root'))),start_path)
输出结果:
C:\Users\William\PycharmProjects\Python_Item2\study\a\a.txt
C:\Users\William\PycharmProjects\Python_Item2\study\a\b\b2.txt
C:\Users\William\PycharmProjects\Python_Item2\study\a\b\c\c.txt
例6:
详细说明send的作用:
def init(func):
'''初始化生成器'''
def wrapper(*args,**kwargs):
g = func(*args,**kwargs)
next(g) # 初始化
return g # 将初始化后的生成器返回给原函数
return wrapper
@init
def foo():
tag = False
while True:
x = yield tag # 返回值为tag,经过程序的变化,返回的tag也会不一样。
if 'root' in x:
print(x)
tag = True
g = foo()
print(g.send('a')) # 第一次send传了一个"a"给yield,yield又赋值给x,所以此时的x是"a",
# 然后send附带有next功能,继续往下走执行以下判断代码,判断不成立,
# 直到再次碰到yield,得到并返回tag = False。
# 所以得到的结果为False
print(g.send('root123'))
# 第二次send传了一个"root123"给yield,此时从上次执行的结果开始接着下面的代码
# 将send传过去的“root123”传过去后,进行判断,判断成功得到tag,此时tag = True,
# 然后,send的特性,继续next传值得到返回值tag,所以为True.
输出结果:
False
root123
True
二、面向过程编程
面向过程的核心是: 过程
定义:写一个程序,先做什么,再做什么,类似于流水线生产的方式
优点:思路清晰,把复杂的问题简单化、流程化了。
缺点:扩展性差。比如在这个编程过程中如果出现问题,一旦修改,有可能改动全部。
三、内置函数
1、abs()
英文文档:
Return the absolute value of the argument.
定义:求绝对值
例:求-100的绝对值
x = abs(-100) print(x) # 打印结果为100
2、all()
英文文档:
Return True if bool(x) is True for all values x in the iterable. If the iterable is empty, return True.
定义:传入一个可迭代对象,会把可迭代对象里所有的值一个个地取出来,取出来后做一个布尔运算,如果所有值的布尔值都是True,那么结果就是True。如果可迭代对象为空,则返回True。
例1:传入一个可迭代对象,其中有一个元素的布尔值为假
t = (1,2,3,4,0) x = all(t) print(x) # 打印结果为False,因为0是False,所以整体返回False
例2:传入一个空列表
l = [] x = all(l) print(x) # 打印结果为True,没有为什么,all()语法规定的。
例3:传入一个生成器表达式
# 已知生成器表达式(i for i in range(1,100))产生的所有值的布尔值都是True,
# 所以该生成器表达式用all()方法得到的也是Ture
print(all((i for i in range(1,100)))) # 打印结果为True
print(all(i for i in range(1,100))) # 打印结果为True
# 当碰到这种生成器表达式\列表解析时,用内置方法all()可以少输入一对括号
3、 any()
英文文档:
Return True if bool(x) is True for any x in the iterable. If the iterable is empty, return False.
定义:传入一个可迭代对象,会把可迭代对象里所有的值一个个地取出来,取出来后做一个布尔运算,如果有一个值的布尔值为True,那么结果就是True。如果可迭代对象为空,则返回False。
例1:传入一个可迭代对象,其中一个元素的布尔值为真
l = [False,0,'xiaobai',None] x = any(l) print(x) # 打印结果为True,'xiaobai'的布尔值是True,所以整体返回True。
例2:传入一个空元组
t = () x = any(t) print(x) # 打印结果为False
4、acsii()
英文文档:
Return an ASCII-only representation of an object. As repr(), return a string containing a printable representation of an object, but escape the non-ASCII characters in the string returned by repr() using \\x, \\u or \\U escapes. This generates a string similar to that returned by repr() in Python 2.
定义:调用对象的__repr__()方法,获得该方法的返回值。返回一个可打印的对象字符串方式表示。.当遇到非ASCII码时,就会输出\x,\u或\U等字符来表示。与Python 2版本里的repr()是等效的函数。
例1:传入一个数字10
x = ascii(10) print(type(x),x) # 打印结果为<class 'str'> 10
例2:传入一个非ASCII码
x = ascii('b\31')
print(type(x),x) # 打印结果为<class 'str'> 'b\x19'
5、bin()
英文文档:
Return the binary representation of an integer.
定义:把十进制转换成二进制
例:传入一个十进制数100
x = bin(100) print(x) # 打印结果为0b1100100
6、bool()
定义:求一个数据类型的布尔值,python所有的数据类型,除了0、None、False这三个的布尔值为False外,其它的都为True。
例1:传入一个数字0
x = bool(0) print(x) # 打印结果为False
例2:传入一个字符串“xiaobai”
x = bool(1) print(x) # 打印结果为True
7、oct()
英文文档:
Return the octal representation of an integer.
定义:把十进制转换成八进制
例:传一个十进制数100
x = oct(100) print(x) # 打印结果为0o144
8、hex()
英文文档:
Return the hexadecimal representation of an integer.
定义:把十进制转换成十六进制
例:传一个十进制数100
x = hex(100) print(x) # 打印结果为0x64
9、bytearray()
英文文档:
bytearray(iterable_of_ints) -> bytearray bytearray(string, encoding[, errors]) -> bytearray bytearray(bytes_or_buffer) -> mutable copy of bytes_or_buffer bytearray(int) -> bytes array of size given by the parameter initialized with null bytes bytearray() -> empty bytes array Construct a mutable bytearray object from: - an iterable yielding integers in range(256) - a text string encoded using the specified encoding - a bytes or a buffer object - any object implementing the buffer API. - an integer # (copied from class doc)
定义:返回一个新字节数组
例1:不传入任何值
x = bytearray() print(x) # 打印结果为:bytearray(b'')
例2:传入一个10
x = bytearray(10) print(x) # 打印结果为:bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')
10、bytes()
英文文档:
bytes(iterable_of_ints) -> bytes bytes(string, encoding[, errors]) -> bytes bytes(bytes_or_buffer) -> immutable copy of bytes_or_buffer bytes(int) -> bytes object of size given by the parameter initialized with null bytes bytes() -> empty bytes object Construct an immutable array of bytes from: - an iterable yielding integers in range(256) - a text string encoded using the specified encoding - any object implementing the buffer API. - an integer # (copied from class doc)
定义:将一个字符串转成字节类型
例1:传入一个数字10
x = bytes(10) print(x) # 打印结果为b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
例2:传入一个字符串”xiaobai“
x = bytes('xiaobai',encoding='utf-8') # 等同于:'xiaobai'.encode('utf-8')编码操作。
print(x) # 打印结果为b'xiaobai'
11、callable()
英文文档:
Return whether the object is callable (i.e., some kind of function). Note that classes are callable, as are instances of classes with a __call__() method.
定义:判断一个对象是否可被调用,是则返回True,不是则返回False
例:判断一个函数是否可被调用
def func():
pass
x = callable(func)
print(x) # 打印结果为True
12、chr()
英文文档:
Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff.
定义:把数字转换成ASCII表里对应的字符。
例:传入一个数字100
x = chr(100) print(x) # 打印结果为d,得到数字100对应ascii表里的字符“d”
13、ord()
英文文档:
Return the Unicode code point for a one-character string.
定义:把ASCII表里对应的字符转换成数字。
例:
x = ord('d')
print(x) # 打印结果为100,得到ascii表里的字符“d”对应的数字100
14、classmethod()
定义:
例:
15、staticmethod()
定义:
例:
16、property()
英文文档:
property(fget=None, fset=None, fdel=None, doc=None) -> property attribute fget is a function to be used for getting an attribute value, and likewise fset is a function for setting, and fdel a function for del'ing, an attribute. Typical use is to define a managed attribute x: class C(object): def getx(self): return self._x def setx(self, value): self._x = value def delx(self): del self._x x = property(getx, setx, delx, "I'm the 'x' property.") Decorators make defining new properties or modifying existing ones easy: class C(object): @property def x(self): "I am the 'x' property." return self._x @x.setter def x(self, value): self._x = value @x.deleter def x(self): del self._x # (copied from class doc)
定义:
例:
17、setattr
英文文档:
Sets the named attribute on the given object to the specified value. setattr(x, 'y', v) is equivalent to ``x.y = v''
定义:
例:
18、delattr()
英文文档:
Deletes the named attribute from the given object. delattr(x, 'y') is equivalent to ``del x.y''
定义:
例:
19、getattr()
英文文档:
getattr(object, name[, default]) -> value Get a named attribute from an object; getattr(x, 'y') is equivalent to x.y. When a default argument is given, it is returned when the attribute doesn't exist; without it, an exception is raised in that case.
定义:
例:
20、hasattr()
英文文档:
Return whether the object has an attribute with the given name. This is done by calling getattr(obj, name) and catching AttributeError.
定义:
例:
21、compile()
英文文档:
Compile source into a code object that can be executed by exec() or eval(). The source code may represent a Python module, statement or expression. The filename will be used for run-time error messages. The mode must be 'exec' to compile a module, 'single' to compile a single (interactive) statement, or 'eval' to compile an expression. The flags argument, if present, controls which future statements influence the compilation of the code. The dont_inherit argument, if true, stops the compilation inheriting the effects of any future statements in effect in the code calling compile; if absent or false these statements do influence the compilation, in addition to any features explicitly specified.
定义:可以控制字符串编译成字节码。
22、complex()
定义:复数
例:
x = complex(1,-3j) print(x.real) # 打印结果为得到实部:4.0 print(x.imag) # 打印结果为得到虚部:-0.0
23、int()
定义:产生一个整型
24、dict()
定义:产生一个字典
25、list()
定义:产生一个列表
26、tuple()
定义:产生一个元组
27、set()
定义:产生一个集合
例:
28、str()
定义:产生一个字符串
29、dir()
英文文档:
dir([object]) -> list of strings If called without an argument, return the names in the current scope. Else, return an alphabetized list of names comprising (some of) the attributes of the given object, and of attributes reachable from it. If the object supplies a method named __dir__, it will be used; otherwise the default dir() logic is used and returns: for a module object: the module's attributes. for a class object: its attributes, and recursively the attributes of its bases. for any other object: its attributes, its class's attributes, and recursively the attributes of its class's base classes.
定义:查看一个对象下面有哪些方法
例:查看os模块下面的方法
import os
print(dir(os)) # 打印结果为os模块下的所有方法
输出结果:
['DirEntry', 'F_OK', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED', 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX', 'W_OK', 'X_OK', '_Environ', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_putenv', '_unsetenv', '_wrap_close', 'abc', 'abort', 'access', 'altsep', 'chdir', 'chmod', 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'errno', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve', 'execvp', 'execvpe', 'extsep', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable', 'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'linesep', 'link', 'listdir', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name', 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep', 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_float_times', 'stat_result', 'statvfs_result', 'strerror', 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks', 'symlink', 'sys', 'system', 'terminal_size', 'times', 'times_result', 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'walk', 'write']
30、help()
英文文档:
Define the builtin 'help'. This is a wrapper around pydoc.help that provides a helpful message when 'help' is typed at the Python interactive prompt. Calling help() at the Python prompt starts an interactive help session. Calling help(thing) prints help for the python object 'thing'.
定义:查看帮助信息
例1:查看os模块下的帮助信息
import os print(help(os)) # 打印结果为os模块的帮助信息
输出结果:
Help on module os: NAME os - OS routines for NT or Posix depending on what system we're on. DESCRIPTION This exports: - all functions from posix or nt, e.g. unlink, stat, etc. - os.path is either posixpath or ntpath - os.name is either 'posix' or 'nt' - os.curdir is a string representing the current directory (always '.') - os.pardir is a string representing the parent directory (always '..') - os.sep is the (or a most common) pathname separator ('/' or '\\') - os.extsep is the extension separator (always '.') - os.altsep is the alternate pathname separator (None or '/') - os.pathsep is the component separator used in $PATH etc - os.linesep is the line separator in text files ('\r' or '\n' or '\r\n') - os.defpath is the default search path for executables - os.devnull is the file path of the null device ('/dev/null', etc.) Programs that import and use 'os' stand a better chance of being portable between different platforms. Of course, they must then only use functions that are defined by all platforms (e.g., unlink and opendir), and leave all pathname manipulation to os.path (e.g., split and join). CLASSES builtins.Exception(builtins.BaseException) builtins.OSError builtins.object nt.DirEntry builtins.tuple(builtins.object) nt.times_result nt.uname_result stat_result statvfs_result terminal_size class DirEntry(builtins.object) | Methods defined here: | | __fspath__(...) | returns the path for the entry | | __repr__(self, /) | Return repr(self). | | inode(...) | return inode of the entry; cached per entry | | is_dir(...) | return True if the entry is a directory; cached per entry | | is_file(...) | return True if the entry is a file; cached per entry | | is_symlink(...) | return True if the entry is a symbolic link; cached per entry | | stat(...) | return stat_result object for the entry; cached per entry | | ---------------------------------------------------------------------- | Data descriptors defined here: | | name | the entry's base filename, relative to scandir() "path" argument | | path | the entry's full path name; equivalent to os.path.join(scandir_path, entry.name) error = class OSError(Exception) | Base class for I/O related errors. | | Method resolution order: | OSError | Exception | BaseException | object | | Methods defined here: | | __init__(self, /, *args, **kwargs) | Initialize self. See help(type(self)) for accurate signature. | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __str__(self, /) | Return str(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | characters_written | | errno | POSIX exception code | | filename | exception filename | | filename2 | second exception filename | | strerror | exception strerror | | winerror | Win32 exception code | | ---------------------------------------------------------------------- | Methods inherited from BaseException: | | __delattr__(self, name, /) | Implement delattr(self, name). | | __getattribute__(self, name, /) | Return getattr(self, name). | | __repr__(self, /) | Return repr(self). | | __setattr__(self, name, value, /) | Implement setattr(self, name, value). | | __setstate__(...) | | with_traceback(...) | Exception.with_traceback(tb) -- | set self.__traceback__ to tb and return self. | | ---------------------------------------------------------------------- | Data descriptors inherited from BaseException: | | __cause__ | exception cause | | __context__ | exception context | | __dict__ | | __suppress_context__ | | __traceback__ | | args class stat_result(builtins.tuple) | stat_result: Result from stat, fstat, or lstat. | | This object may be accessed either as a tuple of | (mode, ino, dev, nlink, uid, gid, size, atime, mtime, ctime) | or via the attributes st_mode, st_ino, st_dev, st_nlink, st_uid, and so on. | | Posix/windows: If your platform supports st_blksize, st_blocks, st_rdev, | or st_flags, they are available as attributes only. | | See os.stat for more information. | | Method resolution order: | stat_result | builtins.tuple | builtins.object | | Methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __repr__(self, /) | Return repr(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | st_atime | time of last access | | st_atime_ns | time of last access in nanoseconds | | st_ctime | time of last change | | st_ctime_ns | time of last change in nanoseconds | | st_dev | device | | st_file_attributes | Windows file attribute bits | | st_gid | group ID of owner | | st_ino | inode | | st_mode | protection bits | | st_mtime | time of last modification | | st_mtime_ns | time of last modification in nanoseconds | | st_nlink | number of hard links | | st_size | total size, in bytes | | st_uid | user ID of owner | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | n_fields = 17 | | n_sequence_fields = 10 | | n_unnamed_fields = 3 | | ---------------------------------------------------------------------- | Methods inherited from builtins.tuple: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __getnewargs__(...) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __rmul__(self, value, /) | Return self*value. | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. class statvfs_result(builtins.tuple) | statvfs_result: Result from statvfs or fstatvfs. | | This object may be accessed either as a tuple of | (bsize, frsize, blocks, bfree, bavail, files, ffree, favail, flag, namemax), | or via the attributes f_bsize, f_frsize, f_blocks, f_bfree, and so on. | | See os.statvfs for more information. | | Method resolution order: | statvfs_result | builtins.tuple | builtins.object | | Methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __repr__(self, /) | Return repr(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | f_bavail | | f_bfree | | f_blocks | | f_bsize | | f_favail | | f_ffree | | f_files | | f_flag | | f_frsize | | f_namemax | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | n_fields = 10 | | n_sequence_fields = 10 | | n_unnamed_fields = 0 | | ---------------------------------------------------------------------- | Methods inherited from builtins.tuple: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __getnewargs__(...) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __rmul__(self, value, /) | Return self*value. | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. class terminal_size(builtins.tuple) | A tuple of (columns, lines) for holding terminal window size | | Method resolution order: | terminal_size | builtins.tuple | builtins.object | | Methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __repr__(self, /) | Return repr(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | columns | width of the terminal window in characters | | lines | height of the terminal window in characters | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | n_fields = 2 | | n_sequence_fields = 2 | | n_unnamed_fields = 0 | | ---------------------------------------------------------------------- | Methods inherited from builtins.tuple: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __getnewargs__(...) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __rmul__(self, value, /) | Return self*value. | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. class times_result(builtins.tuple) | times_result: Result from os.times(). | | This object may be accessed either as a tuple of | (user, system, children_user, children_system, elapsed), | or via the attributes user, system, children_user, children_system, | and elapsed. | | See os.times for more information. | | Method resolution order: | times_result | builtins.tuple | builtins.object | | Methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __repr__(self, /) | Return repr(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | children_system | system time of children | | children_user | user time of children | | elapsed | elapsed time since an arbitrary point in the past | | system | system time | | user | user time | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | n_fields = 5 | | n_sequence_fields = 5 | | n_unnamed_fields = 0 | | ---------------------------------------------------------------------- | Methods inherited from builtins.tuple: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __getnewargs__(...) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __rmul__(self, value, /) | Return self*value. | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. class uname_result(builtins.tuple) | uname_result: Result from os.uname(). | | This object may be accessed either as a tuple of | (sysname, nodename, release, version, machine), | or via the attributes sysname, nodename, release, version, and machine. | | See os.uname for more information. | | Method resolution order: | uname_result | builtins.tuple | builtins.object | | Methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | __reduce__(...) | helper for pickle | | __repr__(self, /) | Return repr(self). | | ---------------------------------------------------------------------- | Data descriptors defined here: | | machine | hardware identifier | | nodename | name of machine on network (implementation-defined) | | release | operating system release | | sysname | operating system name | | version | operating system version | | ---------------------------------------------------------------------- | Data and other attributes defined here: | | n_fields = 5 | | n_sequence_fields = 5 | | n_unnamed_fields = 0 | | ---------------------------------------------------------------------- | Methods inherited from builtins.tuple: | | __add__(self, value, /) | Return self+value. | | __contains__(self, key, /) | Return key in self. | | __eq__(self, value, /) | Return self==value. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getitem__(self, key, /) | Return self[key]. | | __getnewargs__(...) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __iter__(self, /) | Implement iter(self). | | __le__(self, value, /) | Return self<=value. | | __len__(self, /) | Return len(self). | | __lt__(self, value, /) | Return self<value. | | __mul__(self, value, /) | Return self*value.n | | __ne__(self, value, /) | Return self!=value. | | __rmul__(self, value, /) | Return self*value. | | count(...) | T.count(value) -> integer -- return number of occurrences of value | | index(...) | T.index(value, [start, [stop]]) -> integer -- return first index of value. | Raises ValueError if the value is not present. FUNCTIONS _exit(status) Exit to the system with specified status, without normal exit processing. abort() Abort the interpreter immediately. This function 'dumps core' or otherwise fails in the hardest way possible on the hosting operating system. This function never returns. access(path, mode, *, dir_fd=None, effective_ids=False, follow_symlinks=True) Use the real uid/gid to test for access to a path. path Path to be tested; can be string or bytes mode Operating-system mode bitfield. Can be F_OK to test existence, or the inclusive-OR of R_OK, W_OK, and X_OK. dir_fd If not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. effective_ids If True, access will use the effective uid/gid instead of the real uid/gid. follow_symlinks If False, and the last element of the path is a symbolic link, access will examine the symbolic link itself instead of the file the link points to. dir_fd, effective_ids, and follow_symlinks may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError. Note that most operations will use the effective uid/gid, therefore this routine can be used in a suid/sgid environment to test if the invoking user has the specified access to the path. chdir(path) Change the current working directory to the specified path. path may always be specified as a string. On some platforms, path may also be specified as an open file descriptor. If this functionality is unavailable, using it raises an exception. chmod(path, mode, *, dir_fd=None, follow_symlinks=True) Change the access permissions of a file. path Path to be modified. May always be specified as a str or bytes. On some platforms, path may also be specified as an open file descriptor. If this functionality is unavailable, using it raises an exception. mode Operating-system mode bitfield. dir_fd If not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. follow_symlinks If False, and the last element of the path is a symbolic link, chmod will modify the symbolic link itself instead of the file the link points to. It is an error to use dir_fd or follow_symlinks when specifying path as an open file descriptor. dir_fd and follow_symlinks may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError. close(fd) Close a file descriptor. closerange(fd_low, fd_high, /) Closes all file descriptors in [fd_low, fd_high), ignoring errors. cpu_count() Return the number of CPUs in the system; return None if indeterminable. This number is not equivalent to the number of CPUs the current process can use. The number of usable CPUs can be obtained with ``len(os.sched_getaffinity(0))`` device_encoding(fd) Return a string describing the encoding of a terminal's file descriptor. The file descriptor must be attached to a terminal. If the device is not a terminal, return None. dup(fd, /) Return a duplicate of a file descriptor. dup2(fd, fd2, inheritable=True) Duplicate file descriptor. execl(file, *args) execl(file, *args) Execute the executable file with argument list args, replacing the current process. execle(file, *args) execle(file, *args, env) Execute the executable file with argument list args and environment env, replacing the current process. execlp(file, *args) execlp(file, *args) Execute the executable file (which is searched for along $PATH) with argument list args, replacing the current process. execlpe(file, *args) execlpe(file, *args, env) Execute the executable file (which is searched for along $PATH) with argument list args and environment env, replacing the current process. execv(path, argv, /) Execute an executable path with arguments, replacing current process. path Path of executable file. argv Tuple or list of strings. execve(path, argv, env) Execute an executable path with arguments, replacing current process. path Path of executable file. argv Tuple or list of strings. env Dictionary of strings mapping to strings. execvp(file, args) execvp(file, args) Execute the executable file (which is searched for along $PATH) with argument list args, replacing the current process. args may be a list or tuple of strings. execvpe(file, args, env) execvpe(file, args, env) Execute the executable file (which is searched for along $PATH) with argument list args and environment env , replacing the current process. args may be a list or tuple of strings. fdopen(fd, *args, **kwargs) # Supply os.fdopen() fsdecode(filename) Decode filename (an os.PathLike, bytes, or str) from the filesystem encoding with 'surrogateescape' error handler, return str unchanged. On Windows, use 'strict' error handler if the file system encoding is 'mbcs' (which is the default encoding). fsencode(filename) Encode filename (an os.PathLike, bytes, or str) to the filesystem encoding with 'surrogateescape' error handler, return bytes unchanged. On Windows, use 'strict' error handler if the file system encoding is 'mbcs' (which is the default encoding). fspath(path) Return the file system path representation of the object. If the object is str or bytes, then allow it to pass through as-is. If the object defines __fspath__(), then return the result of that method. All other types raise a TypeError. fstat(fd) Perform a stat system call on the given file descriptor. Like stat(), but for an open file descriptor. Equivalent to os.stat(fd). fsync(fd) Force write of fd to disk. ftruncate(fd, length, /) Truncate a file, specified by file descriptor, to a specific length. get_exec_path(env=None) Returns the sequence of directories that will be searched for the named executable (similar to a shell) when launching a process. *env* must be an environment variable dict or None. If *env* is None, os.environ will be used. get_handle_inheritable(handle, /) Get the close-on-exe flag of the specified file descriptor. get_inheritable(fd, /) Get the close-on-exe flag of the specified file descriptor. get_terminal_size(...) Return the size of the terminal window as (columns, lines). The optional argument fd (default standard output) specifies which file descriptor should be queried. If the file descriptor is not connected to a terminal, an OSError is thrown. This function will only be defined if an implementation is available for this system. shutil.get_terminal_size is the high-level function which should normally be used, os.get_terminal_size is the low-level implementation. getcwd() Return a unicode string representing the current working directory. getcwdb() Return a bytes string representing the current working directory. getenv(key, default=None) Get an environment variable, return None if it doesn't exist. The optional second argument can specify an alternate default. key, default and the result are str. getlogin() Return the actual login name. getpid() Return the current process id. getppid() Return the parent's process id. If the parent process has already exited, Windows machines will still return its id; others systems will return the id of the 'init' process (1). isatty(fd, /) Return True if the fd is connected to a terminal. Return True if the file descriptor is an open file descriptor connected to the slave end of a terminal. kill(pid, signal, /) Kill a process with a signal. link(src, dst, *, src_dir_fd=None, dst_dir_fd=None, follow_symlinks=True) Create a hard link to a file. If either src_dir_fd or dst_dir_fd is not None, it should be a file descriptor open to a directory, and the respective path string (src or dst) should be relative; the path will then be relative to that directory. If follow_symlinks is False, and the last element of src is a symbolic link, link will create a link to the symbolic link itself instead of the file the link points to. src_dir_fd, dst_dir_fd, and follow_symlinks may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError. listdir(path=None) Return a list containing the names of the files in the directory. path can be specified as either str or bytes. If path is bytes, the filenames returned will also be bytes; in all other circumstances the filenames returned will be str. If path is None, uses the path='.'. On some platforms, path may also be specified as an open file descriptor;\ the file descriptor must refer to a directory. If this functionality is unavailable, using it raises NotImplementedError. The list is in arbitrary order. It does not include the special entries '.' and '..' even if they are present in the directory. lseek(fd, position, how, /) Set the position of a file descriptor. Return the new position. Return the new cursor position in number of bytes relative to the beginning of the file. lstat(path, *, dir_fd=None) Perform a stat system call on the given path, without following symbolic links. Like stat(), but do not follow symbolic links. Equivalent to stat(path, follow_symlinks=False). makedirs(name, mode=511, exist_ok=False) makedirs(name [, mode=0o777][, exist_ok=False]) Super-mkdir; create a leaf directory and all intermediate ones. Works like mkdir, except that any intermediate path segment (not just the rightmost) will be created if it does not exist. If the target directory already exists, raise an OSError if exist_ok is False. Otherwise no exception is raised. This is recursive. mkdir(path, mode=511, *, dir_fd=None) Create a directory. If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. The mode argument is ignored on Windows. open(path, flags, mode=511, *, dir_fd=None) Open a file for low level IO. Returns a file descriptor (integer). If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. pipe() Create a pipe. Returns a tuple of two file descriptors: (read_fd, write_fd) popen(cmd, mode='r', buffering=-1) # Supply os.popen() putenv(name, value, /) Change or add an environment variable. read(fd, length, /) Read from a file descriptor. Returns a bytes object. readlink(...) readlink(path, *, dir_fd=None) -> path Return a string representing the path to which the symbolic link points. If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. remove(path, *, dir_fd=None) Remove a file (same as unlink()). If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. removedirs(name) removedirs(name) Super-rmdir; remove a leaf directory and all empty intermediate ones. Works like rmdir except that, if the leaf directory is successfully removed, directories corresponding to rightmost path segments will be pruned away until either the whole path is consumed or an error occurs. Errors during this latter phase are ignored -- they generally mean that a directory was not empty. rename(src, dst, *, src_dir_fd=None, dst_dir_fd=None) Rename a file or directory. If either src_dir_fd or dst_dir_fd is not None, it should be a file descriptor open to a directory, and the respective path string (src or dst) should be relative; the path will then be relative to that directory. src_dir_fd and dst_dir_fd, may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError. renames(old, new) renames(old, new) Super-rename; create directories as necessary and delete any left empty. Works like rename, except creation of any intermediate directories needed to make the new pathname good is attempted first. After the rename, directories corresponding to rightmost path segments of the old name will be pruned until either the whole path is consumed or a nonempty directory is found. Note: this function can fail with the new directory structure made if you lack permissions needed to unlink the leaf directory or file. replace(src, dst, *, src_dir_fd=None, dst_dir_fd=None) Rename a file or directory, overwriting the destination. If either src_dir_fd or dst_dir_fd is not None, it should be a file descriptor open to a directory, and the respective path string (src or dst) should be relative; the path will then be relative to that directory. src_dir_fd and dst_dir_fd, may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError." rmdir(path, *, dir_fd=None) Remove a directory. If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. scandir(...) scandir(path='.') -> iterator of DirEntry objects for given path set_handle_inheritable(handle, inheritable, /) Set the inheritable flag of the specified handle. set_inheritable(fd, inheritable, /) Set the inheritable flag of the specified file descriptor. spawnl(mode, file, *args) spawnl(mode, file, *args) -> integer Execute file with arguments from args in a subprocess. If mode == P_NOWAIT return the pid of the process. If mode == P_WAIT return the process's exit code if it exits normally; otherwise return -SIG, where SIG is the signal that killed it. spawnle(mode, file, *args) spawnle(mode, file, *args, env) -> integer Execute file with arguments from args in a subprocess with the supplied environment. If mode == P_NOWAIT return the pid of the process. If mode == P_WAIT return the process's exit code if it exits normally; otherwise return -SIG, where SIG is the signal that killed it. spawnv(mode, path, argv, /) Execute the program specified by path in a new process. mode Mode of process creation. path Path of executable file. argv Tuple or list of strings. spawnve(mode, path, argv, env, /) Execute the program specified by path in a new process. mode Mode of process creation. path Path of executable file. argv Tuple or list of strings. env Dictionary of strings mapping to strings. startfile(filepath, operation=None) startfile(filepath [, operation]) Start a file with its associated application. When "operation" is not specified or "open", this acts like double-clicking the file in Explorer, or giving the file name as an argument to the DOS "start" command: the file is opened with whatever application (if any) its extension is associated. When another "operation" is given, it specifies what should be done with the file. A typical operation is "print". startfile returns as soon as the associated application is launched. There is no option to wait for the application to close, and no way to retrieve the application's exit status. The filepath is relative to the current directory. If you want to use an absolute path, make sure the first character is not a slash ("/"); the underlying Win32 ShellExecute function doesn't work if it is. stat(path, *, dir_fd=None, follow_symlinks=True) Perform a stat system call on the given path. path Path to be examined; can be string, bytes, path-like object or open-file-descriptor int. dir_fd If not None, it should be a file descriptor open to a directory, and path should be a relative string; path will then be relative to that directory. follow_symlinks If False, and the last element of the path is a symbolic link, stat will examine the symbolic link itself instead of the file the link points to. dir_fd and follow_symlinks may not be implemented on your platform. If they are unavailable, using them will raise a NotImplementedError. It's an error to use dir_fd or follow_symlinks when specifying path as an open file descriptor. stat_float_times(...) stat_float_times([newval]) -> oldval Determine whether os.[lf]stat represents time stamps as float objects. If value is True, future calls to stat() return floats; if it is False, future calls return ints. If value is omitted, return the current setting. strerror(code, /) Translate an error code to a message string. symlink(src, dst, target_is_directory=False, *, dir_fd=None) Create a symbolic link pointing to src named dst. target_is_directory is required on Windows if the target is to be interpreted as a directory. (On Windows, symlink requires Windows 6.0 or greater, and raises a NotImplementedError otherwise.) target_is_directory is ignored on non-Windows platforms. If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. system(command) Execute the command in a subshell. times() Return a collection containing process timing information. The object returned behaves like a named tuple with these fields: (utime, stime, cutime, cstime, elapsed_time) All fields are floating point numbers. truncate(path, length) Truncate a file, specified by path, to a specific length. On some platforms, path may also be specified as an open file descriptor. If this functionality is unavailable, using it raises an exception. umask(mask, /) Set the current numeric umask and return the previous umask. unlink(path, *, dir_fd=None) Remove a file (same as remove()). If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. dir_fd may not be implemented on your platform. If it is unavailable, using it will raise a NotImplementedError. urandom(size, /) Return a bytes object containing random bytes suitable for cryptographic use. utime(path, times=None, *, ns=None, dir_fd=None, follow_symlinks=True) Set the access and modified time of path. path may always be specified as a string. On some platforms, path may also be specified as an open file descriptor. If this functionality is unavailable, using it raises an exception. If times is not None, it must be a tuple (atime, mtime); atime and mtime should be expressed as float seconds since the epoch. If ns is specified, it must be a tuple (atime_ns, mtime_ns); atime_ns and mtime_ns should be expressed as integer nanoseconds since the epoch. If times is None and ns is unspecified, utime uses the current time. Specifying tuples for both times and ns is an error. If dir_fd is not None, it should be a file descriptor open to a directory, and path should be relative; path will then be relative to that directory. If follow_symlinks is False, and the last element of the path is a symbolic link, utime will modify the symbolic link itself instead of the file the link points to. It is an error to use dir_fd or follow_symlinks when specifying path as an open file descriptor. dir_fd and follow_symlinks may not be available on your platform. If they are unavailable, using them will raise a NotImplementedError. waitpid(pid, options, /) Wait for completion of a given process. Returns a tuple of information regarding the process: (pid, status << 8) The options argument is ignored on Windows. walk(top, topdown=True, onerror=None, followlinks=False) Directory tree generator. For each directory in the directory tree rooted at top (including top itself, but excluding '.' and '..'), yields a 3-tuple dirpath, dirnames, filenames dirpath is a string, the path to the directory. dirnames is a list of the names of the subdirectories in dirpath (excluding '.' and '..'). filenames is a list of the names of the non-directory files in dirpath. Note that the names in the lists are just names, with no path components. To get a full path (which begins with top) to a file or directory in dirpath, do os.path.join(dirpath, name). If optional arg 'topdown' is true or not specified, the triple for a directory is generated before the triples for any of its subdirectories (directories are generated top down). If topdown is false, the triple for a directory is generated after the triples for all of its subdirectories (directories are generated bottom up). When topdown is true, the caller can modify the dirnames list in-place (e.g., via del or slice assignment), and walk will only recurse into the subdirectories whose names remain in dirnames; this can be used to prune the search, or to impose a specific order of visiting. Modifying dirnames when topdown is false is ineffective, since the directories in dirnames have already been generated by the time dirnames itself is generated. No matter the value of topdown, the list of subdirectories is retrieved before the tuples for the directory and its subdirectories are generated. By default errors from the os.scandir() call are ignored. If optional arg 'onerror' is specified, it should be a function; it will be called with one argument, an OSError instance. It can report the error to continue with the walk, or raise the exception to abort the walk. Note that the filename is available as the filename attribute of the exception object. By default, os.walk does not follow symbolic links to subdirectories on systems that support them. In order to get this functionality, set the optional argument 'followlinks' to true. Caution: if you pass a relative pathname for top, don't change the current working directory between resumptions of walk. walk never changes the current directory, and assumes that the client doesn't either. Example: import os from os.path import join, getsize for root, dirs, files in os.walk('python/Lib/email'): print(root, "consumes", end="") print(sum([getsize(join(root, name)) for name in files]), end="") print("bytes in", len(files), "non-directory files") if 'CVS' in dirs: dirs.remove('CVS') # don't visit CVS directories write(fd, data, /) Write a bytes object to a file descriptor. DATA F_OK = 0 O_APPEND = 8 O_BINARY = 32768 O_CREAT = 256 O_EXCL = 1024 O_NOINHERIT = 128 O_RANDOM = 16 O_RDONLY = 0 O_RDWR = 2 O_SEQUENTIAL = 32 O_SHORT_LIVED = 4096 O_TEMPORARY = 64 O_TEXT = 16384 O_TRUNC = 512 O_WRONLY = 1 P_DETACH = 4 P_NOWAIT = 1 P_NOWAITO = 3 P_OVERLAY = 2 P_WAIT = 0 R_OK = 4 SEEK_CUR = 1 SEEK_END = 2 SEEK_SET = 0 TMP_MAX = 2147483647 W_OK = 2 X_OK = 1 __all__ = ['altsep', 'curdir', 'pardir', 'sep', 'pathsep', 'linesep', ... altsep = '/' curdir = '.' defpath = r'.;C:\bin' devnull = 'nul' environ = environ({'ALLUSERSPROFILE': 'C:\\ProgramData', '...: 'C:\\Us... extsep = '.' linesep = '\r\n' name = 'nt' pardir = '..' pathsep = ';' sep = r'\' supports_bytes_environ = False FILE c:\python\python36\lib\os.py None
例2:查看函数的帮助文档
def func():
'''This is a test function'''
pass
x = help(func)
print(x)
输出结果:
Help on function func in module __main__: func() This is a test function None
31、divmod()
英文文档
定义:
例:
英文文档
定义:
例:
英文文档
定义:
例:
英文文档
定义:
例:
英文文档
定义:
例:
