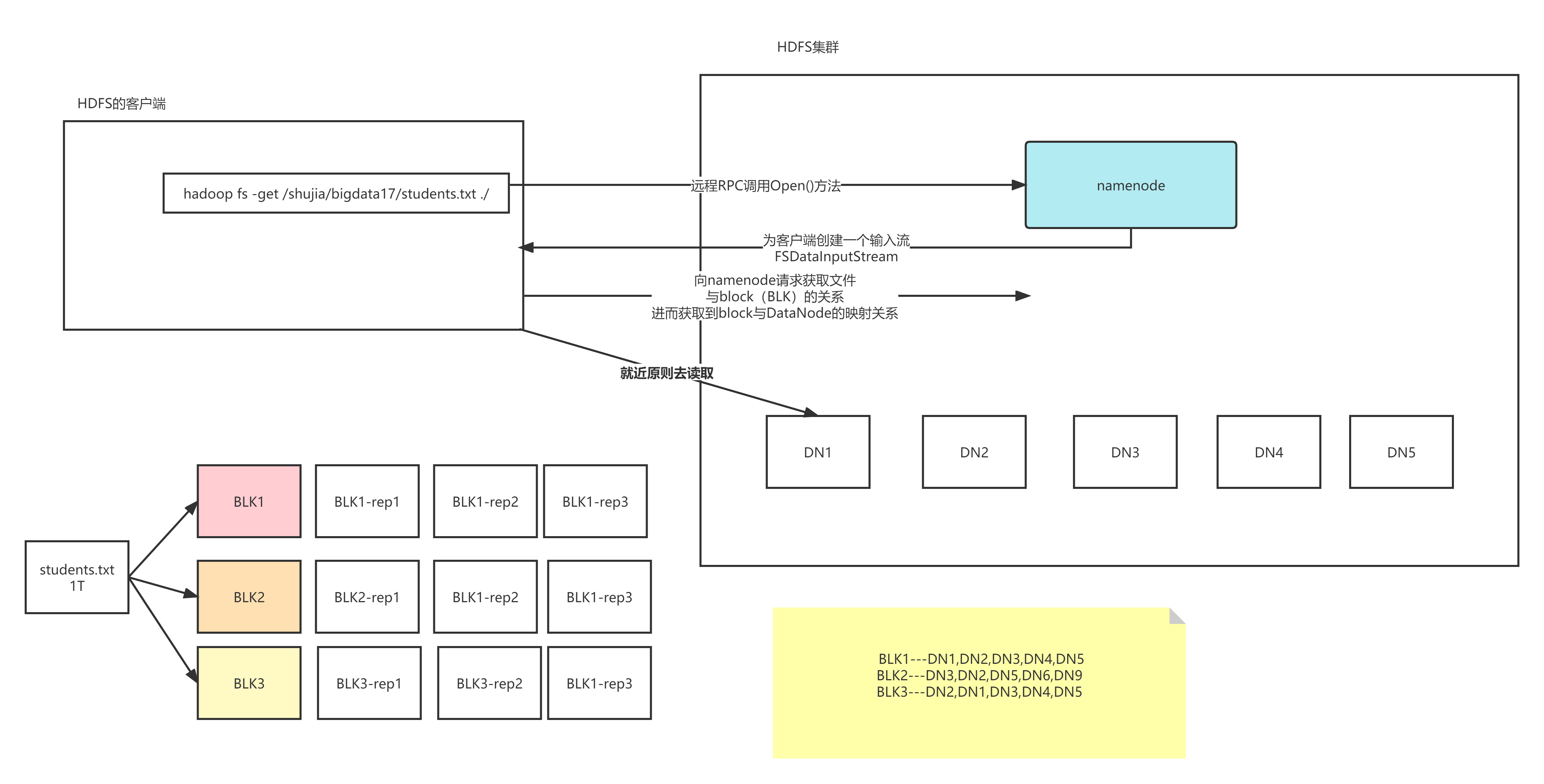
HDFS读写流程
一、写数据
写数据就是将客户端上的数据上传到HDFS
1.1 宏观过程
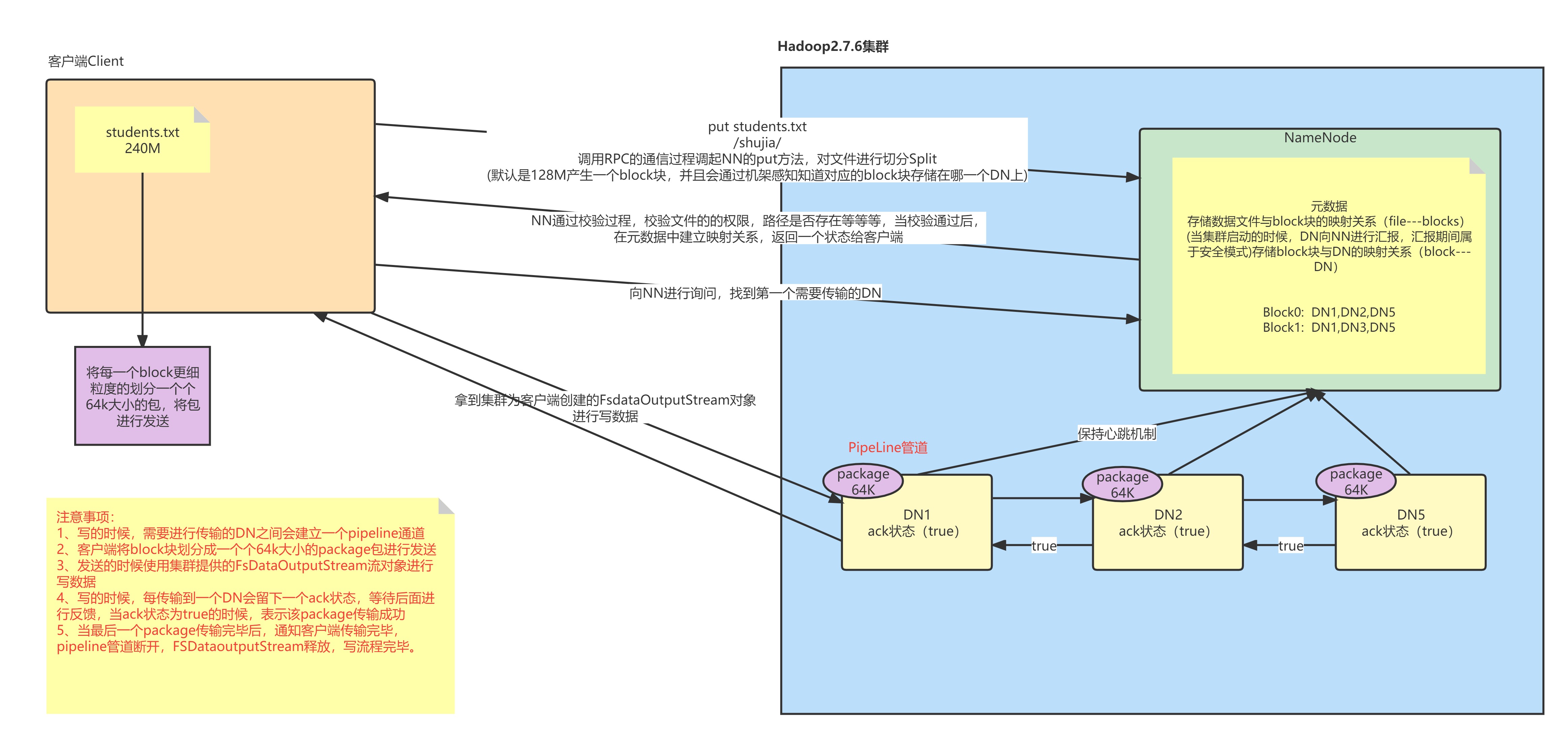
hdfs dfs -put students.txt /shujia/
2. Filesystem通过rpc调用namenode的put方法
a. nn首先检查是否有足够的空间权限等条件创建这个文件,或者这个路径是否已经存在,权限
b. 有:NN会针对这个文件创建一个空的Entry对象,并返回成功状态给DFS
c. 没有:直接抛出对应的异常,给予客户端错误提示信息
3.如果DFS接收到成功的状态,会创建一个FSDataOutputStream的对象给客户端使用
4.客户端要向nn询问第一个Block存放的位置
NN通过机架感知策略 (node1 node 2 node3)
5.需要将客户端和DN节点创建连接
pipeline(管道)
客户端 和 node1 创建连接 socket node1 和 node2 创建连接 socket node2 和 Node3 创建连接 socket
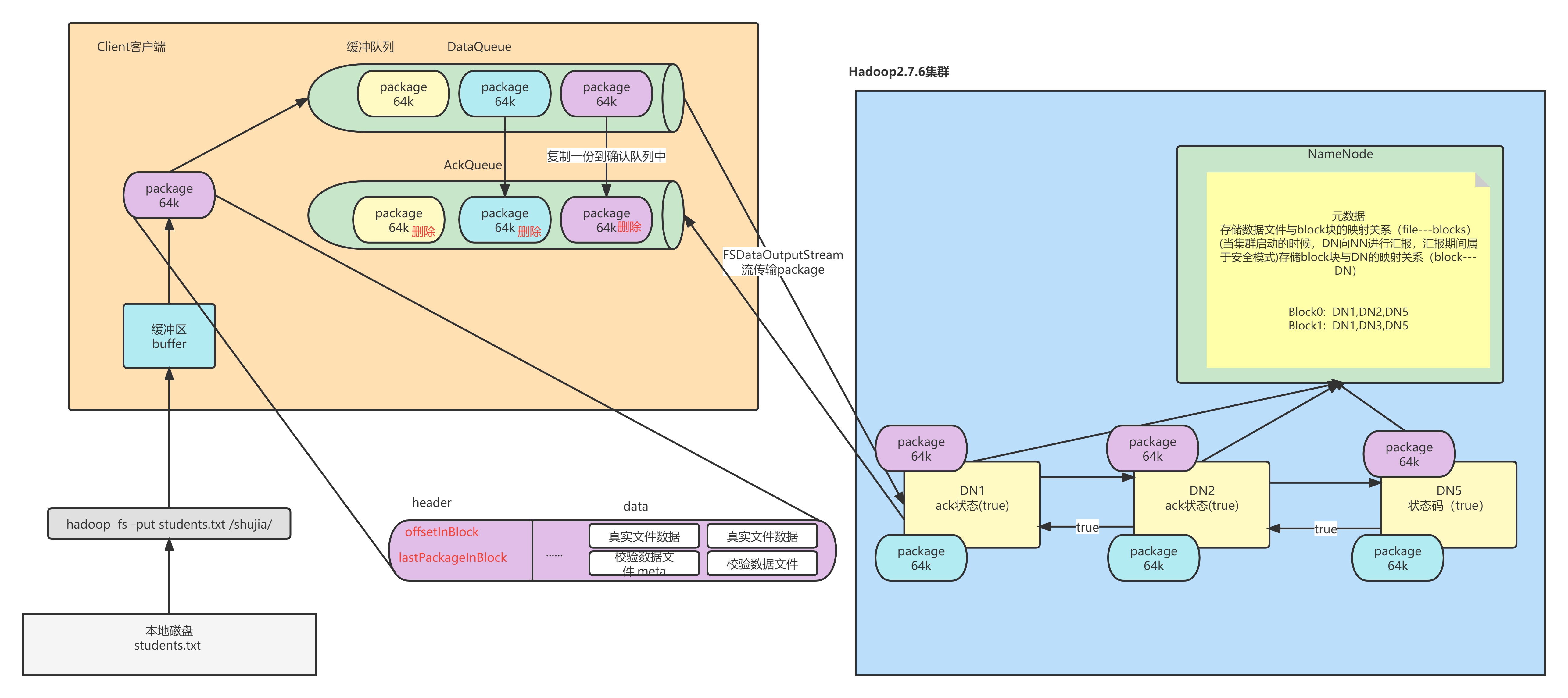
6.客户端按照文件块切分数据,但是按照packet发送数据
默认一个packet大小为64K,Block128M为2048个packet
7.客户端通过pipeline管道开始使用FDSOutputStream对象将数据输出
1. 客户端首先将一个 packet 发送给 node1, 同时给予 node1 一个 ack 状态
2. node1接受数据后会将数据继续传递给 node2, 同时给予 node2 一个 ack 状态
3. node2接受数据后会将数据继续传递给 node3, 同时给予 node3 一个 ack 状态
4. node3将这个 packet 接受完成后,会响应这个 ack 给 node2 为 true
5. node2会响应给 node1 , 同理 node1 响应给客户端8.客户端接收到成功的状态 , 就认为某个 packet 发送成功了,直到当前块所有的 packet 都发送完成
1. 如果客户端接收到最后一个 pakcet 的成功状态 , 说明当前 block 传输完成,管道就会被撤销
2. 客户端会将这个消息传递给 NN , NN 确认传输完成
1. NN会将 block 的信息记录到 Entry, 客户端会继续向 NN 询问第二个块的存储位置 , 依次类推
block1 (node1 node2 node3)
block2 (node1 node3 node6)
....
blockn(node1 node4 node6)
3. 当所有的 block 传输完成后, NN 在 Entry 中存储所有的 File 与 Block 与 DN 的映射关系关闭
客户端发送一个 Packet 数据包以后开始接收 ack ,会有一个用来接收 ack 的 ResponseProcessor 进 程,如果收到成功的 ack
1. 如果某一个 packet 的 ack 为 true, 那么就从 ackqueue 删除掉这个 packet
2. 如果某一个 packet 的 ack 为 false, 将 ackqueue 中所有的 packet 重新挂载到 发送队列 , 重新发送

 浙公网安备 33010602011771号
浙公网安备 33010602011771号