

MySQL索引原理
索引原理
-
树
-

图片_20211212163637.png) -
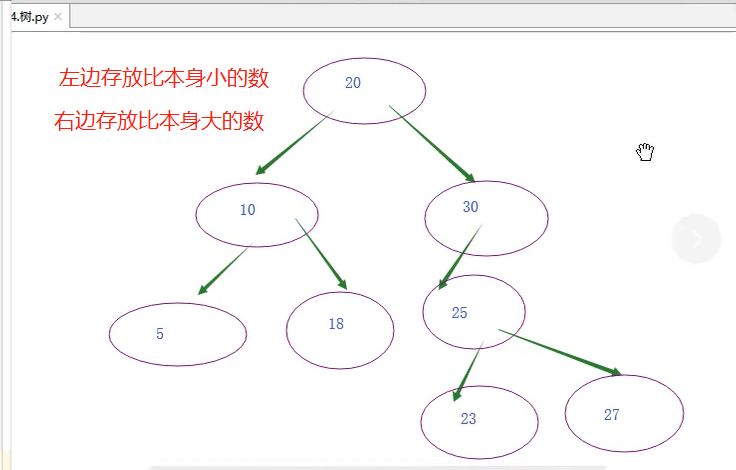
二叉树:每个父节点下面最多有两个儿子,一边存放比本身大的数,一边存放比本身小的数
- 效率,找几次取决于树的高度
-
平衡树(balance tree 简称btree):能够让查找某一个值经历的查找速度尽量平衡
-
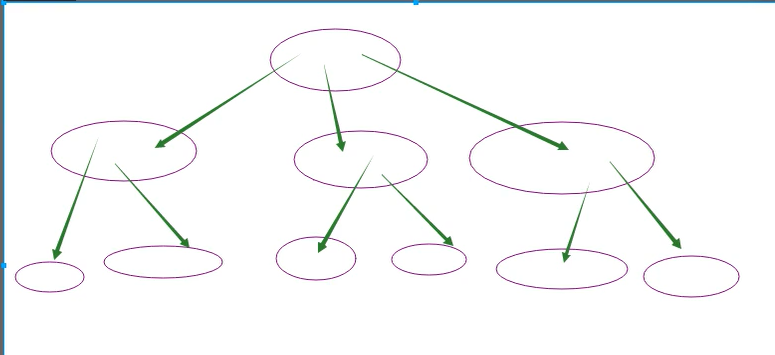
- 平衡树不一定是二叉树
- b+树:
- 在b树的基础上做了增加,b是平衡的意思,为了保证每一个数据查找经历的IO次数都相同
- 分支节点不存储数据,只在叶子节点存储数据,让树的高度尽量矮,让查找一个数据的效率尽量稳定
- 在所有叶子节点之间,加入了双向的地址链接 -- 查找范围非常快
- mysql中存储数据的两种方式:
- 聚集索引,聚簇索引:
- 全表的数据都存储在叶子节点上
- 使用innodb存储引擎,主键默认就会创建一个、聚集索引
- 非聚集(非聚簇)索引,辅组索引:
- 叶子节点不存放具体的整行数据,而是存储的这一行的主键的值
- Innodb
- myisam
- 聚集索引,聚簇索引:
-
-
索引的创建和删除
- 创建
- create index 索引名称 on 表(字段);
- 创建联合索引:create index 索引名称on 表名(字段1,字段2,字段3);
- 删除
- drop index 索引名 on 表;
- 使用索引会加快查询速度,但是会占用内存,是一种使用空间换时间的行为
- 创建
-
正确的使用MySQL数据库
-
从库的角度
- 搭建集群
- 读写分离
- 分库
-
从表的角度
- 合理安排表与表之间的关系
- 把固定长度的字段放在前面
- 正确的使用char和varchar
-
从操作数据的角度
-
尽量在where字段就约束数值到一个比较小的范围:分页
-
尽量使用连表查询代替子查询
-
删除数据的时候尽量使用主键
-
合理的创建索引
- 创建索引时选择区分度比较大的列
- 尽量选择短的字段创建索引
- 不要创建不必要的索引,及时删除不用的索引
-
合理的使用索引
-
查询的字段必须是索引字段
-
在条件中使用范围,结果的范围越大速度越慢,范围越小就越快
-
like 'a%' 命中索引快 , like '%a' 不命中索引慢
-
条件列不能参与计算、不能使用函数
-
and,or
- 多个条件的组合,如果使用and连接,其中一列含有索引,多可以加快查询速度
- 如果使用or连接,必须所有的列都含有索引,才能加快查询速度
-
联合索引:遵循最左前缀原则,必须带着最左边的列做条件,从出现范围整条索引开始失效

-
-
条件中的数据类型和实际字段的类型必须一致
-
order by:
- 排序条件为索引 则select 字段必须也是索引字段,否者无法命中
- X:select name from s1 order by email desc;
- √:select email from s1 order by email desc;
-
索引散列值(重复少)不适合建立索引(例:性别不合适)
-
覆盖索引:查询过程中不需要回表
- select id from 表 where id>1000000;
- select max(id) from 表 where id>1000000;
- select count(id) from 表 where id>1000000;
-
索引合并:分别创建的两个索引在某一次的查询中临时合并成一条索引 a=1 or b=2
-
执行计划explain select 语句:能够查看sql语句中有没有按照预期执行,可以查看索引的使用情况,type等级
-
慢查询优化:
- 从SQL角度优化
- 把每一句话单独执行,找到效率低的表,优化这句SQL
- 了解业务场景,适当创建索引,帮助查询
- 尽量用连表代替子查询
- 确定命中索引的情况
- 考虑修改表结构
- 拆表
- 把固定的字段往前调整
- 使用执行计划,观察SQL的type是否提高
- 从SQL角度优化
-
MySQL的慢日志
- 在mysql的配置中开启并设置一下
- 在超过设置时间之后这条sql总是会背记录下来
- 这个时候我们可以对这些被记录的sql进行一个定期优化
-
-

