

继承的基础语法
继承的基础语法
- 继承的优点:解决代码的重复性
- 继承的加载过程

- 继承过程:
- 实例化对象的时候,先开辟空间,空间里有一个类指针,指向Cat,
- 调用init的时候先在自己的空间中寻找,如果找不到先去就去Cat(如果是继承Cat类中会保存Anmial(父类)的内存地址)类空间中寻找
- 如果Cat类中也没有,就去Animal中寻找
class Animal:
def __init__(self,name):
self.name=name
def eat(self):
print(f'{self.name} is eating')
def drink(self):
print(f'{self.name} is drink')
def sleep(self):
print(f'{self.name} is sleep')
class Cat(Animal):
def climb_tree(self): #爬树
print(f'{self.name} is clamb_tree')
class Dog(Animal):
def house_keep(self): # 看家
print(f'{self.name} is house_keeping')
# dingdang=Cat('dingdang')
# dingdang.eat()
# dingdang.drink()
# dingdang.sleep()
# dingdang.climb_tree()
# xiaobai=Dog('xiaobai')
# xiaobai.eat()
# xiaobai.drink()
# xiaobai.sleep()
# xiaobai.house_keep()
子类要调用父类方法的同时同时还想执行自己的同名方法
-
猫和狗在调用eat的时候即调用自己的也调用父类的
-
在字类的方法中调用父类的方法 父类名.方法名(self)
-
父类和子类方法的选择:
- 字类的对象如果去调用方法,永远优先调用自己的,没有则调用父类的
- 如果自己有还想用父类的,直接在子类方法中调用父类的方法父类名.方法名(self)
class Animal:
def __init__(self,name,food):
self.name=name
self.food=food
self.blood = 100
self.waise = 100
def eat(self):
print(f'{self.name} is eating{self.food}')
def drink(self):
print(f'{self.name} is drink')
def sleep(self):
print(f'{self.name} is sleep')
class Cat(Animal):
def eat(self): #与父类方法重名的同时还想调用父类的方法
Animal.eat(self) #直接在子类方法中调用父类的方法父类名.方法名(self)
self.blood+=100
def climb_tree(self): #爬树
print(f'{self.name} is clamb_tree') #如果没有和父类重名
self.drink() #可以直接调用
class Dog(Animal):
def eat(self):
Animal.eat(self)
self.waise+=100
def house_keep(self): # 看家
print(f'{self.name} is house_keeping')
ret=Cat('小白','凯纳利')
ret.eat()
print(ret.__dict__)
ret.climb_tree()
print(ret.__dict__)
继承的类型
单继承
- 一类继承自另一个类
- 多个子类继承自一个父类,也是单继承
#方式一,一类继承自另一个类
class Foo:
def __init__(self):
self.func()
def func(self):
print('is foo')
class Son(Foo):
def func(self):
print('is son')
Son()
#方式二,多个子类继承自一个父类,也是单继承
class Foo:
def __init__(self):
self.func()
def func(self):
print('is foo')
class Bon(Foo):
def func(self):
print('is Bon')
class Son(Foo):
def func(self):
print('is son')
Son()
Bon()
多继承
- 一个子类继承自多个父类,现在离class 近的类中寻找
class Foo:
def __init__(self):
self.func()
def func(self):
print('is foo')
class Bon:
def func(self):
print('is Bon')
class Son(Foo,Bon):
pass
Son()
单继承和多继承的使用场景
-
单继承
-
调子类的:子类自己有的时候
-
调父类的:子类没有的时候
-
同时调用字类和父类:子类父类都有,在子类中调用父类的
-
-
多继承
- 一个类有多个父类,在调用父类方法的时候,按照继承顺序,先继承的就先寻找
知识点补充
-
object类 类祖宗
- 所有在python3中的类都是继承object类
-
特殊类属性
__bases__方法:显示上一级的所有父类__base__方法:显示类的第一个父类__name__方法:显示类的名字__doc__方法:类的文档字符串__dict__方法:显示类的字典属性__module__方法:显示类定义所在的模块__class__方法:实例对应的类
-
将对象写入文件
class Animal: def __init__(self,name,food): self.name=name self.food=food self.blood = 100 self.waise = 100 def eat(self): print(f'{self.name} is eating{self.food}') def drink(self): print(f'{self.name} is drink') def sleep(self): print(f'{self.name} is sleep') class Cat(Animal): def eat(self): #与父类方法重名的同时还想调用父类的方法 Animal.eat(self) #直接在子类方法中调用父类的方法父类名.方法名(self) self.blood+=100 def climb_tree(self): #爬树 print(f'{self.name} is clamb_tree') #如果没有和父类重名 self.drink() #可以直接调用 class Dog(Animal): def eat(self): Animal.eat(self) self.waise+=100 def house_keep(self): # 看家 print(f'{self.name} is house_keeping') ret=Cat('小白','凯纳利') ret1=Dog('小黑','凯') ret.eat() print(ret.__dict__) import pickle with open('mian.txt',mode='wb') as f1: #写入 pickle.dump(ret,f1) pickle.dump(ret1,f1) with open('mian.txt',mode='rb') as f2: #读取 s=pickle.load(f2) s1=pickle.load(f2) print(s.name,s.food) print(s1.name,s1.food)
多继承的顺序问题(项目,源码)
- 写代码的过程中是先有父类还是先有子类
- 在加载代码的过程中 需要先加载父类 所以父类应该写在前面
- 从思考角度出发,总是先把子类读写完 发现重复的代码 再把重复的代码放到父类中
新式类和经典类
-
新式类
- 只要继承自object类就是新式类
- 在python3中所有的类都继承自object类
- 所有python3中所有的类都是新式类
-
经典类:
-
在python3中不存在只存在于python2中,在python2中不继承object的类都是经典类
-
python3中所有的类都继承object类,都是新式类
-
python2中继承object的类是新式类,不继承的就是经典类
-
新式类和经典类的区别
单继承都一样都是一层一层寻找
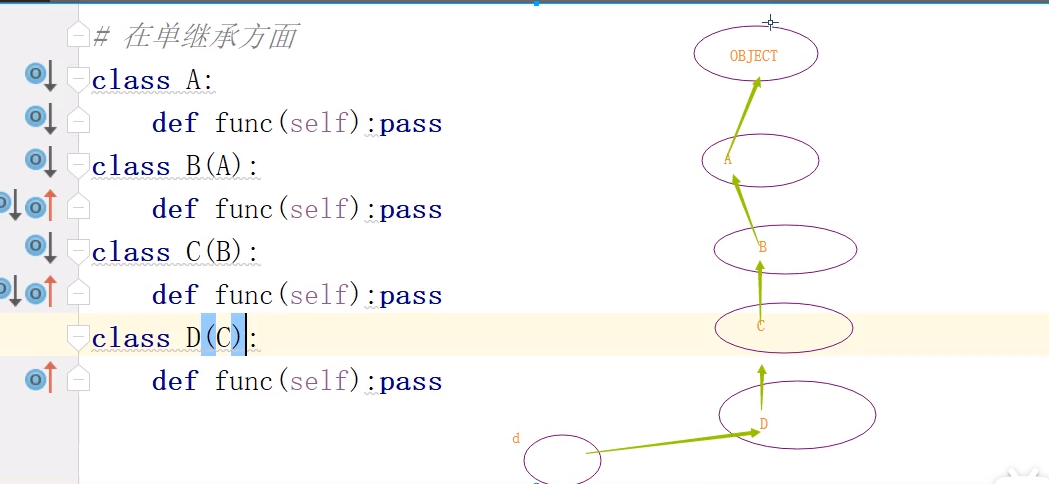
-
多继承
- 新式类中广度优先,(在走到一个点,下一个点既可以从深度走,也可以从广度走的时候,总是先走广度再走深度)
- 经典类中深度优先(遵循的C3算法,也可以直接使用类名.mro()查找),(在走到一个点,下一个点既可以从深度走,也可以从广度走的时候,总是先走深度再走深度)

- 深度优先继承(经典类)
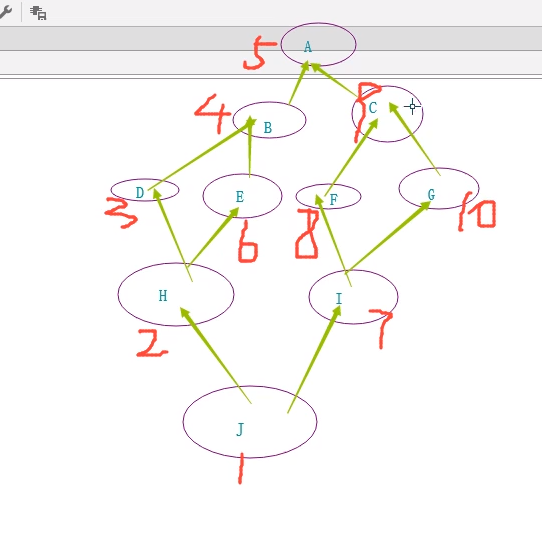
- 广度优先继承(新式类)
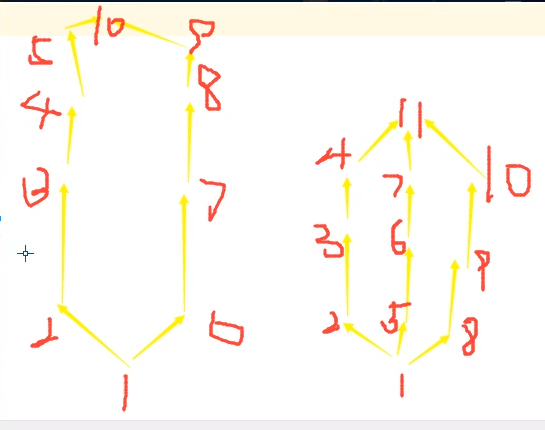
C3算法(用于查找新式类中多继承(广度优先)的计算顺序)
- 类(父类)=[当前类到object顶层类的顺序]
- [最下边的子类]+[上层的父类1]+[上层的父类2]+.......
- 列表按照从左到右的顺序,依次寻找列表中不重复的顺序,并移到左边(例子: F=[DBAO]+[ECAO])
- 如果有重复且不是在前面相同的位置就先不提去,顺序向后继续找其他顺序中符合条件的类,最后如果在相同的位置重复则同时去除
# C3算法
# A继承自object,[AO]加载顺序
# A(O)=[AO]
# B继承自A,
#B(A)=[BAO]
# C继承自A
#C(A)=[CAO]
# D继承自B
#D(B)=[DBAO]
# E继承自C
# E(C)=[ECAO]
# F(D,E)=C3(D(B)+E(C))
# 自己加上父类的加载顺序,从最左边开始提取不在列表中的顺序
# =[F]+[DBAO]+[ECAO]
# F=[DBAO]+[ECAO]
# FD=[BAO]+[ECAO]
# 因为AO在两个列表中都有,所以先不提取
# FDB=[AO]+[ECAO]
# FDBE=[AO]+[CAO]
# FDBEC=[AO]+[AO]
# 此处两个A同时取出
# FDBECA =[O]+[O]
# 此处两个O同时取出
# FDBECA0
# 算法的内容
# 如果是单继承,那么总是按照从子类--》父类的顺序来计算查找顺序
# 如果是多继承 需要按照自己的本类,父类以的继承顺序,父类二的继承顺序。。。。
# merge的规则:如果一个类出现在从左到右所有顺序的最左侧,并且没有在其他位置出现,那么继承顺序先提出来,作为继承顺序中的一个
# 或者一个类出现在从左到右的最左侧,没有在其他顺序出现,那么也可以先提取出来,作为继承顺序的一个
# 如果从左到右第一个顺序中第一个类出现在后面且不是第一个,那么不能提取,顺序向后继续找其他顺序中符合条件的类
- mro()查找继承关系(mro可以查找C3的结果)
- 只能在广度优先(新式类)中使用,经典类没有此方法
class A(object):
pass
class B(A):
pass
class C(A):
pass
class D(B,C):
pass
print(D.mro())
# [<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
总结
- 新式类
- 单继承:深度优先
- 多继承:广度优先 -优先遵循C3算法 - 会用mro()函数查看顺序(经典类中没有mro())
- 经典类
- 单继承:深度优先
- 多继承:深度优先 - 自己能搞出顺序来

