
逻辑回归(Logistic Regression)
@
什么是逻辑回归?
首先,什么是逻辑回归呢?
当你看到这个名字的时候,你可能会被他误导,认为他是做回归的,实际上,他是一个分类模型。只不过他是在线性回归的基础上进行了扩展,使其可以进行分类了而已。
同样的,逻辑回归的与线性回归一样,也是以线性函数为基础的;而与线性回归不同的是,逻辑回归在线性函数的基础上添加了一个非线性函数,如sigmoid函数,使其可以进行分类。
逻辑回归的原理
关于逻辑回归的原理呢,大家可以参照一下我以前的文章线性回归,当然,下面也会进行一些介绍。
像线性回归一样,咱们先看一下逻辑回归的分类情况(以鸢尾花数据集为例):

看到这里,你可能开始困惑了,没关系,往下看
对于逻辑回归来说,其余线性回归相同的是,他使用的也是\(wx+b\),只不过他最终的预测结果是使用sigmoid函数进行转换后的,sigmoid函数转换后,分为大于0.5和小于0.5两种,分别代表了两个类别。sigmoid可以参考各种激活偶函数
下面,看一下sigmoid函数:
接下来看一下他的图像:
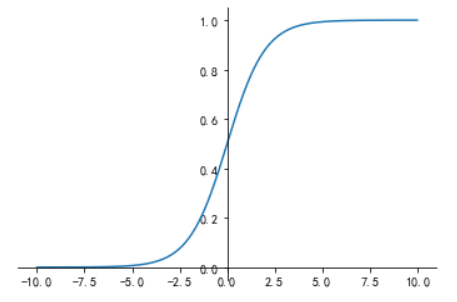
大家可以看到,sigmoid函数会将所有的数值转化到0和1之间,你可以将其简单的理解为该数据被判定为正样本的概率(所谓正样本就是标签为1的样本,负样本就是标签为0的样本),根据sigmoid函数,我们可以很明显的分析出当前数据应该是哪一个类别(大于0.5为正样本,小于0.5为负样例)
也就是说,逻辑回归就是在线性回归的基础上,在外层添加了sigmoid函数。
最常用的训练模型方法——梯度下降法
那么现在,是不是感觉逻辑回归很简单,很好理解了呢?或许有一些了解线性回归的小伙伴看到这里会有一些疑问了————线性回归在求解的时候用的是最小二乘法(详细可参考线性回归),那么逻辑回归也是使用最小二乘法么?
答案当然是否定的。 当我们在外层加入sigmoid函数后,使用类似于最小二乘法的思想进行求解、训练就会变得特别困难了。那么我们应该怎么办呢?
接下来,就有请机器学习中最常用的训练方式登场————梯度下降法。
什么是梯度下降法呢?在很多地方有这么一个解释:当你站在一座山上,你想要以最快的方式向下走,那么你每一步应该怎么选呢?是不是应该在走下一步的时候尽量选择下降最快的那一个方向呢。没错,这就是梯度下降法的基本思想:使得当前的w、b向着损失函数下降最快的方向走。
逻辑回归的损失函数
或许有的小伙伴又有疑问了:什么是损失函数被?那么接下来,我们就顺便说一下逻辑回归的损失函数吧。
所谓损失函数呢,其实就是代表当前模型预测的结果与真实结果的一个偏离程度。对于回归来说,损失函数主要表示的是当前模型预测的结果与真实结果的差的表示,如MSE(差的平方和的平均数)等;而对于分类问题来说,我们可以使用准确率(预测结果与真实结果相同的数据占所有数据的比例)。
而逻辑回归使用的损失函数就是这种的一个延伸,也就是交叉熵损失函数:
那么,咱们继续说梯度下降法。
首先,什么是梯度呢?
其实,梯度表示的就是我们上面说的对于当前点来说下山最快的那个方向,可以简单的理解为积分方向(大家只需要知道梯度大题是什么就可以了,如果有兴趣可以查一下百度,同样的,在高数上是有解释的, 再次就不进行过多的解释了)。
而对于传统的梯度下降法,我们通常是这样计算的:
其中\(\theta\)表示的是学习率,也就是用来控制每一次下降的大小的,简单说就是你下山时跨出的那一步的大小。
而通过这样的方式,我们可以找到损失函数尽量小甚至最小的点。
总结
通过上面的讲述,大家对逻辑回归是不是很熟悉了呢?
大家可以感受得到,逻辑回归还是很简单的,不就是在线性回归外层加了一个sigmoid函数么。真以为穿了衣服我就不认识你了啊!
当然了,大家也需要注意,逻辑回归的求解方式与线性回归传统的方式是不同的,虽然线性回归也可以使用梯度下降法,但是准确性是要比最小二乘法差的。
至于梯度下降法,也是有很多的,上面讲述的不过是最简单、最基础的一种,有兴趣的小伙伴可以参考一下各种梯度下降法
