python爬取4k小姐姐图片 人生苦短 我用python
老样子 先来几张图


前言
今天打开电脑看见自己用了好久的壁纸是时候换一个了,但苦于无良心的壁纸网站,然后我打开了知乎,搜素壁纸推荐,让我发现了这个宝藏壁纸网站wallhaven
这主页。。。。要是不爬一下感觉都对不起这主页,开整。
分析
这个壁纸主页和我之前爬取的壁纸网站有一些不同的地方,主要的不同就是这个壁纸网站图片并不是一页一页显示的,而是动态添加的,即当划到浏览器底部时,才会添加下面的图片。
这个问题看起来好像有一点棘手,但其实并不然,这时候打开咱们的google浏览器(不得不说 google浏览器 yyds),点击F12,向下滑动的时候发现这里突然发出一个xhr请求
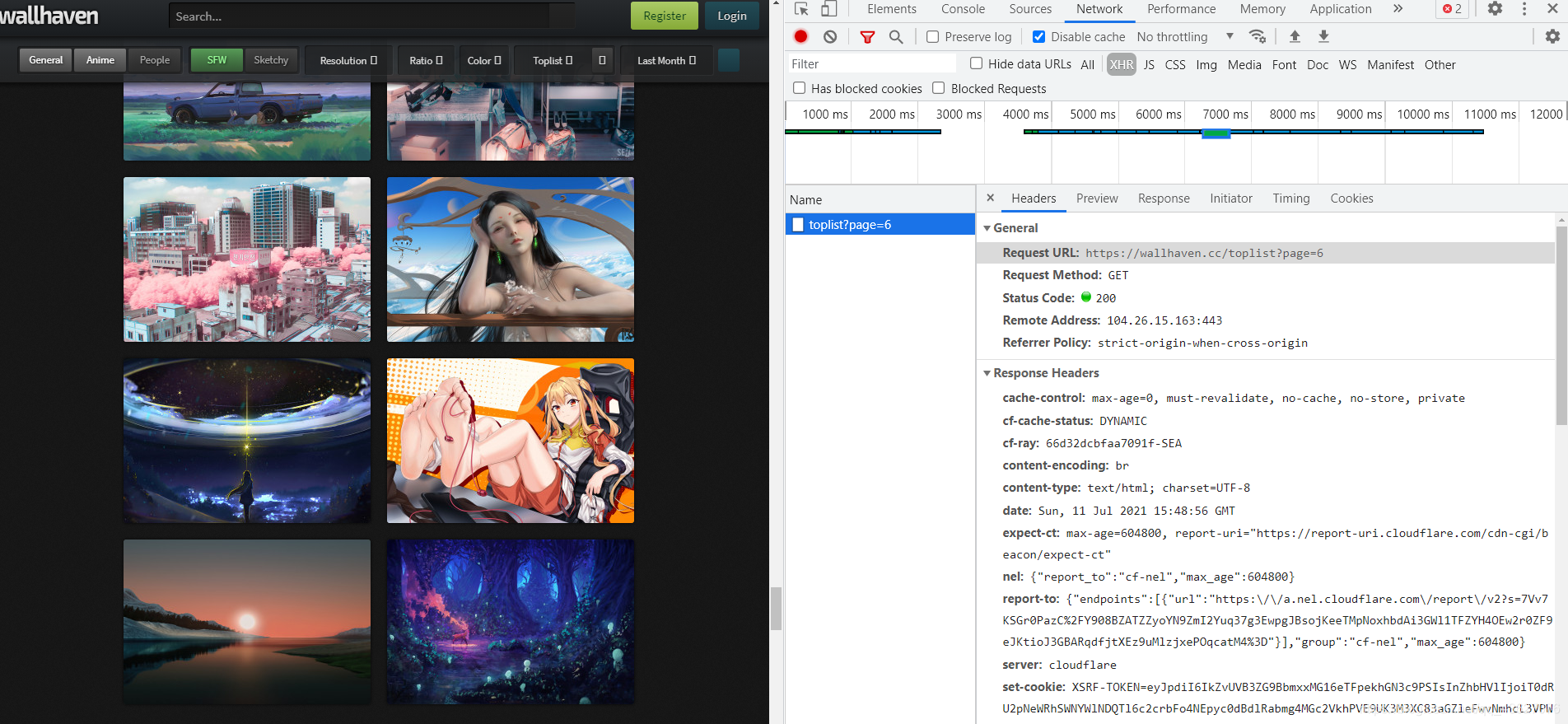
点进去一看,这就是自动拼接的内容呀,问题不就解决了吗
只需要修改该请求的page参数,就可以实现访问所有页的图片,我已经感受到了4k壁纸在向我招手,开撸代码

代码
拼接每一页图片的路径
这一步就是生成咱们要访问每一页图片的html的url,我看了一下,toplist里只有140页,所以只爬这140页的图片就可以了
for j in range(1, 141):
url = "https://wallhaven.cc/toplist?page="+str(j);
对每一页图片进行页面的解析,拿到图片详情页的url
这里就是对页面进行解析,目的是为了拿到图片详情页的url
def getHtmlUrl(url):
htmlurls = []
html = spider2.askURL(url)
bs = BeautifulSoup(html, "html.parser");
for item in bs.find_all('a', target="_blank"):
item = str(item)
htmlurl = re.findall(htmllink, item)
if len(htmlurl) != 0:
htmlurls.append(htmlurl[0])
return htmlurls
拿到图片的url和图片名
def getPicUrl(url):
html = spider2.askURL(url)
p = url.split('/')
bs = BeautifulSoup(html, "html.parser");
for item in bs.find_all('img', id="wallpaper"):
item = str(item)
picurl = re.findall(photolink, item)
return picurl[0], p[len(p) - 1]
这些步骤之后就可以开始图片的下载了。
当我信心满满的开始下载时,你看这速度。。。。。
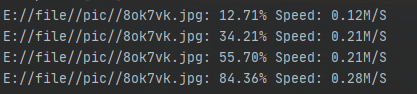
真是让人感到无语呀,,,

既然你下载速度比较慢,那我多开几个线程不过分吧(俺觉得不过分)
线程池 多线程下载
#初始化一个线程池 设置最大线程数为20
pool = ThreadPoolExecutor(max_workers=20)
# 生成一个文件下载的线程
pool.submit(FileDownload.downloadFile, 'E://file//pic//' + name + '.jpg', purl)
果然速度瞬间拉满,兄弟们可以把最大线程数再开大一点。
总结
这一次爬到的壁纸确实要比上一次好了太多了,4k的画质属实是杠杠的,这次没有写的特别详细,很多都是一带而过,如果爬虫基础不是特别好的兄弟们可以先去看看我之前的博客Python爬取美女图片 爬虫基础。需要完整源代码的私信我就好。
最后,卑微博主在线求一键三连!!!

成果展示
一部分我觉得很棒的壁纸,大家一起康康




 浙公网安备 33010602011771号
浙公网安备 33010602011771号