快来感受下回归的魅力 python实现logistic回归
前言
先来介绍下这个logistic回归
首先这玩意是干啥的
我个人的理解,logistic回归就是通过不断进行梯度下降,改变w和b,从而使得函数值与实际值平均差值越来越小
logistic回归使用的激活函数是
sigmoid函数,函数的图像和函数如下图所示
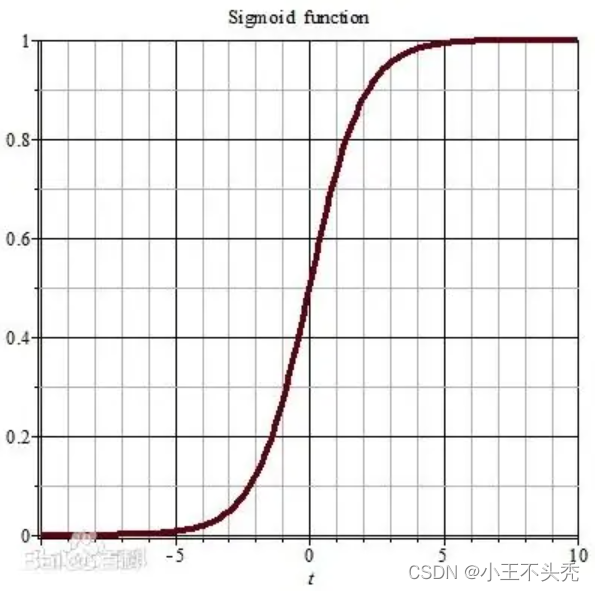
看这个函数图像就可以得出sigmoid的函数值永远在0,1之间,且当x趋于正无穷时,y趋向于1,x趋于负无穷时,y趋向于0
函数公式为
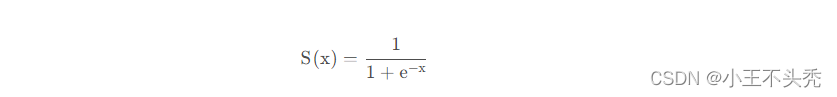
同时该回归使用的损失函数也与其他不同,如下图
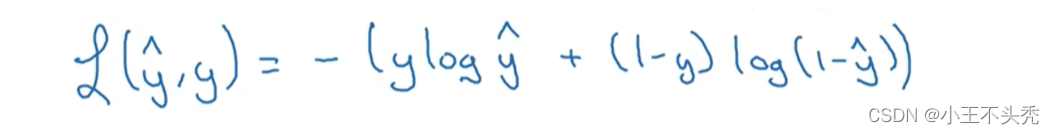
思想
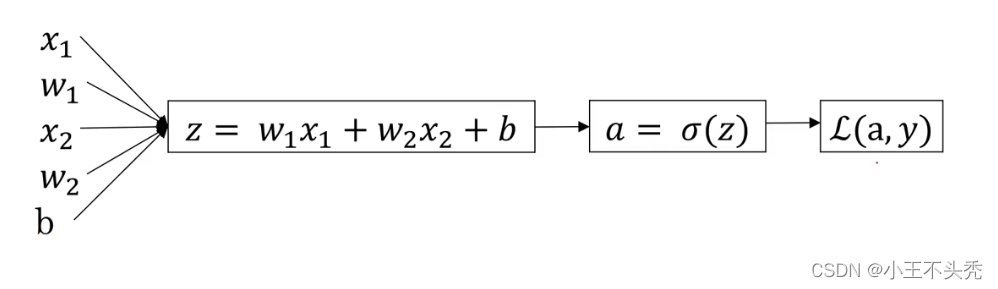
logsitic的计算过程如上图所示
正向传播有以下几步
- 第一步将输入的x值与w相乘,再加上b,完成线性函数的计算
- 第二步将z值代入激活函数中,也就是sigmoid函数中,计算出a值,a值就是我们预测的值
- 第三步将a值与实际值进行比较,计算出差值,也就是损失函数的值,损失函数就是上述提到的那个公式
通过以上三步,我们发现我们很快计算出预测值了,虽然不准,但确实块。

那么俺们怎么让这个预测值又快又准呢
这就要提到反向传播了
顾名思义,反向传播就是和正向传播的方向反着来
如下图红色箭头这种
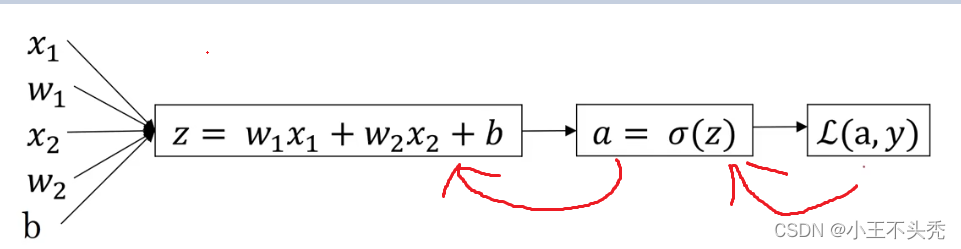
就是在计算出损失函数之后,计算出损失函数对w,b的偏导,然后就可以开始梯度下降了
来看下百度百科的解释
顾名思义,梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。
这就很清楚了
也就是我们目的就是损失函数对w,b求导,然后通过多次的梯度下降,从而达到使得损失函数最小的目的
对w,对b的求导公式就是直接链式求导就好
这里给出损失函数L对激活函数a的求导公式
这里a是预测值,y是实际值
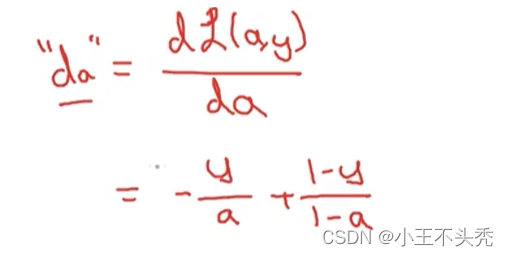
激活函数对z求导公式

Z对W的求导就不说了
然后就可以进行梯度下降了
梯度下降的公式如下
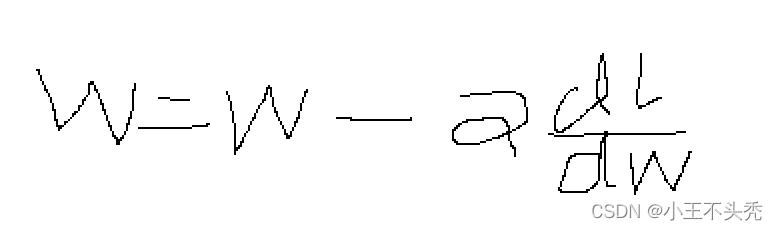
这里a就是学习率,也可以认为是梯度下降的步伐,a的值不应太小,也不应太大,太小会导致梯度下降处理时间太长,太大会导致出现错过极小值的情况
w就是参数值,dl/dw就是损失函数对w的偏导数
这样我们大概了解了之后,就可以开始写代码了
实现
这次是直接将回归用于如下图这种只有一个隐藏层的神经网络中

总共有三个x值,每一个x值对应一个w值
我们的目标就是通过修改w值和b值是得损失函数可以尽量小
那就开始写代码了
# -*- codeing = utf-8 -*-
# @Time : 2022/9/25 22:24
# @Author : xiaow
# @File : logistic_regression.py
# @Software : PyCharm
import numpy as np
# sigmod激活函数
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
# y是实际值 yhat是预测值
def singleLost(yhat, y):
a = y * np.log(yhat) + (1 - y) * np.log(1 - yhat)
return -a
# 这里的y是实际值,a是激活函数的值,也就是预测值
def lostDao(a, y):
return -(y / a) + (1 - y) / (1 - a)
# sigmod导数
def sigmodDao(z):
return sigmoid(z) * (1 - sigmoid(z))
def wdao(x):
return x;
def tidudown():
alpha = 0.1
# y值
y = [1, 0, 1, 1, 1, 1, 1, 1]
y = np.array(y).reshape(8, 1)
w = np.array([1, 1, 1])
w = w.reshape(3, 1)
b = 1
# x值
x = np.array([[1, 1, 1],
[1, 0, 1],
[1, 2, 1],
[1, 3, 3],
[1, 3, 5],
[1, 3, 6],
[1, 3, 0],
[1, 3, 9]])
prelost = 10000
for i in range(0, 100000):
z = np.dot(x, w) + b
a = sigmoid(z)
mlost = singleLost(a, y)
# 每一万次输出一个预测值
if i % 10000 == 9999:
print('now lost==============' + str(mlost))
print('last yhat===============' + str(a))
mlost = np.sum(mlost, axis=0) / mlost.shape[0]
r = mlost - prelost
if r > 0:
break
dl = lostDao(a, y)
ds = sigmodDao(z)
dw = wdao(x)
dall = dl * ds * dw
dall = np.sum(dall, axis=0) / dall.shape[0]
dall = dall.reshape(3, 1)
# 进行梯度下降
w = w - alpha * dall
if __name__ == '__main__':
tidudown()
这里看一下第一次计算时,损失函数的值和预测值
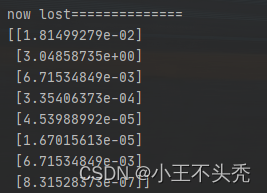
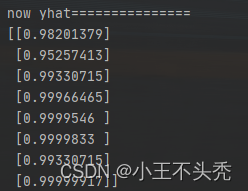
这里看一下第二个值,可以看出明显的不对,因为我们设置的第二个实际值是0,这直接两个极端了
看一下最后的结果
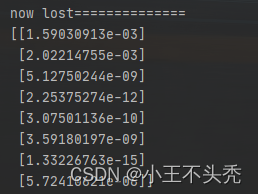
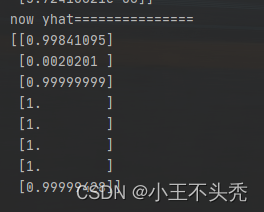
可以看出,误差明显减少,并且第二个值也趋于0了
这样整个过程就完成了
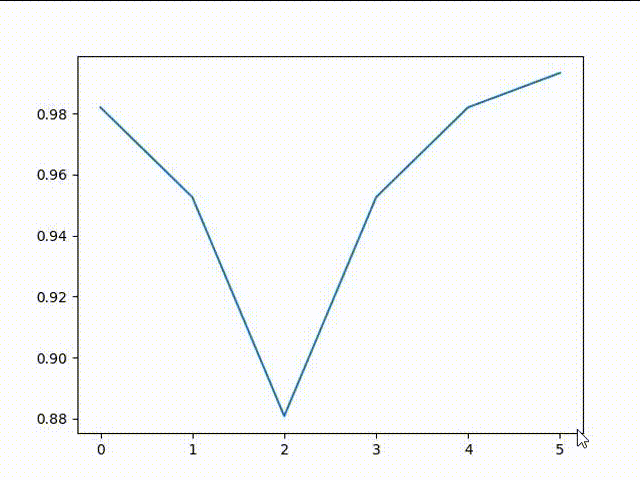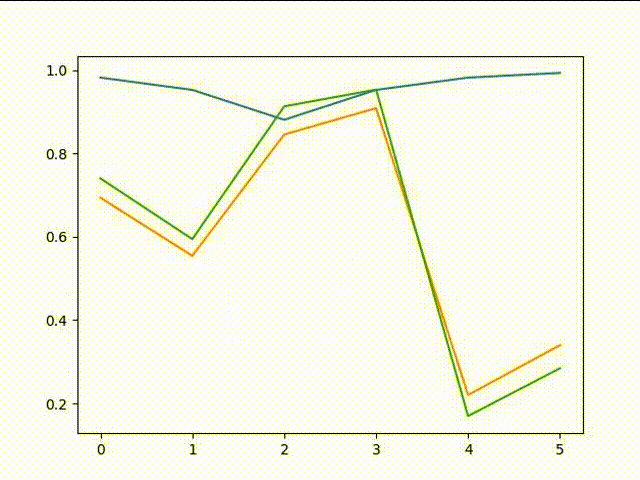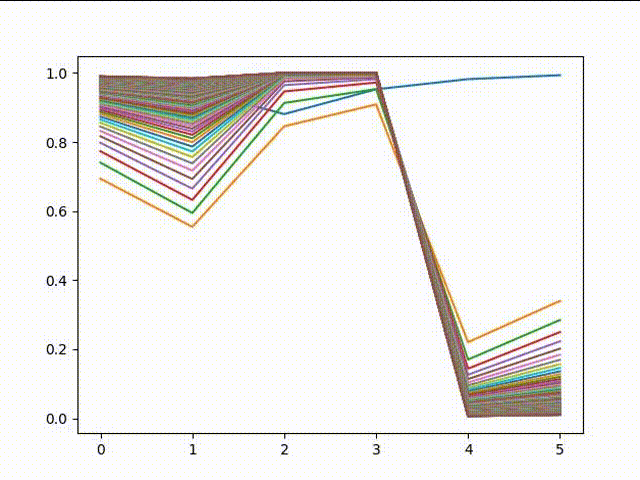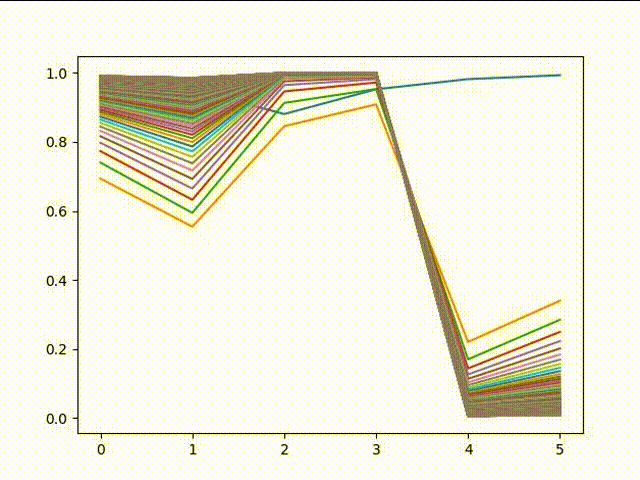
接下来来感受下,逐渐拟合的过程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号