python网络爬虫-解析网页(六)
解析网页
主要使用到3种方法提取网页中的数据,分别是正则表达式、beautifulsoup和lxml。
使用正则表达式解析网页
正则表达式是对字符串操作的逻辑公式
.代替任意字符 、 *匹配前0个或多个 、 + 匹配前1个或多个 、 ?前0次或1次 、
^开头 、 $ 结尾 、()匹配括号里面的表达式表示一组 、 []表示一组字符 、
\s匹配空白字符 、 \S 匹配非空白字符 、 \d[0-9] 、 \D[^0-9] 、
\w匹配字母数字[A-Z,a-z,0-9] 、 \W匹配不是字母数字
re.match方法:从字符串其实位置匹配一个模式,从起始位置匹配不了,match()就返回none
语法:re.match(pattern,string,flags=0)
pattern是正则表达式
string为要匹配的字符串
flags控制正则表达式的匹配方式,是否需要区分大小写、多行匹配
m = re.match('www', 'www.baidu.com')
re.search方法:扫描整个字符串,找到第一个成功的匹配内容
m_search = re.search('com', 'www.baidu.com')
re.findall:可以找到所有的匹配
m_findall = re.findall('[0-9+]', '123156 www.baidu.com')
使用BeautifulSoup解析网页
BeautifulSoup安装
pip install bs4
解析器
python标准库 BeautifulSoup(r.text, 'html.parser')
lxmlHTML BeautifulSoup(r.text, 'lxml')
lxmlXML BeautifulSoup(r.text, 'xml')
# CSS选择器
print(suop.select("div div header h1"))
print(suop.select("div>a"))
使用lxml解析网页
Xpath语法,是效率比较高的解析方法
lxml安装
pip install bs4
使用lxml
print("解析lxml")
# 解析lxml
html1 = html.etree.HTML(r.text)
title_list = html1.xpath('//h2[@class="dYInr JOzNE z2wCE"]/span/text()')
print(title_list)
提取网页源码数据也有三种方法,即XPath选择器、CSS选择器、BeautifulSoup的find()方法
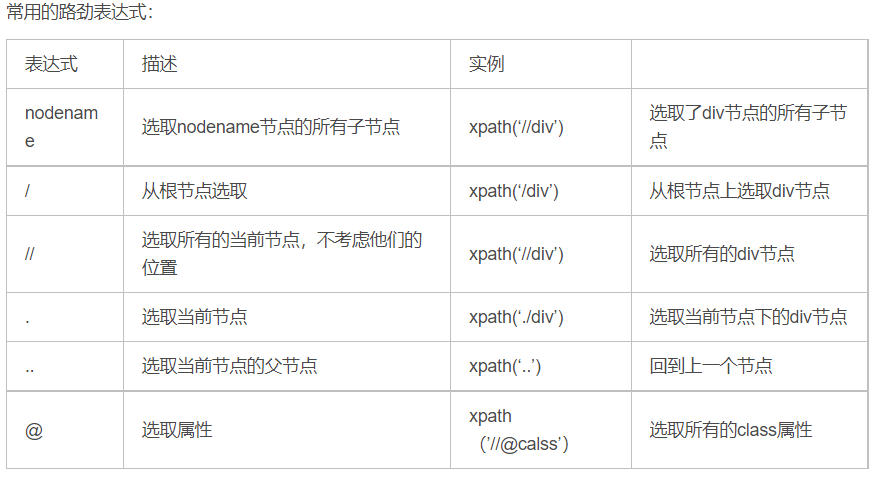
Xpath的选取方法
选取节点
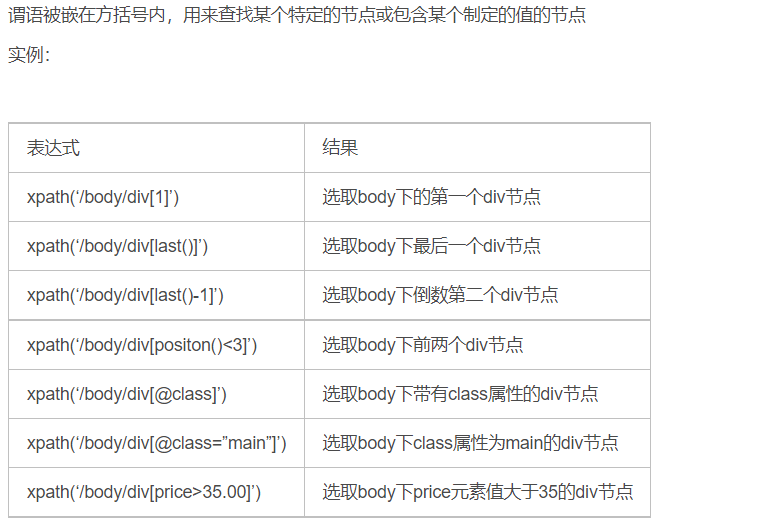
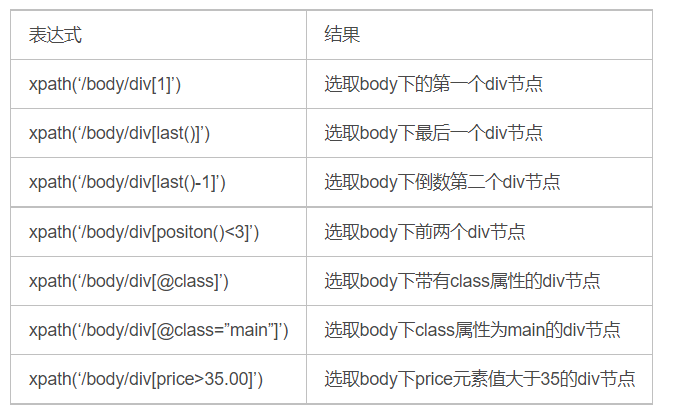
谓语
通配符

取多个路径

Xpath轴


功能函数

总结
推荐使用beautifulsoup的find方法,熟悉xpath的可以选择lxml,面对复杂的网页使用正则表达比较浪费时间
beautifulsoup爬虫时间:房屋价格数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36"
}
link = 'https://cs.anjuke.com/sale/?from=navigation'
r = requests.get(link, headers=headers)
soup = BeautifulSoup(r.text, 'html.parser')
hoouse_list = soup.find('div', property)
for house in hoouse_list:
house_name = house.find('h3', class_="property-content-title-name").text.strip()
house_price = house.find('span', class_="property-price-total-text").text.strip()
house_junjia = house.find('p', class_="property-price-average").text.strip()
house_jushi = house.find('p', class_="property-content-info-text property-content-info-attribute").text.strip()
house_mianji = house.find('p', class_="property-content-info-text").contents[0].text
house_loucen = house.find('p', class_="property-content-info-text").contents[1].text
print('楼层:', house_loucen)
print('面积:', house_mianji)
print('居室:', house_jushi)
print('均价:', house_junjia)
print('名称:', house_name)
print('价格:', house_price)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号