R-CNN
R-CNN
目标检测+深度学习开山之作
CVPR'14
paper:Rich feature hierarchies for accurate object detection and semantic segmentation
亮点
- 使用selection search(region proposal)生成候选框
- 使用AlexNet提取特征
- 使用SVM对CNN提取的特征进行分类
- 使用Bounding box回归出更加精确的框
网络结构
整个流程
- 输入一张图片(任意大小)
- 在图像上应用selection search方法得到2000个候选框
- 对候选框进行裁剪、缩放得到227*227大小的图像块
- 使用预训练好的AlexNet作为特征提取器
- 使用训练好的SVM作为分类器
- 使用NMS除去重复的框
- 使用训练好的bounding box 回归修正候选框
Selection search
划分为小块,对相邻的块计算图像相似度,合并相似的块,重复这个过程,最后得到候选框。
指标包括颜色、纹理、区域大小和区域的合适度
图像处理

填充后再裁剪
裁剪后再填充
直接缩放到目标尺寸
论文对比发现直接缩放到目标尺寸+在图像周围填充16个像素(基于上下文)效果比较好。(也可以根据原始图像的像素决定填充的像素数)
特征提取
使用fine-tune,保留AlexNet前五层。AlexNet在大型的数据集上训练。
分类器
使用SVM*预测种类数量个分类器。
NMS
按照得分排序,除去和最大得分框IOU大于阈值的框,不断筛选。
预测框修正
附录C
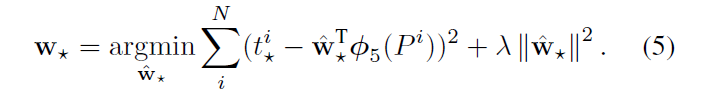
输入\((G, P)\), \(G\)是GT bounding box,\(P\)是predict bounding box。
\(P\)除去了那些和任何GT都不沾边的框,这些框拿来训练没意义。
\(t^i_*\)是由\(G\)和\(P\)计算得到的,包括中心点偏移量和长宽的缩放比例。
hard negative mining
主要由样本量引起。
方法:把难以训练的样本放入训练集中进行训练。
在文中特征提取部分和分类器部分使用有点区别,fine-tunning阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松: IoU>0.5的建议框为正样本,否则为负样本; SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本。
。
缺点
select search只能在CPU上处理,速度慢
每次输入2000+个候选框,有大量的重复计算,速度很慢
特征提取、分类、边框回归是三个部分分别训练
需要额外的存储空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号