CSPNet
CSPNet
paper:CSPNET: A NEW BACKBONE THAT CAN ENHANCE LEARNING CAPABILITY OF CNN
Abstract
作者将模型推理过程需要庞大的计算量归因于网络优化过程中重复的梯度计算。
CSPNet整合了网络从开始到结束阶段的所有特征图,节约了大概20%的计算量,并且保持相当高的精度。
Introduction
提出CSPNet,实现更加丰富的梯度组合并且减少计算量。CSPNet将基础层的特征图划分成两部分,然后通过提出的跨阶段分层结构进行合并。
论文的主要内容是分割梯度流,通过不同的网络路径传播。
针对基于CSPNet的目标检测网络,主要关注以下几个问题:
- 加强CNN的学习能力:CNN在轻量化后,精度会大大降低。作者想通过加强CNN的学习能力,使其轻量化的同时保持足够的准确性。应用CSPNet之后,可以将计算量减少10%~20%。
- 移除计算瓶颈:过高的计算瓶颈会导致更多的计算周期来完成推理过程,或者一些算力单元经常闲置。因此作者通过均匀分配CNN中各层的计算量,这样可以有效提升各个计算单元的利用率,从而减少不必要的能耗。
- 减少内存占用:论文特征金字塔生成特征图的过程中采用交叉通道池化压缩特征图,这样减少内存占用。适合部署到边缘设备上(内存小)。
成果:
- 50% COCO AP50,109FPS,GTX 1080ti
- 40% COCO AP50,52FPS,Core i9-9900K
- 42% COCO AP50,49fps,Jetson TX2
Method
Cross Stage Partial Network

DenseNet的正向传播:
反向传播过程
Cross Stage Partial DenseNet
上图b部分可知,第一个Dense Layer分为了两个部分\([x_0', x_0'']\)。其中一部分随着Dense Layer路径传播,另外一部分直接和Partial Dense Block的输出\(X_T\)拼接,再经过一个卷积操作得到最后的输出\(X_U\)。
正向传播:
反向传播:
作者提到CSPNet通过这个操作将\(x_0'\)类似于残差链接一样,直接concatenate到最后的输出特征矩阵上去,减少了计算量。
Partial Dense Block
设计partial dense block的目的:
- 增加梯度传播路径:划分+合并。论文中提到的Because of the cross-stage strategy, one can alleviate the disadvantages caused by using explicit feature map copy for concatenation,我并没有理解到这个缺点指的是什么,可能需要去看一下DenseNet原论文。
- 平衡每一层的计算量:base layer(Dense Block的第一层)一般通道数远大于Dense Layer生成的中间特征矩阵的通道数,通过只在Dense Clock中引入base layer一半通道的特征矩阵,来减少Dense Block的计算瓶颈。
- 减少内存流量:base layer的通道数为\(c\),中间生成的特征矩阵通道数为\(b\),dense layer数量为\(m\),CIO(可以理解为整个Dense Block所有特征矩阵大小的和)为\((c\times m)+((m+m^2)\times d)/2\),CSP版本的CIO为\(((c\times m)+(m^2+m)\times d)/2\)。由于\(c\)远大于\(m\)和\(d\),因此几乎减少一半的内存占用。
Partial Transition Layer
该层通过截断梯度信息流来阻止不同的层学习重复的梯度信息,也称作分层特征模糊机制。
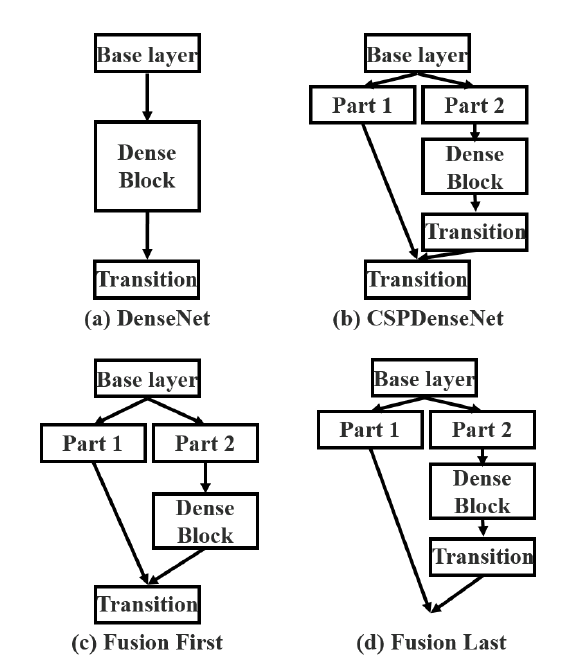
比较\((c)\)、\((d)\)两个结构:
\((c)\):先拼接再卷积。梯度信息重复使用。
\((d)\):先卷积再拼接。减少梯度信息复用。
Exact Fusion Model
Looking Exactly to predict perfectly: 论文提出了EFM模型,为每个锚框捕捉合适的视野,提高单阶段目标检测算法的检测精度。对于图像分割来说,像素层的标签不包含全局信息,因此需要考虑使用更大的块来提取信息。对于图像分类和目标检测,从图像层或者bounding box层提取的信息可能会模糊(分辨率变化+下采样)。CNN从图像层分析会导致注意力分散,这也是两阶段目标检测效果更好的原因。
Aggregate Feature Pyramid:EFM比最初的特征金字塔具有更好的特征聚合能力。每个bounding box 分配一个anchor
Balance Computation:特征金字塔得到的特征图十分巨大,使用Maxout压缩特征图。
实验
略。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号