
1. 删除文件:
def delete_file(file_name):
if os.path.exists(file_name):
os.remove(file_name)
print('临时文件 %s 已被删除' % file_name)
else:
pass
print('要删除的临时文件 %s 不存在,可忽略此信息.' % file_name)
2. 判断文件是否存在:
import os
if not os.path.exists(file_name):
print('输入的文件名不存在,请检查后重新输入')
exit()
else:
print('\n')
print('您输入的文件名是', file_name)
3. csv文件删除重复行:
import pandas as pd
# 去除csv文件中内容相同的行,只保留第一行
df = pd.read_csv(outFile, engine='python')
data = df.drop_duplicates(subset=None, keep='last', inplace=False) # subset用来指特定的列,默认为所有列,keep=first,去重保留第一行
data.to_csv(outFile', encoding='utf-8', index=False) # index=False 不加行索引号
参数解释:
subset: 列名,可选,默认为None,‘None’是指选择所有列,即所有列的值都相同我才认为这两行是重复的,也可以自定义为其中一部分列变量名,比如subset=['name','sex','age']。
keep: {‘first’, ‘last’, False}, 默认值 ‘first’ ,first: 保留第一次出现的重复行,删除后面的重复行。last: 删除重复项,除了最后一次出现。False: 删除所有重复项。
inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。( inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。
4. 读取和写入csv文件:
先介绍读取csv文件:
如何用Python像操作Excel一样提取其中的一列,即一个字段,利用Python自带的csv模块,有两种方法可以实现:
第一种方法使用reader函数,接收一个可迭代的对象(比如csv文件),能返回一个生成器,列表格式,就可以从其中解析出csv的内容(以行为单位):
with open(file_name, 'r', encoding='utf-8-sig') as f: 之诶接
reader = csv.reader(f)
for row in reader:
msisdn = row[0]
或者下面这种形式
with open("test.csv", "r", encoding = "utf-8") as f:
reader = csv.reader(f)
rows = [row for row in reader]
print(rows)
#读取第二列的内容
with open("test.csv", "r", encoding = "utf-8") as f:
reader = csv.reader(f)
column = [row[1] for row in reader]
或者:
import csv
with open('1.csv') as f:
reader = csv.reader(f)
for row in reader:
print(row)

第二种方法是使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,
而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
with open("test.csv", "r", encoding = "utf-8") as f:
reader = csv.DictReader(f)
column = [row for row in reader]
print(column)
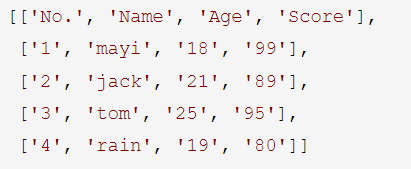
得到:
[{'No.': '1', 'Age': '18', 'Score': '99', 'Name': 'mayi'},
{'No.': '2', 'Age': '21', 'Score': '89', 'Name': 'jack'},
{'No.': '3', 'Age': '25', 'Score': '95', 'Name': 'tom'},
{'No.': '4', 'Age': '19', 'Score': '80', 'Name': 'rain'}]
再介绍写入csv文件:
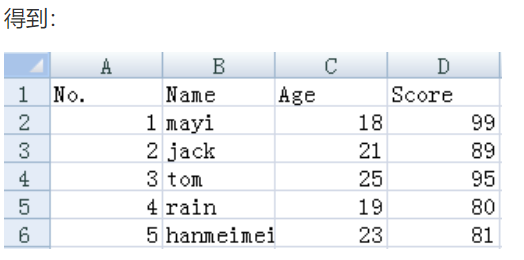
#写:追加
row = ['5', 'hanmeimei', '23', '81'] # 以列表形式写入csv
out = open("test.csv", "a", newline = "")
csv_writer = csv.writer(out, dialect = "excel")
csv_writer.writerow(row)
写入csv文件的其它思路:
# open 打开文件有多种模式,下面是常见的4种
# r:读数据,默认模式
# w:写数据,如果已有数据则会先清空
# a:向文件末尾追加数据
# x : 写数据,如果文件已存在则失败
# 第2至4种模式如果第一个参数指定的文件不存在,则会先创建一个空文件
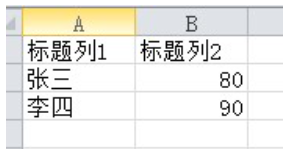
with open('1.csv', 'w', newline='') as f:
head = ['标题列1', '标题列2']
rows = [
['张三', 80],
['李四', 90]
]
writer = csv.writer(f)
#写入一行数据
writer.writerow(head)
#写入多行数据
writer.writerows(rows)
或者:
import csv
with open('1.csv', 'w', newline='') as f:
head = ['标题列1', '标题列2']
rows = [
{'标题列1': '张三', '标题列2' :80},
{'标题列1': '李四', '标题列2' :90}
]
writer = csv.DictWriter(f,head)
writer.writeheader()
writer.writerows(rows)
5. 删除文件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号