


来自 https://www.cnblogs.com/arnoldlu/p/7553978.html, 感谢作者。
数据分析之---Python可视化工具
1. 数据分析基本流程
作为非专业的数据分析人员,在平时的工作中也会遇到一些任务:需要对大量进行分析,然后得出结果,解决问题。
所以了解基本的数据分析流程,数据分析手段对于提高工作效率还是非常有帮助的。
首先都是存在一个要解决的问题,主要问题和预期分析目标,简单来讲就是对问题进行定义。
然后才是开始收集数据、数据清洗、数据建模、数据展现、优化和重复,最后是报告撰写。
1. 明确分析目的和思路:在进行数据分析之前,首先考虑的应该是“为什么要展开数据分析?我要解决什么问题?从哪些角度分析数据才系统?用哪个分析方法最有效?”,而不是“这此分析需要出多少页报告?打算用高级分析算法试试…”这样的思维方式。只有明确了分析目的和思路,数据分析的方向才不会跑偏,才能得出有意义的结论。
2. 数据收集:明确了分析目的,接下来就是开工收集数据了。数据来源有很多,但是确保数据可信度等很重要。
3. 数据处理:包括数据清洗、转换、分组等处理方法。我们拿到的数据,通常情况下是不可直接使用的,比如数据有丢失、重复、有录入错误或存在多余维度等情况。只有经过处理后的数据才可以使用。提高数据质量,定义分析需要的数据结构。
4.数据分析:在明确分析思路的前提下,选用适合的分析方法对处理后的数据进行分析。创建不同数据模型,然后不停的优化和重复。
5.数据展现:将分析结果用图表来展现。所以数据展现阶段,你需要思考“采用这个图表,能否清晰的表达出分析结果?我想表达的观点是否完全展示出来了?”这是本文重点关注的点。
6.报告撰写:将数据分析的整个过程和结果,以书面的形式向他人说明。需要将分析目的、数据来源、分析过程、分析结论和建议等内容展现在报告中。
1.1 常用统计方法
除了可视化展示数据分析结果,一些统计描述也很有必要。因此,罗列一些简单的统计性描述概念。
使用Numpy
平均值、最大值、最小值、求和
标准误差:表示样本平均数和总体平均数的变异程度,可以用来反映结果精密度。
标准差(均方差):计算一组数据偏离均值的平均幅度,不管这组数据是样本数据还是总体数据
方差:在概率论和统计方差衡量随机变量或一组数据时离散程度的度量
中位数:对于有限的数集,可以通过把所有观察值高低排序后找出正中间的一个作为中位数。
众数:在统计分布上具有明显集中趋势点的数值,代表数据的一般水平(众数可以不存在或多于一个)

import numpy as np from scipy.stats import mode array = np.array([1, 3, 4, 23, 565, 1, -8, 123, 111, 54, 45.0, 3, 3]) print '求和:', array.sum() print '最大值:', array.max() print '最小值:', array.min() print '条数:', array.size print '标准差:', array.std()---------------偏离平均值的幅度 print '平均值:', array.mean() print '中位数:', np.median(array) print '方差:', np.var(array)---------------这组数据离散程度 print '众数:', mode(array).mode, mode(array).count
结果如下:
求和: 928.0 最大值: 565.0 最小值: -8.0 条数: 13 标准差: 148.326323439 平均值: 71.3846153846 中位数: 4.0 方差: 22000.6982249 众数: [ 3.] [3]
关于NumPy和SciPy常用统计方法,参考《使用Python进行描述性统计》。
1.2 常用图表
题外话《如何快速成为数据分析师?》,是一个不错的科普。包括数据可视化、分析思维训练、数据库学习、统计知识、数据分析常用语言Python/R,以及业务也即需要分析的对象学习。
数据可视化是分析数据的优秀工具,好的可视化是会讲故事的。
下面这张图来源于:《数据可视化:你想知道的经典图表全在这》。他根据你想要展示的内容进行划分,只要对你的展示内容分门别类就可以找到合适的图表。
维度:数据分析本质是各种维度的组合,维度可以用时间、数值、文本等表示。
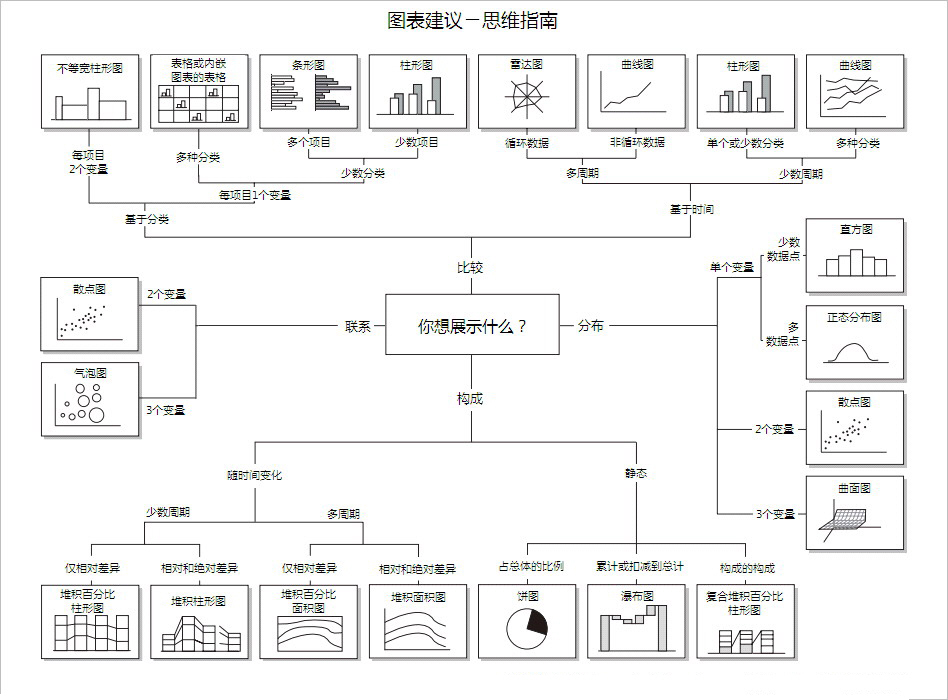
数据通常包含五种关系:构成、比较、趋势、分布及联系。
参照:《如何选择正确的图表类型》
构成:关注每个部分所占整体的百分比,适用饼图。
比较:展示事物的排列顺序,首选条图。
趋势:常见的时间序列关系,适用线图能更好的展示变化。
分布:关心各数值范围包含多少项目,适用柱图。
联系:查看两个变量之间关系,适用气泡图。

2. Python可视化
Python可视化工具繁多,但没有一个能覆盖所有需求。所以需要针对需求,决定使用那些工具更合适。
《Overview of Python Visualization Tools》对Python下的可视化工具进行了介绍和对比,包括matplotlib、Pandas、Seaborn、ggplot、Bokeh、pygal、Plotly。
下面重点了解一下matplotlib、Pandas和Bokeh。
2.1 matplotlib
根据上图《如何选择图表的类型?》,将各种图表在matplotlib中对应函数列出。
2.1.1 趋势
线图(很多日期) & 多线图(多种分类)
#API: http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.plot
import matplotlib.pyplot as plt import numpy as np import pandas as pd fig, ax = plt.subplots() plt.subplot(4, 1, 1) data = pd.DataFrame(np.random.randn(1000, 4), columns=['x', 'y', 'z', 't']) index = range(len(data)) plt.plot(index, data['x'].cumsum(), label='xxx') plt.subplot(4, 1, 2) plt.plot(index, data.loc[:, ['x', 'y']].cumsum()) plt.subplot(4, 1, 3) plt.plot(index, data.loc[:, ['x', 'y', 'z']].cumsum()) plt.subplot(4, 1, 4) plt.plot(index, data.cumsum()) fig.set_size_inches(40, 32) plt.show()

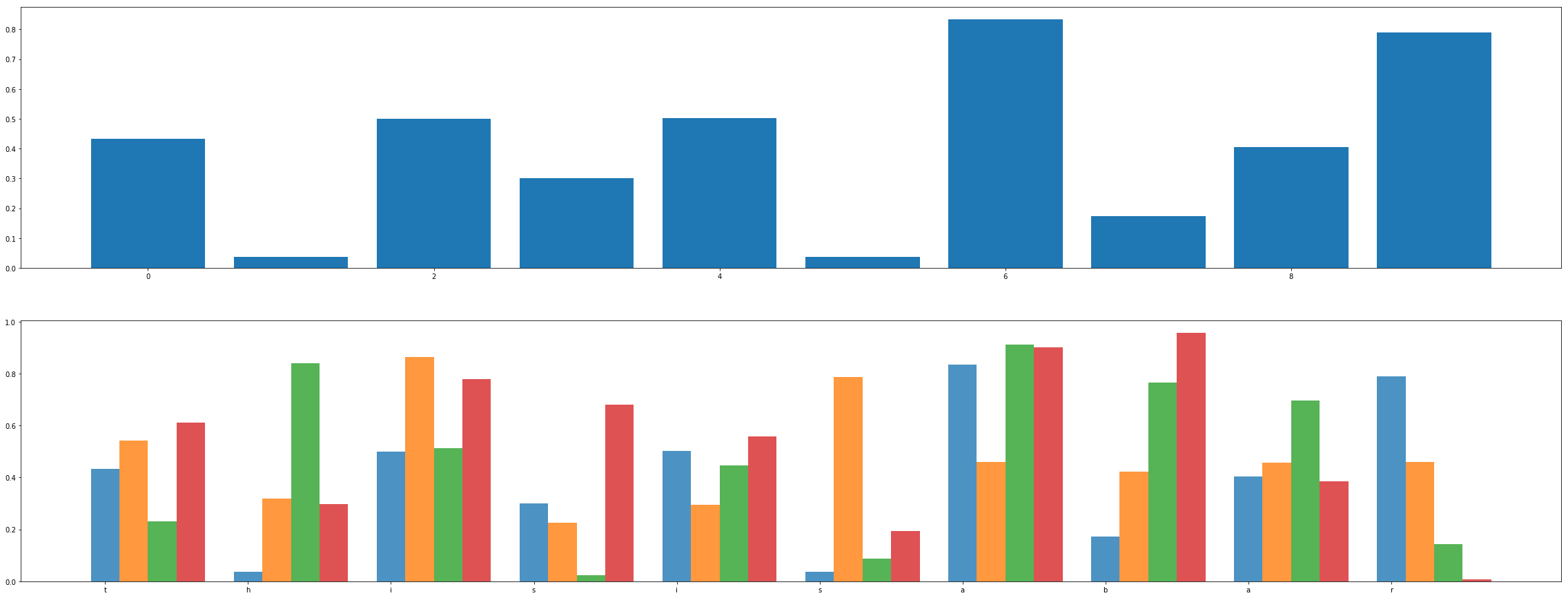
柱图(少数分类)
#API: http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.bar
import matplotlib.pyplot as plt import pandas as pd import numpy as np opacity = 0.8 data = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd']) fig, ax = plt.subplots() index = range(len(data)) plt.subplot(4, 1, 1) plt.bar(index, data['a']) plt.subplot(4, 1, 2) plt.bar(index, data['a'], alpha=opacity, width=0.2) plt.bar([i+0.2 for i in index], data['b'], alpha=opacity, width=0.2) plt.bar([i+0.4 for i in index], data['c'], alpha=opacity, width=0.2) plt.bar([i+0.6 for i in index], data['d'], alpha=opacity, width=0.2) fig.set_size_inches(40, 32) plt.xticks(index, list('thisisabar')) plt.show()
2.1.2 比较
表格(许多项目)
import matplotlib.pyplot as plt
import numpy as np
col_labels = ['col1', 'col2', 'col3']
row_labels = ['row1', 'row2', 'row3']
row_colors = ['red', 'gold', 'green']
table_vals = np.random.randn(3, 3)
fig, ax = plt.subplots()
my_table = ax.table(cellText = table_vals,
colWidths = [0.5]*3,
rowLabels=row_labels,
colLabels=col_labels,
rowColours=row_colors,
colColours=row_colors,
loc='center',
animated = True)
#ax.xaxis.set_visible(False)
#ax.yaxis.set_visible(False)
ax.axis('off')
fig.set_size_inches(10, 10)
plt.show()

条图(一种分类)
堆叠条图(2种以上分类)
2.1.3 联系
散点图(2维) & 气泡图(3维)
散点图和气泡图的区别就在于气泡图多了一维数据,是散点具备了不同的半径。
#API: http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.scatter
import matplotlib.pyplot as plt import numpy as np import pandas as pd N = 100 fig, ax = plt.subplots() data = pd.DataFrame(np.random.rand(N, 3)*100, columns=['x', 'y', 'r']) data['r'] = np.pi*(np.pi*data['r']/20)**2 #s is area colors = 2*np.pi*data['x'] #colors is value of circumference plt.subplot(3, 1, 1) plt.scatter(data['x'], data['y'], c=colors, s=np.pi*5**2) plt.subplot(3, 1, 2) plt.scatter(data['x'], data['y'], c=colors, s=data['r']) fig.set_size_inches(10, 30) plt.show()

雷达图(多维)
2.1.4 构成
100%堆积柱图(相对差异)
堆叠柱图(绝对差异)
堆积百分比面积图(相对差异)
堆积面积图(相对绝对差异)
饼图(占整体比例)
#API Introduction: http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.pie import matplotlib.pyplot as plt labels = 'A', 'B', 'C', 'D', 'E', 'F', 'G' sizes = [20, 45, 68, 98, 60, 28, 99] explode = (0, 0.1, 0, 0, 0, 0, 0) fig, ax = plt.subplots() ax.pie(sizes, explode=explode, labels=labels, autopct='%.2f%%', shadow=True, startangle=90) fig.set_size_inches(8, 8) plt.show()

漏斗图(次序部分与整体)
金字塔图(次序部分与整体)
2.1.5 分布/地理
地图(地理分布)
柱图(1维)
散点图(2维)
气泡图(3维)
曲面图(3维)
2.1.6 其他
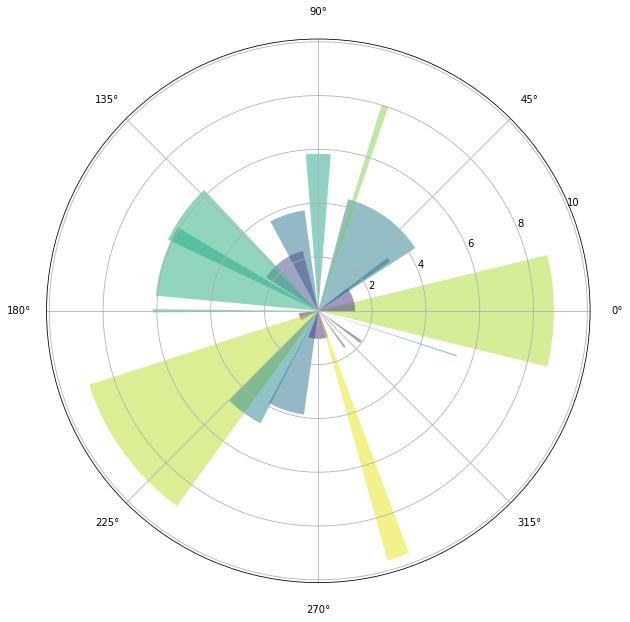
极坐标图
有三种:线状极坐标图/柱状极坐标图/气泡极坐标。
import matplotlib.pyplot as plt import matplotlib import numpy as np import pandas as pd fig, ax = plt.subplots() ax = plt.subplot(111, projection='polar') r = np.arange(0, 2, 0.01) theta = 2*np.pi*r plt.plot(theta, r) ax.set_rmax(2) ax.set_rticks(np.arange(0, 2, 0.5)) ax.set_rlabel_position(-22.5) ax.grid(True) fig.set_size_inches(10, 10) plt.show()

import numpy as np
import matplotlib.pyplot as plt
# Compute pie slices
N = 20
fig, ax = plt.subplots()
theta = np.linspace(0.0, 2 * np.pi, N, endpoint=False)
radii = 10 * np.random.rand(N)
width = np.pi / 4 * np.random.rand(N)
ax = plt.subplot(111, projection='polar')
bars = ax.bar(theta, radii, width=width, bottom=0.0)
# Use custom colors and opacity
for r, bar in zip(radii, bars):
bar.set_facecolor(plt.cm.viridis(r / 10.))
bar.set_alpha(0.5)
fig.set_size_inches(10 , 10)
plt.show()
import matplotlib.pyplot as plt import numpy as np # Compute areas and colors N = 150 fig, ax = plt.subplots() r = 2 * np.random.rand(N) theta = 2 * np.pi * np.random.rand(N) area = 200 * r**2 colors = theta ax = plt.subplot(111, projection='polar') c = ax.scatter(theta, r, c=colors, s=area, cmap='hsv', alpha=0.75) fig.set_size_inches(10, 10) plt.show()

2.2 Bokeh
2.3 Pandas
pandas基于NumPy的一种Python工具包,主要是为了解决数据分析任务而创建。
Pandas提供了大量库和标准数据模型,高效地操作大型数据集所需的工具。Pandas主要包括三种数据结构:
Series,一维数组,与NumPy中的一维array类似。TimeSeries,以时间为索引的Series。
DataFrame,二维表格型数据结构,可以将DataFrame理解为Series的容器。
Panel,三维数组,可以理解为DataFrame的容器。
关于Pandas有一个简要的入门《10 Minutes to pandas》,主要包括创建pandas数据,查看数据,对数据操作(统计等),Merge/Grouping/Reshaping/Time Series/Categoricals/Plotting,以及数据的I/O接口。
更详细的入门在《Tutorials》。
可视化相关内容在《Virtualization》,pandas的可视化基于matplotlib,包括基本plot/Bar/Histograms/Box/Area/Scatter/Hexagonal Bin/Pie。
《API Reference》提供了所有pandas的objects/functions/methods的介绍,在这里可以获取每个函数的使用方法。
还有很多对plot设置的Plot Formatting以及附加的Plotting工具。
在pandas_test中对pandas基本数据处理和可视化进行了简单测试。
2.3.1 pandas数据构造
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
s = pd.Series([1, 3, 5, np.nan, 6, 8]) #一维数据构造
s_list = s.tolist() #从series到list
s_series = pd.Series(s_list) #从list到series
print '\nSeries:\n', s
print '\nSeries item:\n', s[2]
print '\nSeries to list:\n', s_list
print '\nList to series:\n', s_series
dates = pd.date_range('20171001', periods=7)
#二维数据构造
df = pd.DataFrame(np.random.randn(7, 4)*100, index=dates, columns=list('ABCD'), dtype='uint32')
df_list = np.array(df).tolist()
df_dataframe = pd.DataFrame(df_list, columns=['a', 'b', 'c', 'd'])
df_list.extend
print '\nDataFrame:\n', df
print '\nDataFrame to list:\n', df_list
print '\nList to DataFrame:\n',df_dataframe
print '\nDataFrame row:\n', df_dataframe.iloc[3]
print '\nDataFrame column:\n', df_dataframe['d']
print '\nHex format:'
for i in range(len(df_dataframe)):
print '0x%0.8x, 0x%0.8x, 0x%0.8x, 0x%0.8x' % (df_dataframe.iloc[i]['a'],
df_dataframe.iloc[i]['b'],
df_dataframe.iloc[i]['c'],
df_dataframe.iloc[i]['d'])
'''
print 'head\n', df.head(3)
print 'tail\n', df.tail(3)
print 'index\n', df.index
print 'columns\n', df.columns
print 'values\n', df.values
print 'sort_index\n', df.sort_index(axis=1, ascending=False)
print 'sort_values\n', df.sort_values(by='B', ascending=False)
print df['C']
print df[0:3]
'''
#二维数据构造
df2 = pd.DataFrame({'A':1.,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1, index=list(range(4)), dtype='float32'),
'D':np.array([3]*4, dtype='int32'),
'E':pd.Categorical(['test', 'train', 'test', 'train']),
'F':'foo'})
2.3.2 pandas可视化图表
可视化图表主要有基本plot/bar/histograms/box/area/scatter/hexagonal/pie。
准备好数据,使用起来都非常简单,xxx.plot()/xxx.plot.bar()/xxx.plot.pie()形式。
